




- @sinat_16020825
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
经常遇到这个问题,特记录解决方法,供后续遇到同样问题时查阅。
数据增强(Data Augmentation),基于有限的数据生成更多等价(同样有效)的数据,丰富训练数据的分布,使通过训练集得到的模型泛化能力更强。数据增强可以分为两类,离线增强和在线增强。主要有仿射变换、透视变换、色调变换等等。
模型分类效果主要是通过计算混淆矩阵已经准确率、召回率和F Score来分析,下面对以上指标进行详细的介绍。
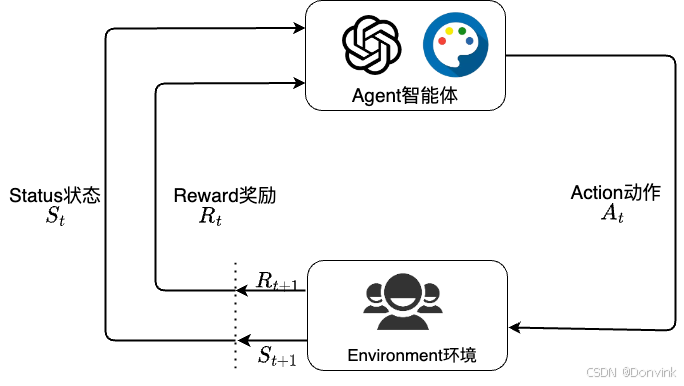
强化学习(Reinforcement Learning, RL)是一种智能体在与环境互动过程中,通过试错和奖励机制学习如何达成目标的算法。在这个过程中,智能体会不断探索环境,采取行动,并根据环境反馈的奖励或惩罚调整自己的行为策略,最终学习到最优策略。因此,反复实验(trial and error)和延迟奖励(delayed reward)是强化学习最重要的两个特征。
本文详细介绍了开源的视频生成模型MovieGen和HunyuanVideo预训练数据的处理流程以及预训练流程。

本文将直接使用 Qwen2.5-VL-7B-Instruct 模型在 coco_2014_caption 数据集上进行LoRA微调训练,旨在熟悉Qwen2.5-VL数据处理和训练流程。GitHub地址:https://github.com/Donvink/Qwen2.5-VL-Finetune

本文主要是介绍通义万相视频生成模型本地部署教程,包括文生视频、图生视频和首尾帧生成视频,最后简要介绍LoRA训练Wan2.1

本项目应用Python爬虫、Flask框架、Echarts、WordCloud等技术将豆瓣租房信息爬取出来保存于Excel和数据库中,进行数据可视化操作、制作网页展示。包括三部分:- douban_renting:Python 爬虫将豆瓣租房上的租房信息爬取出来,解析数据后将其存储于Excel和SQLite数据库中。- flask_demo:测试使用Flask框架。- douban_flask:应
经常遇到这个问题,特记录解决方法,供后续遇到同样问题时查阅。
本文详细介绍HunyuanVideo的部署、应用以及源码分析。不得不说,生成的视频很真实生动!
