




- @sdlcjx
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
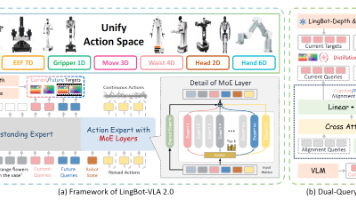
本文介绍了LingBot-VLA 2.0系统在跨本体通用机器人控制领域的创新实践。该系统通过三个核心改进应对真实世界部署挑战:1)构建六万小时跨本体预训练数据集,覆盖20种机器人配置;2)设计55维统一动作表征空间,实现从单臂到全身协同的异构控制;3)提出双查询蒸馏框架,增强动态场景预测能力。实验表明,该系统在双臂操作和长程移动任务中显著优于基线模型,尤其在分布外场景下展现出更强的鲁棒性。这些创新
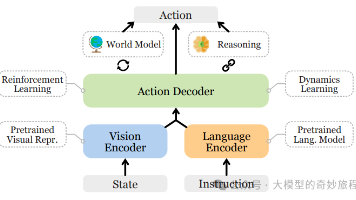
Qwen-RobotManip 的研究表明,大规模语言与多模态模型的"对齐-扩展"范式同样适用于机器人操作领域,前提是建立正确的跨形态统一形式。通过规范状态-动作表征、相机坐标系末端执行器运动预测与上下文策略自适应三个互补机制,研究团队将异构多源数据转化为连贯的训练信号,使模型能够吸收以往无法支撑的规模化数据,并涌现出零样本指令遵循、扰动鲁棒性、错误恢复与跨形态迁移等泛化能力。该工作同时揭示了领域
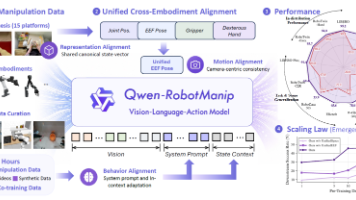
Qwen-RobotManip 的研究表明,大规模语言与多模态模型的"对齐-扩展"范式同样适用于机器人操作领域,前提是建立正确的跨形态统一形式。通过规范状态-动作表征、相机坐标系末端执行器运动预测与上下文策略自适应三个互补机制,研究团队将异构多源数据转化为连贯的训练信号,使模型能够吸收以往无法支撑的规模化数据,并涌现出零样本指令遵循、扰动鲁棒性、错误恢复与跨形态迁移等泛化能力。该工作同时揭示了领域
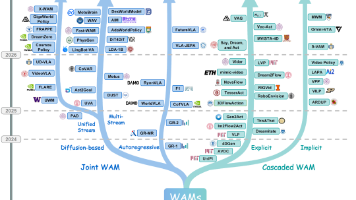
视觉-语言-动作(VLA)模型与世界动作模型(WAMs)的融合正在推动机器人学习从反应式控制向预见性推理转变。VLA模型虽在语义泛化方面表现优异,但其反应式特性限制了长程任务的执行能力。WAMs通过联合建模未来状态与动作的联合分布,为机器人提供预测性推理能力。本文系统梳理了WAMs的架构分类(级联式与联合式)、技术路线、数据生态与评估体系,揭示了这一快速演进领域的发展趋势。级联式WAM保持预测与执
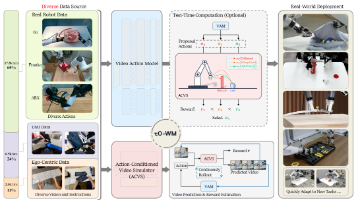
上海人工智能实验室与AGIBOT Finch团队提出的τ0-World Model(τ0-WM)创新性地整合了视频预测、动作生成与评估功能,通过共享视频扩散骨干网络实现了多源异构数据的联合训练。该模型在27,300小时的机器人遥操作、UMI式演示和人体交互视频数据上进行训练,采用统一监督掩码机制处理不同数据源的差异。τ0-WM包含视频动作模型(VAM)和动作条件化视频模拟器(ACVS)双分支,分别
本文系统梳理了视觉-语言-动作(VLA)模型的数据基础设施,重点分析数据集、基准测试和数据引擎三大支柱。研究表明,VLA发展面临fidelity-cost权衡困境:真实世界数据集保真度高但成本昂贵,合成数据可扩展性强却保真度不足。当前主流采用"合成预训练+真实微调"范式,而未来突破将更依赖高质量数据引擎与结构化评估协议的协同设计。基准测试评估显示,多场景任务中的组合推理和环境变
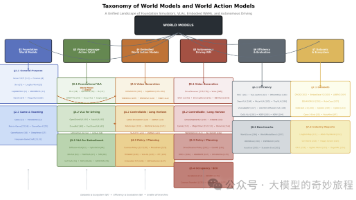
本文综述了具身世界动作模型(WAM)的最新进展,系统梳理了六大技术支柱:基础世界模型、视觉-语言-动作(VLA)模型、具身WAM、自动驾驶世界模型、效率与评测、数据集与生态。研究显示,世界模型正从被动视频预测器演进为可交互的物理仿真器,而VLA模型则建立了连接语义意图与运动控制的桥梁。二者的融合催生了WAM这一新型架构,使智能体能够通过"想象"未来状态来规划动作。文章重点分析了
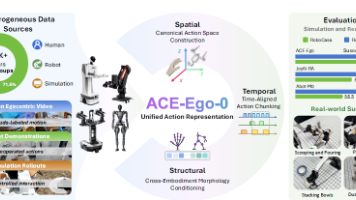
**摘要:**ACE-Ego-0框架通过统一异构数据表示与可靠性感知训练,解决了视觉-语言-动作(VLA)模型预训练中人类视频与机器人数据融合的关键难题。该框架创新性地采用规范动作空间、跨本体形态条件化和时间对齐动作分块实现异构数据对齐,并通过分层可靠性权重调制监督信号。在超过6,000小时的混合数据集预训练后,ACE-Ego-0在RoboCasa和RoboTwin 2.0等基准测试中取得领先性能
盘古5.0的STCG技术,正在从三个维度重塑自动驾驶开发范式:表格维度传统模式盘古STCG模式数据成本百万公里路测,人力物力高昂云端大规模并行生成,边际成本趋近于零场景覆盖依赖自然采集,长尾场景稀疏按需生成极端场景,实现"场景自由"标注精度人工标注存在误差与成本瓶颈生成过程自带完美标注(3D框、轨迹、语义分割)更重要的是,由于STCG生成的视频在几何一致性、物理合理性与视觉逼真度上均达到工业标准,
盘古世界模型深度解读:当STCG遇见4D空间,华为如何用"物理引擎+数据驱动"重构自动驾驶仿真范式