




- @thesky123456
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
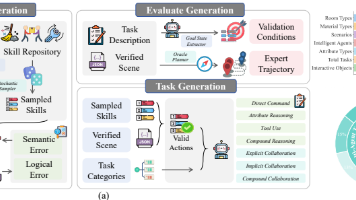
论文《OMNIEAR: BENCHMARKING AGENT REASONING IN EMBODIED TASKS》提出首个评估具身智能体物理推理能力的基准。针对现有基准在连续物理属性建模、动态工具获取和隐式协作识别方面的不足,该研究构建了包含1,500个场景的三层次评估体系,涵盖单代理基础指令到多代理复合协作任务。实验发现:大模型在隐式推理任务中性能骤降29%,72B参数后出现性能饱和;多代理
艾伟达以数字设计前端为突破口,深度融合了新一代EDA核心算法、机器学习与云计算等前沿科技,经过多年的技术积累和打磨,成功推出了自主研发的数字芯片设计逻辑综合系统、RTL布局规划系统,并积极推动全套数字设计全流程系统的开发,以及IP(知识产权)和设计服务的提供。在当前全球EDA市场被欧美三巨头垄断的背景下,艾伟达凭借其在数字设计前端领域的深厚积累和创新突破,成功研发出了一系列可与欧美顶尖EDA软件相

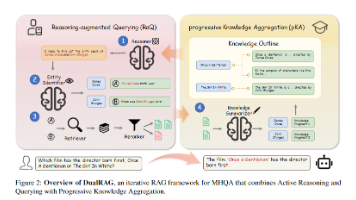
天津大学团队提出DualRAG框架,针对多跳问答任务中迭代式RAG方法的三大痛点(被动识别知识缺口、检索针对性不足、信息组织混乱),创新性地设计了"推理增强查询(RaQ)+渐进式知识聚合(pKA)"双流程系统。RaQ通过主动推理识别知识需求并生成靶向查询,pKA围绕实体结构化整合检索结果形成知识大纲。实验表明,该框架在多个数据集上性能接近Oracle上限,且通过专用数据集微调可
《ReMA:基于多智能体强化学习的LLM元思考训练框架》摘要 OPPO AI团队提出的ReMA框架创新性地通过双智能体架构培养大语言模型的元思考能力。该框架将推理过程分解为高层策略制定与底层任务执行,采用分层强化学习实现协同优化。实验表明,ReMA在数学推理等任务上实现6.68%的平均提升,计算效率提升84.6%,并在跨领域任务中展现出卓越的泛化能力。该研究开源了包含模型权重、训练代码和16万条轨
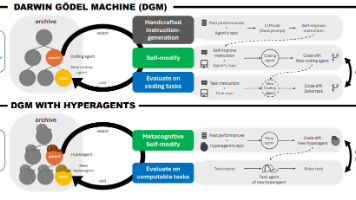
本文提出"DGM-Hyperagents"框架,通过整合任务智能体与可自修改的元智能体,实现跨领域的元认知自改进。实验表明,该框架在编码、论文评审等四类任务中均显著提升性能,并能实现元能力的跨领域迁移和累积优化。相比传统方法,DGM-H突破了固定元机制限制,展现出自主演化高级元认知策略的能力,为通用自加速AI系统提供了新范式。研究同时指出了安全挑战和当前局限,为未来研究指明了方
本文提出多模态检索增强生成规划(MRAGPlanning)新任务,旨在解决现有MRAG系统检索策略僵化、查询表述不足等问题。创新性地设计了CogPlanner框架,通过迭代式查询重构与动态检索策略选择,实现自适应信息获取。该框架采用插件式设计,支持并行/顺序建模,可无缝集成现有系统。研究还构建了CogBench基准数据集(含5718个样本),支持细粒度评估。实验表明,CogPlanner较基线方法
北京大学彭宇新教授团队在《Journal of Computer Science and Technology》发表综述论文,针对跨模态检索(CMR)研究存在的分类体系过时、细粒度任务覆盖不足等问题,提出以"检索粒度"为核心的统一分类框架。该框架首次将CMR明确划分为粗粒度(CCMR)和细粒度(FCMR)检索,系统梳理了两类任务的主流方法、数据集及性能对比,并重点分析了视觉-语
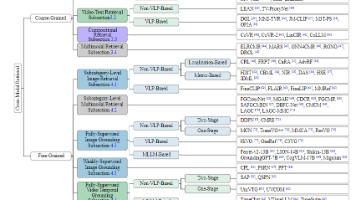
本文提出AOAD-MAT模型,在多智能体强化学习(MARL)中首次显式优化智能体动作决策顺序。该模型基于Multi-Agent Transformer架构,通过动态预测决策顺序和协同损失函数设计,实现了动作预测和顺序预测的双任务联合优化。实验表明,AOAD-MAT在StarCraft多智能体挑战赛(SMAC)和MuJoCo连续控制任务中均超越现有最优方法,验证了决策顺序优化对提升多智能体协作性能和
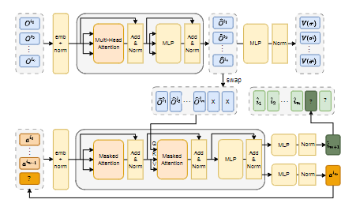
首次将检索粒度从文档级下沉至区域级,通过训练阶段的混合监督策略与推理阶段的动态区域分组机制,在过滤冗余信息的同时提升检索与生成效率,在 6 个主流基准数据集上实现性能突破,相关代码已开源(
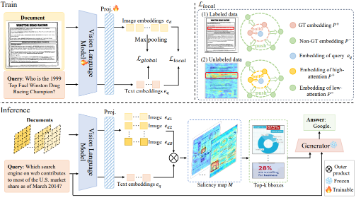
摘要:本文提出HiMo-CLIP框架,针对传统CLIP模型在处理长文本时忽略语义层次和单调性的问题,通过层次分解模块(HiDe)和单调性感知对比损失(MoLo)实现改进。HiDe利用批次内PCA动态提取核心语义组件,MoLo通过双分支损失隐式强化语义单调性。实验表明,该框架在长文本检索任务中性能显著提升(如Docci T2R达84.4%),同时保持短文本兼容性,并首次量化验证了语义单调性(HiMo
