




- @shi_jiaye
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
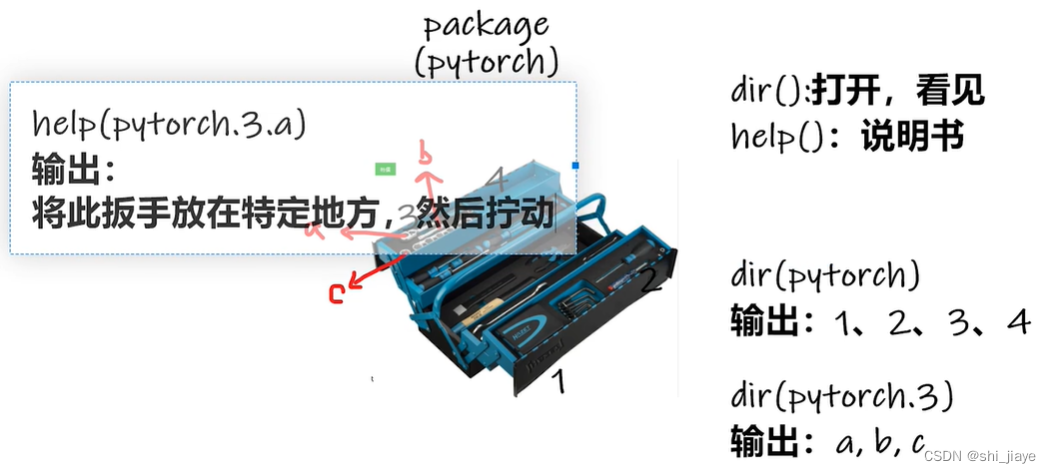
深度学习python编译器的配置及法宝函数的作用
主要内容分类概述决策树归纳K近邻算法支持向量机朴素贝叶斯分类模型评估与选择组合分类七、组合分类组合分类方法简介袋装提升和AdaBoost随机森林
主要内容聚类分析概述K-Means聚类层次聚类基于密度的聚类其他聚类方法聚类评估五、其他聚类方法除了常用的划分聚类、层次聚类和密度聚类方法之外,还有一些聚类方法如网格聚类方法STING、概念聚类COBWEB和模糊聚类方法等。STING聚类STING(Statistical Information Grid_based Method)是一种基于网格的多分辨率的聚类技术,它将输入对象的空间区域划分成矩
深度学习python编译器的配置及法宝函数的作用
主要内容:数据预处理的必要性数据清洗数据集成数据标准化数据规约数据变换与离散化利用sklearn进行数据预处理四、数据标准化不同特征之间往往具有不同的量纲,由此造成数值间的差异很大。因此为了消除特征之间量纲和取值范围的差异可能会造成的影响,需要对数据进行标准化处理。1.离差标准化数据离差标准化是对原始数据所做的一种线性变换,将原始数据的数值映射到[0,1]区间。数据的离差标准化。import nu
主要内容分类概述决策树归纳K近邻算法支持向量机朴素贝叶斯分类模型评估与选择组合分类四、支持向量机支持向量机(Support Vetor Machine,SVM)由Vapnik等人于1995年首先提出,在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并推广到人脸识别、行人检测和文本分类等其他机器学习问题中。SVM建立在统计学习理论的VC维理论和结构风险最小原理基础上,根据有限的样本信息在模