




- @rstroller
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
文档与知识沉淀 Agent,这个 Agent 的核心定位不是“写代码注释”,而是“提炼上下文,反哺人类与系统”。必须引入不写代码、只做审查的 Agent。四、 关键问题应对策略 1. 如何约束单一职责原则 属于语义层面,难以用纯代码精确断言,采用“物理特征截断 + AI 兜底”策略: 物理截断:在 Lint 工具中配置硬性阈值,一旦 Agent 写出上帝类,直接阻断。融入 Agent 循环:Age
文档与知识沉淀 Agent,这个 Agent 的核心定位不是“写代码注释”,而是“提炼上下文,反哺人类与系统”。必须引入不写代码、只做审查的 Agent。四、 关键问题应对策略 1. 如何约束单一职责原则 属于语义层面,难以用纯代码精确断言,采用“物理特征截断 + AI 兜底”策略: 物理截断:在 Lint 工具中配置硬性阈值,一旦 Agent 写出上帝类,直接阻断。融入 Agent 循环:Age
【摘要】当前LLM研发的核心已从模型结构转向数据质量,关键在于通过任务工程构建高质量数据集。核心策略是从生成答案转向定义高价值任务,采用Self-Instruct方法进行递归扩展,结合约束条件和难度梯度控制。工业级实践强调多模型混合生成、风格扰动和真实数据锚定,防止模式坍塌。最终需构建覆盖多维度能力的任务体系,通过严格清洗和验证,打造高熵数据集。小团队应聚焦高价值任务密度而非规模,用数百个核心模式
1、 合成数据阶段:从“生成”到“构建”结构化输出是核心:不要寄希望于模型的 Prompt 约束“自觉性”。在合成阶段,必须通过 Schema定义Pydantic或结构化协议强制模型输出格式。这能从根源上减少后续清洗的负担。元数据注入即正义:合成数据不应仅仅包含问题和答案。在合成阶段就通过 Prompt 引导模型自动生成元数据Metadata如:领域主题、难度等级、任务类型、事实性标记,是实现后续
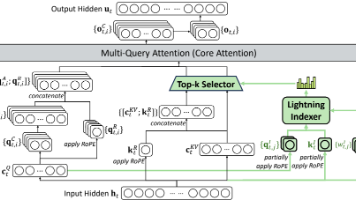
DeepSeek-V3.2-Exp引入了DSA(DeepSeek Sparse Attention)稀疏注意力机制,在MLA(Multi-head Latent Attention)低秩压缩的基础上进一步优化长序列处理。DSA通过闪电索引器动态计算token相关性,仅选择最相关的k个token进行注意力计算,将复杂度从O(L²)降至O(Lk)。该机制采用两阶段训练:先稠密训练对齐索引器,再稀疏优化
CoPaw是一个多功能的个人AI助手系统,采用分层架构设计,支持多渠道通信。系统包含五层架构:用户层(支持多种通信平台)、应用层(FastAPI动态路由)、核心Agent层(内置工具和记忆管理)、支撑服务层(模型和安全模块)以及基础设施层。核心功能包括动态Agent路由、安全拦截、记忆管理和技能扩展。系统通过Workspace机制实现多Agent独立运行,每个实例拥有完整的运行时组件。后端服务采用
cuda11.7安装 pip3 install xformers==0.0.23.post1及以下版本,例如。默认不指定xformer版本可能安装最新版,对于之前版本的cuda会不兼容。

摘要: 正则化技术是防止大模型过拟合的关键方法,主要包括L2正则化和Dropout两种核心机制。L2正则化通过在损失函数中增加权重平方惩罚项,迫使模型参数变小,从而获得更平滑、泛化能力更强的解。Dropout则通过随机屏蔽神经元,打破神经元间的共适应关系,等效训练多个子模型集成。两者从不同角度提升模型鲁棒性:L2正则化约束参数空间,Dropout改变网络结构。现代实现多采用Inverted Dro
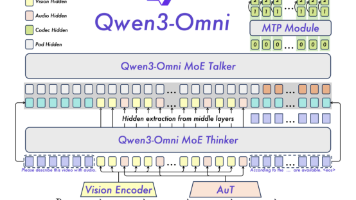
Qwen3-Omni是一种端到端多模态基础模型,能够处理文本、图像、音频和视频输入,并生成文本和语音响应。文章通过代码示例展示了该模型的推理流程,重点分析了其多模态数据处理机制。模型采用Thinker-Talker架构设计,其中Thinker模块负责多模态内容的融合处理,Talker模块负责语音生成。在推理过程中,模型首先通过处理器整合多模态输入,然后由Thinker生成中间表示,最后可选择性地由
vLLM是一个高效的大语言模型推理开源工具,采用PagedAttention和连续批处理技术提升显存利用率和推理效率。实验显示在14GB显存显卡上运行Qwen3-VL-4B-Instruct模型时,合理配置max-model-len等参数可优化资源使用。建议max-num-seqs设为1-2,gpu-memory-utilization设为0.95,避免使用cpu-offload-gb等影响性能的