




- @sysocc
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
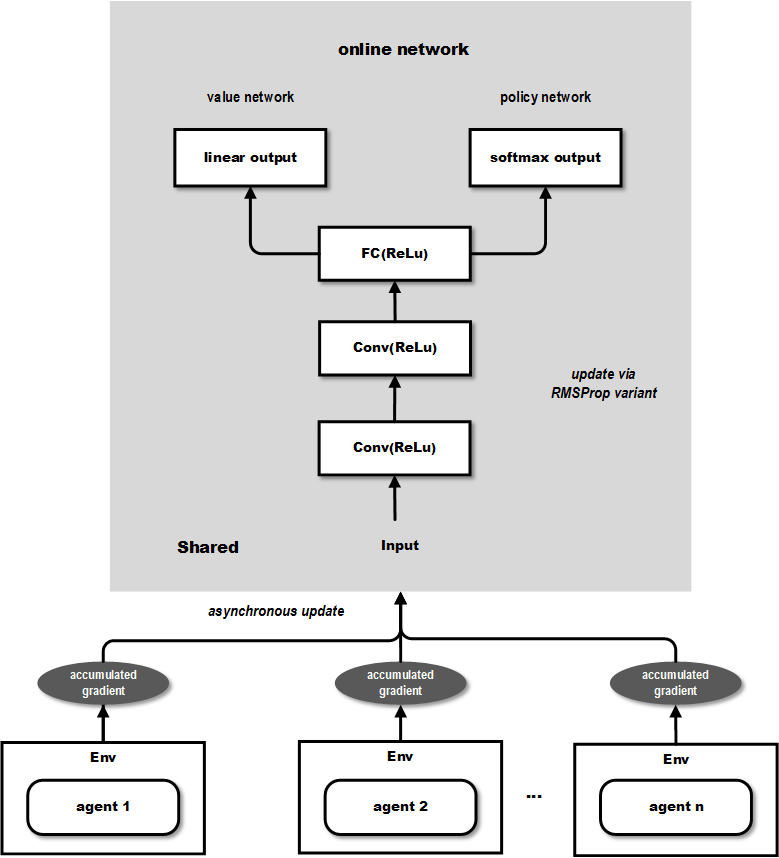
A3C 通过创建多个 agent,在多个环境实例中并行且异步的执行和学习,有个潜在的好处是不那么依赖于 GPU 或大型分布式系统,实际上 A3C 可以跑在一个多核 CPU 上,而工程上的设计和优化也是原始paper的一个重点。从上图可以看出输出包含2个部分,value network 的部分可以用来作为连续动作值的输出,而 policy network 可以作为离散动作值的概率输出,因此能够同时解
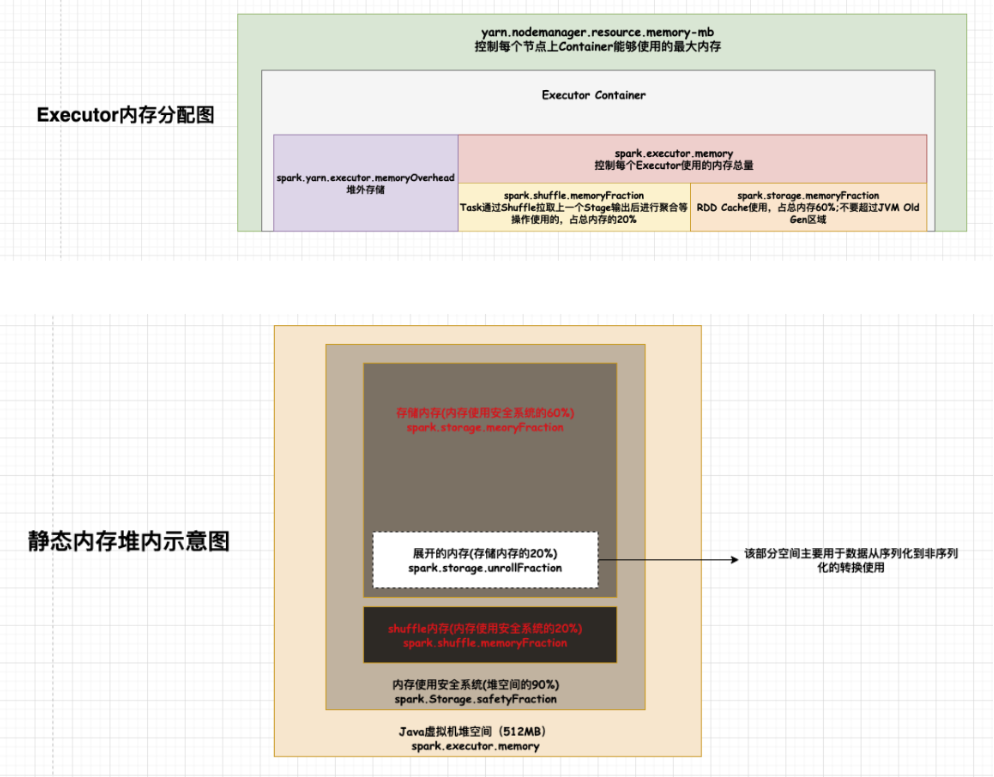
同时如果调小缓存层,那么向Mapper端提取的次数就会变多,性能也就会降低,但相对而言首先思考的是应该先让程序跑起来,然后再考虑增加Executor内存,或者调大缓存来对性能层面进一步的改善。spark shuffle中的reducer阶段获取数据,并不是等Mapper端全部结束之后才抓取数据,而是一边进行shuffle,一边抓取处理数据,Reducer在抓取的数据中间有一个缓存,类似于Java
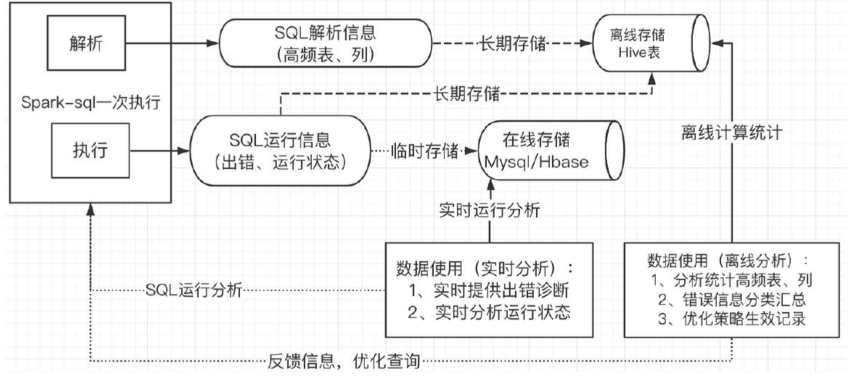
如果一个分区的大小大于所有分区大小的中位数而且大于spark.sql.adaptive.skewedPartitionSizeThreshold,或者分区条数大于所有分区条数的中位数且大于spark.sql.adaptive.skewedPartitionRowCountThreshold。即将小文件存放到DistributedCache中,然后分发到各个Task上,并加载到内存中,类似于Map结
