- @solitude_sw
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在训练网络模型的过程中,实际上我们希望保存中间和最后的结果,用于微调(fine-tune)和后续的模型推理与部署,本章节我们来学习如何保存与加载模型。

模块提供了一些常用的公开数据集和标准格式数据集的加载API。可以构造自定义数据加载类或自定义数据集生成函数的方式来生成数据集,然后通过接口实现自定义方式的数据集加载。

从网络构建中加载代码,构建一个神经网络模型。nn.ReLU(),nn.ReLU(),超参(Hyperparameters)是可以调整的参数,可以控制模型训练优化的过程,不同的超参数值可能会影响模型训练和收敛速度。训练轮次(epoch):训练时遍历数据集的次数。批次大小(batch size):数据集进行分批读取训练,设定每个批次数据的大小。batch size过小,花费时间多,同时梯度震荡严重,不

ResNet50是微软实验室的何恺明在2015年提出的残差网络,在ILSVRC2015图像分类竞赛中获得第一名。传统的卷积神经网络堆叠到一定深度时,会出现退化问题(网络越深,误差反而增大)。为了解决这一问题,ResNet引入了残差网络结构,使得网络可以堆叠得更深(超过1000层),且不会出现退化现象。下图展示了在CIFAR-10数据集上,使用传统网络和ResNet网络训练的误差对比图,可以看出,随

FCN主要用于图像分割领域,是一种端到端的分割方法,是深度学习应用在图像语义分割的开山之作。通过进行像素级的预测直接得出与原图大小相等的label map。因FCN丢弃全连接层替换为全卷积层,网络所有层均为卷积层,故称为全卷积网络。全卷积神经网络主要使用以下三种技术:卷积化(Convolutional)使用VGG-16作为FCN的backbone。VGG-16的输入为224*224的RGB图像,输
在实际应用场景中,由于训练数据集不足,所以很少有人会从头开始训练整个网络。普遍的做法是,在一个非常大的基础数据集上训练得到一个预训练模型,然后使用该模型来初始化网络的权重参数或作为固定特征提取器应用于特定的任务中。本章将使用迁移学习的方法对ImageNet数据集中的狼和狗图像进行分类。
当我们定义神经网络时,可以继承nn.Cell类,在__init__方法中进行子Cell的实例化和状态管理,在construct方法中实现Tensor操作。nn.ReLU(),nn.ReLU(),构建完成后,实例化Network对象,并查看其结构。我们构造一个输入数据,直接调用模型,可以获得一个十维的Tensor输出,其包含每个类别的原始预测值。logits在此基础上,我们通过一个nn.Softma
SSD,全称Single Shot MultiBox Detector,是Wei Liu在ECCV 2016上提出的一种目标检测算法。使用Nvidia Titan X在VOC 2007测试集上,SSD对于输入尺寸300x300的网络,达到74.3%mAP(mean Average Precision)以及59FPS;对于512x512的网络,达到了76.9%mAP ,超越当时最强的Faster R

ShuffleNetV1是旷视科技提出的一种计算高效的CNN模型,和MobileNet, SqueezeNet等一样主要应用在移动端,所以模型的设计目标就是利用有限的计算资源来达到最好的模型精度。ShuffleNetV1的设计核心是引入了两种操作:Pointwise Group Convolution和Channel Shuffle,这在保持精度的同时大大降低了模型的计算量。因此,ShuffleN

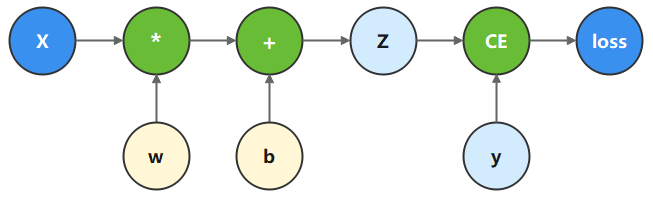
神经网络的训练主要使用反向传播算法,模型预测值(logits)与正确标签(label)送入损失函数(loss function)获得loss,然后进行反向传播计算,求得梯度(gradients),最终更新至模型参数(parameters)。自动微分能够计算可导函数在某点处的导数值,是反向传播算法的一般化。自动微分主要解决的问题是将一个复杂的数学运算分解为一系列简单的基本运算,该功能对用户屏蔽了大量