




- @sunly31489
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
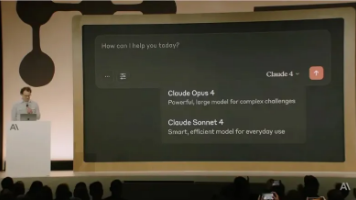
Claude 4 的发布,成为了 AI 编程发展历程中的一座重要里程碑。它不再仅仅是辅助开发者的工具,而是以协作伙伴的新姿态登上舞台。我们正身处于这场变革之中,亲眼见证着软件开发范式的根本性转变。就像 Anthropic 的首席执行官 Dario Amodei 所说的那样,在未来,优秀的开发者并非是那些在写代码方面超越 AI 的人,而是那些最懂得如何与 AI 默契协作的人。
我们的服务特别适合需要高性能计算资源的研究人员、开发者和企业用户,能够满足机器学习、深度学习、科学计算等多种场景的需求。当用户租用算力后,平台会自动分配独立的Pod环境,用户可以通过公网IP和映射端口的方式便捷地访问和管理自己的计算环境。为了提升用户体验,平台支持环境持久化功能,用户可以将配置好的环境打包为镜像,在后续使用其他算力资源时快速复用,大大减少环境配置的时间成本。我们配备了专业的开发、运
上周我就在这里租了一天A800 80G来测试一下我跑的模型,因为我自有的设备实在是跑不动,只能租赁,体验下来整个租用服务还是比较好的,会有一对一的运维客服,你需要什么系统,能装的都可以给你提供,不懂的问题在群里提问,随时会有技术人员给你解答,租用要到期的时候,也会有人来提醒你是否准备续租,保存好自己需要的数据,A800还是很给力的,比我的电脑快了好多,让我原有的速度大概提高了6-7倍。这几个平台比

FP32性能达到了82.58TFLOPS,使它能够适用于图形设计、复杂的视频编辑工作以及深度学习领域,是大多数个人以及小型实验室预算所能配置的最高级显卡了,缺点就是比较贵,单卡售价就要1.8w了,因此预算不够的也可以考虑40系列的其他卡如4060ti 16G版本的现在也才3500一张卡,跑深度学习最重要的就是显存,显存决定了你能不能跑这个模型,只要能跑,哪怕速度慢一点是可以的,而且睡觉的时候我们也
一、引言在深度学习这片充满无限可能的领域里,显卡可是扮演着举足轻重的角色,堪称 AI 模型成长的 “超级摇篮”。从最初简单的神经网络到如今动辄上亿参数的巨型模型,每一次突破的背后,都离不开显卡强大算力的默默支撑。毫不夸张地说,显卡的迭代更新,直接推动着深度学习向前飞速发展。今天,就来给大家深度剖析几款深度学习领域的主流显卡 ——4090、V100、L40、A100、H100,看看它们究竟有何 “超
根据网上的爆料,英伟达 RTX 5090 的 CUDA 核心数量将比 4090 增加 50%,达到 24567 个,这意味着其并行计算能力将大幅增强,能够同时处理更多的数据和任务,从而在复杂的计算场景中表现更出色。目前,英伟达 4090 的市场价格大概在1.8w-2w之间,而英伟达 5090 的价格尚未正式公布,不过目测在2w左右,也就是说比4090会稍高一点,如果预算有限,且现有的 4090 能

多模态大模型是指能够同时处理多种模态数据(如文本、图像、语音、视频等)的 AI 模型。看图说话(Image Captioning):根据图片生成描述性文字。文生图(Text-to-Image):根据文本生成高质量图像。视频理解(Video Understanding):分析视频内容并生成摘要。语音 + 文本交互(Speech-to-Text & Text-to-Speech):实现更自然的语音助手

艾思克孚Eissee Kraft 是一家源自德国的液冷服务器解决方案专业服务商,作为全球领先的液冷技术领航者,公司始终以创新为核心驱动力,深耕液冷技术领域二十余年,专注为数据中心、新能源、人工智能等高能耗行业提供高效、可靠、绿色的温控解决方案。站在新的起点,面对全球碳中和目标与算力爆炸式增长的双重挑战,液冷行业迎来战略机遇。艾思克孚Eissee Kraft将以“液态智慧”为核心,加速液冷技术与AI

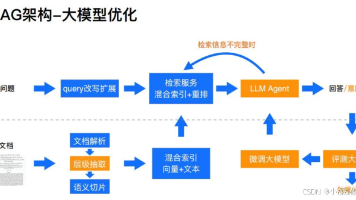
从Token的经济账到RAG的精准性,从量化的效率革命到智能体的自动化突破,这些术语背后折射出AI技术的演进逻辑。对于从业者而言,理解这些概念不仅是技术对话的入场券,更是设计产品、评估方案、洞察趋势的关键。:Token是AI处理文本的最小单位,相当于自然语言中的“字词片段”。:大模型“蒸馏”技术是把大语言模型中的能力和知识迁移到更小的模型的技术,目的是在于构造出来资源高效和性能优异的小模型,未经过
根据网上的爆料,英伟达 RTX 5090 的 CUDA 核心数量将比 4090 增加 50%,达到 24567 个,这意味着其并行计算能力将大幅增强,能够同时处理更多的数据和任务,从而在复杂的计算场景中表现更出色。目前,英伟达 4090 的市场价格大概在1.8w-2w之间,而英伟达 5090 的价格尚未正式公布,不过目测在2w左右,也就是说比4090会稍高一点,如果预算有限,且现有的 4090 能