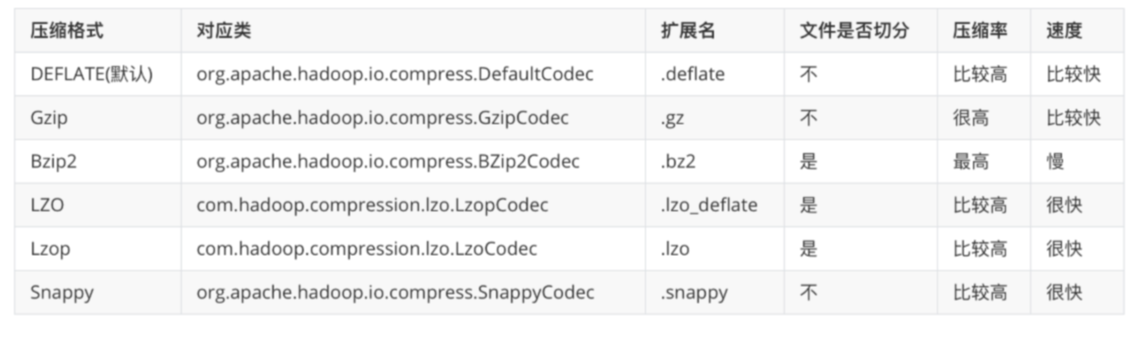
比如Gzip或者Bzip2,当然对于一些不可切分的压缩格式,在生成MR任务的时候,Map数就会有所限制,不能很好的发挥算力。通过set hive.exec.compress.output命令来查看当前系统环境支持的压缩类型。orc.bloom.filter.columns:创建字段对应的布隆过滤器,字段之间以逗号分隔。orc.row.index.stride:索引之间的行数,必须得大于1000。o
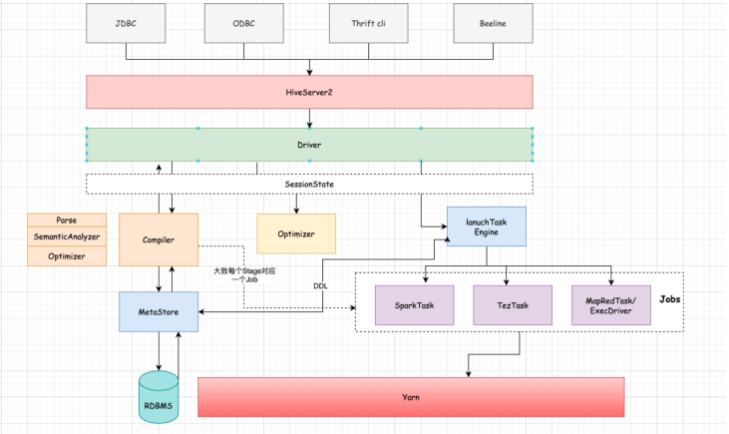
5、SemanticAnalyzer会遍历AST Tree,进一步进行语义分析,这个时候会和Hive MetaStore进行通信获取Schema信息,抽象成QueryBlock,逻辑计划生成器会遍历QueryBlock,翻译成Operator(计算抽象出来的算子)生成OperatorTree,这个时候是未优化的逻辑计划。6、Optimizer会对逻辑计划进行优化,如进行谓词下推、常量值替换、列裁剪
A3C 通过创建多个 agent,在多个环境实例中并行且异步的执行和学习,有个潜在的好处是不那么依赖于 GPU 或大型分布式系统,实际上 A3C 可以跑在一个多核 CPU 上,而工程上的设计和优化也是原始paper的一个重点。从上图可以看出输出包含2个部分,value network 的部分可以用来作为连续动作值的输出,而 policy network 可以作为离散动作值的概率输出,因此能够同时解
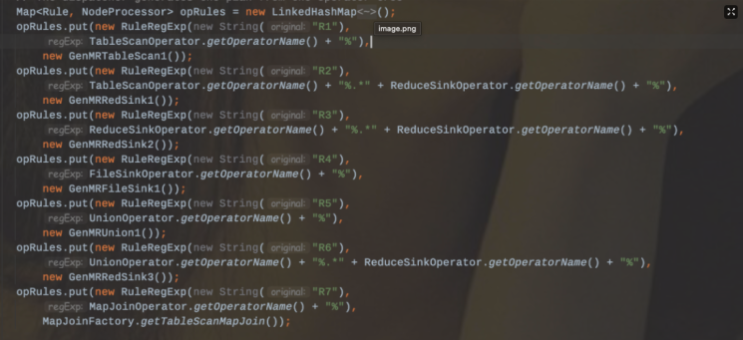
