




- @soaring_casia
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
相较于固定动作执行模式,运动跟踪无需提前预设运动路径,可实时适配目标的移动、转向、变速等动态变化,广泛应用于机器人跟随、动态抓取、遥操作控制等场景,让机器人具备基础的环境动态响应能力。人类的运动姿态自然、协调,是机器人最优的运动参考样本,但人体与机器人的骨骼结构、关节自由度、运动限位、体型参数差异极大,原始人体动作捕捉数据无法直接用于机器人执行。该路线技术成熟、稳定性高、安全约束性强,适合结构化、
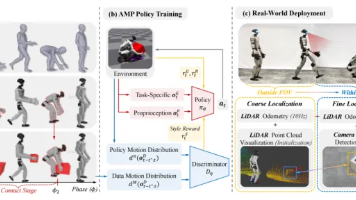
同类混合架构目前极少,比亚迪这套方案填补“像素细节+潜态鲁棒”的中间空白,相比多激光融合方案硬件成本更低,仅依靠前视单相机就能实现均衡表现,对量产车型成本控制更友好。同时,论文搭建的噪声鲁棒评测数据集,给后续世界模型研发提供统一量化标准,解决行业此前只看仿真高分忽略真实恶劣路况的评测盲区。这个VAE相当于“图像翻译器”,既能还原高清路面画面,又能产出干净带语义信息的隐向量,是混合建模的基础载体。两

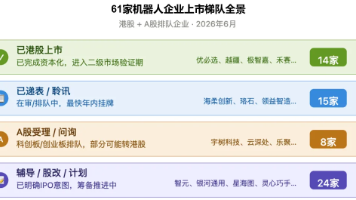
除已上市的6家企业外,还另有递表4家、A股排队1家、辅导/筹备5家。已驶入“安全区”的上岸者、终点线前冲刺的排队者、刚站上起跑线的递表新贵,以及正从水下浮出的庞大预备队。据多方渠道统计,目前正在港股排队上市(含已上市)的机器人相关企业已有50余家,加上A股排队的8家,缺少实打实的营收、成熟的落地场景与清晰的盈利路径,依靠行业风口堆砌的估值泡沫,终有消解之时。更值得注意的是,智元、银河通用、星海图、
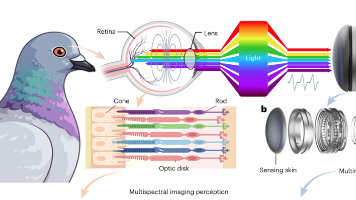
在机器人领域,“触觉”一直是个棘手的难题:传统传感器要么分辨率低到摸不清纹理,要么只能测压力却辨不出温度。近日,清华大学丁文伯团队联合无界智航(Xspark AI)及多所国内外科研机构在《Nature Sensors》上发表的,直接打破了这个僵局——借鉴鸽子的多光谱视觉原理,把多光谱成像、摩擦电传感、惯性测量揉进,不仅能精准识别纹理、材质、温度,还能预判碰撞和滑动,分类准确率超94%。
villa-X是由微软研究院、清华大学等机构联合提出的一种新型ViLLA框架,目的是改进机器人操作的潜在动作建模,从而提升模型在复杂场景中的泛化能力。然而现有ViLLA模型的主要问题是:生成的潜在动作可能不符合机器人物理动力学基础,为解决此问题,villa-X提出了2个主要改进点:(1)在潜在动作模型中引入本体感知前向动力学模块(FDM)作为辅助解码器,通过预测未来机器人本体感知状态和动作,促使学
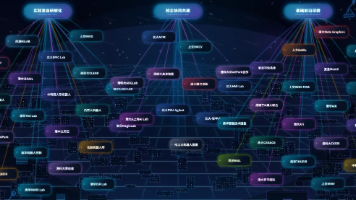
信息均由深蓝具身智能团队手动整理,虽经多方核对,或有疏漏之处,欢迎各位在评论区补充指正。文末获取国内具身智能实验室全景图(海外篇正在路上)。划分依据公开产学研现状归纳,边界存在交叉,仅作参考,非官方定性界定。等底层科学问题上,承担着关键性技术攻关与长期学术储备的任务。企业提供场景与工程化能力,高校提供前沿算法突破,02校企协同共建,合作型科研团队。这些实验室是具身智能的“基础研究腹地”。据不完全统
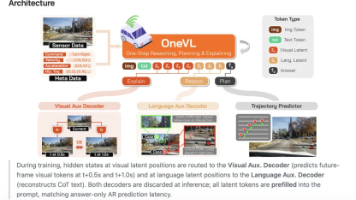
框架的设计形态,让潜在推理模式不再需要牺牲任务表现换取低时延,拉近了潜在推理与显式推理的效果差距,同时增添视觉场景推演的解释维度,丰富了模型决策的可追溯性。,既可以输出自然语言形式的决策推理描述,也可以生成未来短时场景的推演画面,相比只提供单一语言解释的模型,可参考的信息维度更为丰富,便于研发人员做场景调试、问题定位与效果验证,双模态可解释能力的实现逻辑在项目主页技术介绍中有完整说明。所有潜在令牌
零样本泛化的优势在于极大地降低了机器人在新环境中的部署门槛。经过预训练的模型在完全未见过的环境中,展现出强悍的零样本手部动作预测能力,并可通过少量真实机器人动作数据进行微调,以显著提升任务成功率和对新物体的泛化能力。,其训练数据集同样来自约 500 小时的高质量多机器人、多操作员遥操作数据,实现了对 35 个自由度的全上肢精细控制,包括手腕、躯干、头部和各手指。零样本泛化代表了机器人技能学习的另一

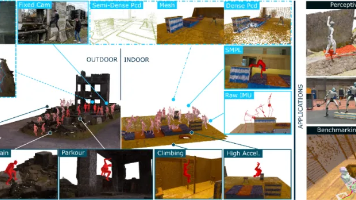
他们用惯性动捕服记录身体运动,用第一视角智能眼镜提供全局轨迹,再用便携式 3D 扫描仪重建环境,把人体姿态、脚部接触和场景几何对齐到同一个坐标系中。▲图6 | 团队先将场景中的 SMPL-X 人体动作迁移到 Unitree G1 的身体结构,并在对应的碰撞场景中检查动作与环境的几何关系;人体 SMPL-X 网格位于统一场景坐标中,脚部接触可以逐帧获得,第一视角和部分外部观察视角能够同步对应,场景还
跨场景域偏移导致标注成本高昂。依靠稀疏注意力提速、优化小目标特征,修复DETR收敛慢、远距离路标漏检缺DETR量产优化版本,适配自动驾驶远距离、小尺寸交通标识检测,车规Transformer检测基线。每个算法我们都尽可能直白讲解原理、指明核心创新,提炼一下共同点(都是同一个大思想下的小改动),顺便也说说车载落地适配性,贴合自动驾驶车辆、行人、交通标识、遮挡小目标检测需求。未来结合视觉预训练大模型、
