




- @terrygim_123
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
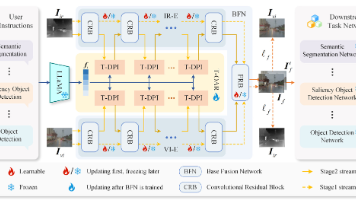
图像融合旨在融合多模态传感器的互补信息,然而现有方法在鲁棒性、适应性和可控性方面仍存在局限。大多数当前的融合网络针对特定任务定制,难以灵活引入用户意图,尤其是在低光照退化、色彩偏移或曝光不平衡等复杂场景中表现不佳。此外,缺乏真实的融合图像标签以及现有数据集规模较小,使得训练一个端到端模型同时理解高层语义与实现细粒度多模态对齐变得困难。为此,我们提出了DiTFuse——一种由指令驱动的扩散-Tran

基础融合网络(BFN)和面向任务的自适应调节模块(T-OAR)。第一阶段(图 2 虚线):训练 BFN 进行 IR-VIS 图像的初始融合,学习高质量的融合表示第二阶段(图 2 实线):冻结 BFN 参数,训练 T-OAR 模块,使融合框架能够根据任务指令自适应调整输出特征这种设计的核心优势在于:一旦完成训练,用户可以通过简单的文本指令切换任务,无需重新训练整个网络,大大提升了部署效率和应用灵活性
单模态目标检测任务在面对复杂场景时常出现性能下降的问题。相比之下,多模态目标检测通过融合来自不同传感器的数据,能够提供更全面的对象特征信息。当前的多模态检测方法普遍采用传统神经网络或基于Transformer的模型进行特征融合,但由于多模态图像由不同传感器采集,常存在空间对齐偏差,导致跨模态匹配困难。本文提出一种新颖的框架——CrOss-Mamba交互与偏移引导融合(COMO),用于解决多模态目标

其中( F^i_R, F^i_T \in R^{W×H×C} )表示RGB和热分支第i层的特征图,( I_R, I_T \in R^{W×H×C} )表示输入的RGB和热图像。:与CFT方法相比,提出的方法具有更低的计算复杂度,总计算复杂度从( O(4T^2×C + 16T×C^2) )降低到( O(2T^2×C + 16T×C^2) )。为了加强来自跨模态和内模态特征的互补信息的记忆,以进一步提
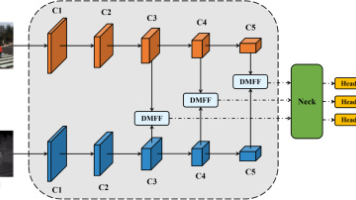
单模态目标检测任务在面对复杂场景时常出现性能下降的问题。相比之下,多模态目标检测通过融合来自不同传感器的数据,能够提供更全面的对象特征信息。当前的多模态检测方法普遍采用传统神经网络或基于Transformer的模型进行特征融合,但由于多模态图像由不同传感器采集,常存在空间对齐偏差,导致跨模态匹配困难。本文提出一种新颖的框架——CrOss-Mamba交互与偏移引导融合(COMO),用于解决多模态目标