Stage划分的界限决定于ReduceSinkOperator,在遇到ReduceSinkOperator之前的Operator都划分到Map阶段,同时也标识这Map阶段的结束。Stage是Hive执行任务中的某一个阶段,那么这个阶段可能是一个MR任务,也可能是一个抽取任务,也可能是一个Map Reduce Local ,也可能是一个Limit。R5:UNION% ---->如果所有的子查询都是m
Metacat 提供统一的 REST/Thrift 接口来访问各种数据存储的元数据,相应的元数据存储仍然是模式元数据的真实来源,因此 Metacat 不会在其存储中实现它。Databook 提供了来自 Hive、Vertica、MySQL、Postgres、Cassandra 和其他几个内部存储系统的各种元数据,包括:表模式、表/列描述、样本数据、统计数据、血缘、、表新鲜度、SLA 和责任人等等。
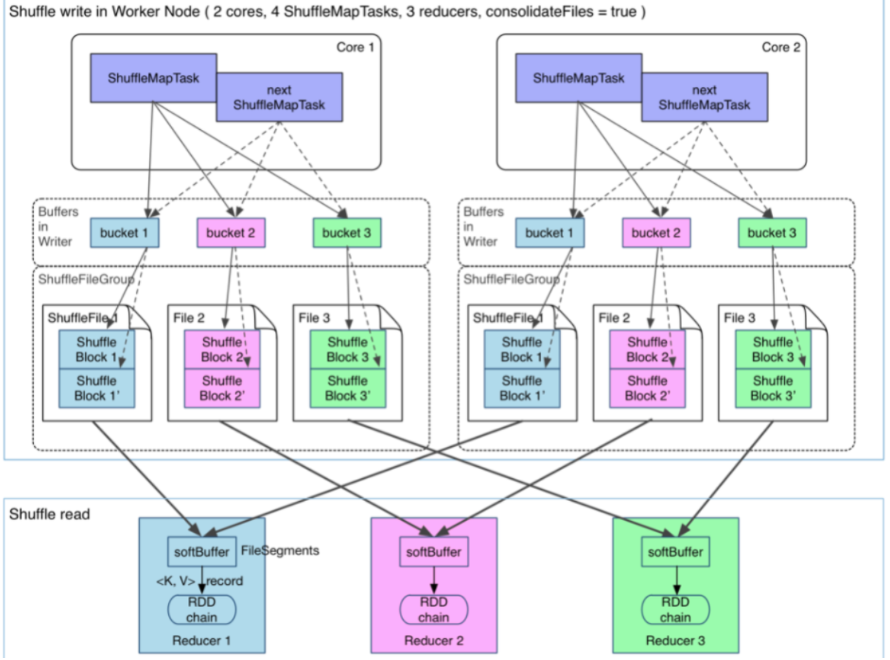
sort shuffle其核心借助于ExternalSorter首先会把每个ShuffleMapTask的输出排序内存中,当超过内存容纳的时候,会spill到一个文件中(FileSegmentGroup),同时还会写一个索引文件用来区分下一个阶段Reduce Task不同的内容来告诉下游Stage的并行任务哪些数据是属于自己的。第二次是根据数据本身的Key进行排序,当然第二次排序除非调用了带排序的
A3C 通过创建多个 agent,在多个环境实例中并行且异步的执行和学习,有个潜在的好处是不那么依赖于 GPU 或大型分布式系统,实际上 A3C 可以跑在一个多核 CPU 上,而工程上的设计和优化也是原始paper的一个重点。从上图可以看出输出包含2个部分,value network 的部分可以用来作为连续动作值的输出,而 policy network 可以作为离散动作值的概率输出,因此能够同时解