




- @qq_65052774
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
2026年7月20日至26日,腾讯、海康威视和字节跳动发布了新的大模型相关岗位。腾讯在北京、深圳招聘混元AI Agent工程师,重点关注上下文管理等细分能力;海康威视在杭州招聘高级应用软件工程师,要求具备AI工程及后端开发经验,强调Agent应用的持续迭代和稳定性;同时新增Java开发岗位,需兼顾传统后端技术和大模型应用能力。字节跳动在深圳招聘抖音AI应用开发实习生。本周岗位显示行业趋势向Agen

2026年7月20日至26日,腾讯、海康威视和字节跳动发布了新的大模型相关岗位。腾讯在北京、深圳招聘混元AI Agent工程师,重点关注上下文管理等细分能力;海康威视在杭州招聘高级应用软件工程师,要求具备AI工程及后端开发经验,强调Agent应用的持续迭代和稳定性;同时新增Java开发岗位,需兼顾传统后端技术和大模型应用能力。字节跳动在深圳招聘抖音AI应用开发实习生。本周岗位显示行业趋势向Agen
摘要:针对Git推送时出现的443端口连接超时问题,本文提出快速解决方案:通过git remote set-url命令将HTTPS协议切换为SSH协议(如git@github.com:user/repo.git),无需调整代理设置即可绕过网络限制。切换后仍可使用原push命令,Git会自动处理协议转换。首次推送需注意分支命名一致性(main/master),并推荐使用-u参数建立永久追踪关系,后续

本文深入解析LangChain框架和RAG技术在大模型应用中的关键作用。LangChain作为大语言模型应用开发框架,提供Prompts、Models、History等核心组件,支持构建复杂业务逻辑。针对通用大模型的实时性、私域知识等痛点,RAG技术通过检索外部知识库增强生成效果,其工作流包括离线知识库构建(文本向量化存储)和在线服务(语义检索+提示优化)两个阶段。文章还详细介绍了向量化技术、余弦

本文介绍了DBSCAN密度聚类算法的原理和应用。DBSCAN通过识别核心点、边界点和噪声点,能自动发现任意形状的簇且无需预设簇数量。文中分析了具体代码实现:设置邻域半径(epsilon)和最小样本数(min_samples)参数,使用fit_predict方法对经纬度数据进行聚类,通过标签-1识别并去除噪声点。该方法特别适合处理含噪声和不规则形状簇的数据,是一种灵活有效的聚类工具。

Spark的设计遵循“一个软件栈满足不同应用场景既能够提供内存计算框架,也可以支持SQL即时查询、实时流式计算、机器学习和图计算等。Spark可以部署在资源管理器YARN之上,提供一站式的大数据解决方案。因此,Spark所提供的生态系统足以应对上述三种场景,即同时支持批处理、交互式查询和流数据处理。所以Executor和CPU的流水线还是不一样,前者是串行流水线,后者是并行流水线。而在多核情况下,

摘要:本文介绍了SOTA(最先进技术)模型的概念及其在机器学习领域的应用,重点分析了生成模型和判别模型的特点。生成模型学习数据的联合概率分布,适用于数据生成和缺失数据处理;判别模型则学习条件概率分布,擅长分类、回归和特征选择任务。文章还指出聚类方法不属于这两类模型,因其不涉及标签学习。

图像分割与监测是计算机视觉的重要应用。图像监测用于持续观察场景变化,应用于环境、安防和工业领域。图像分割则将图像细分为多个区域,包括阈值分割、边缘检测和深度学习方法,在医疗、自动驾驶等场景发挥关键作用。语义分割按类别划分区域,实例分割进一步区分同类个体,常用模型包括FCN、U-Net和Mask R-CNN等深度学习网络。这些技术为精准识别和定位目标提供了有效解决方案。

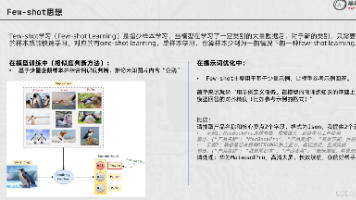
本文系统阐述了大语言模型(LLM)开发的核心技术路径,聚焦环境配置、模型交互与提示工程三大维度。首先对比云端调用(API密钥安全管理)与本地部署(Ollama框架)方案,解析不同场景下的技术选型策略。其次剖析模型交互中枢机制,详细解读System/User/Assistant三类角色的结构化协同原理。重点探讨提示工程中的Zero-shot与Few-shot学习范式,揭示如何通过自然语言示例实现知识
图像分割与监测是计算机视觉的重要应用。图像监测用于持续观察场景变化,应用于环境、安防和工业领域。图像分割则将图像细分为多个区域,包括阈值分割、边缘检测和深度学习方法,在医疗、自动驾驶等场景发挥关键作用。语义分割按类别划分区域,实例分割进一步区分同类个体,常用模型包括FCN、U-Net和Mask R-CNN等深度学习网络。这些技术为精准识别和定位目标提供了有效解决方案。