




- @qq_62965644
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
当涉及到强化学习中的策略梯度算法时,这类算法的主要目标是直接学习策略函数,以获得在给定状态下选择动作的最优策略。策略梯度算法通常可以处理连续动作空间,并且在高维状态空间中表现较好。这类算法不需要像值函数方法(如Q-learning)那样对值函数进行近似,而是直接优化策略函数。策略梯度算法的核心思想是使用梯度上升法来更新策略函数参数,使得在累积奖励上升的方向上更新参数。具体来说,策略梯度算法根据环境

这里,表示的是在s状态下采取行动a的价值与采取行动θ的价值的差,这是衡量行动a相对于平均水平的价值,假如A大于0,那么a行动会更好,否则就更差。clipe是一个切片函数,它的主要作用是限制更新过程中,新决策和旧决策的变化比率从而保证性能的稳定性。其中r表示在状态s下所选择的行动a的概率除以旧策略下相同状态选择相同行动的概率,这个称作重要性采样比。PPO算法是对应TRPO算法的简化,PPO相对于TR
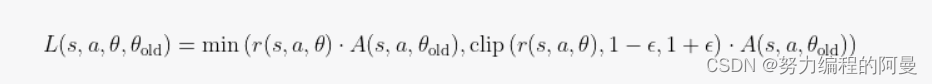
这个原因在于假如在一个游戏中,我们的目标状态并不是固定,可能是一直变换的,就如这个游戏中,平衡的状态是多种多样的,那么我们一直跟踪这个目标就会变得困难,这时我们不妨固定住某一个曾经是目标的状态,让机器先尝试去达到这种状态,再去跟踪下一个固定目标状态,这样的方式会使得机器更容易找到目标状态。接下来我们需要创建一个样本池,神经网络会在这个样本池中进行学习,随后需要不断更新我们的样本池,当我们有一个新的

这里第一个查找第i个元素的函数,可以在之前插入与删除元素中应用,这样就不需要重复多次的写复杂的代码块,只需要每次调用GetElemt_i就可以找到我们要在那个位置进行插入操作了。这样将需要多次重复使用的代码块单独拿出来写作一个函数,再有其他函数进行调用的方式叫做“封装”,这样既便于代码的编写,也利于后期维护。本文由博客一文多发平台。
所以,对于出版社,我选取了出版社的平均评分和出版社在这个表格中出现的频率作为出版社的评价指标。此外,选择了前40000条数据作为训练集,考虑到运算的时间成本,后续只选择了剩下20000条数据中的五千条作为测试集。由于数据规模庞大,选择在一批数据进行训练得到损失值后,再进行一次参数更新,每批次选择32个数据。选择5000个数据,将他们放入模型中,计算出他们与真实结果的偏差的和,并求出平均偏差。基于给
基于给定数据集,进行数据预处理,搭建以LSTM为基本单元的模型,以Adam优化器对模型进行训练,使用训练后的模型进行预测并计算预测分类的准确率。IMDB数据集是一个对电影评论标注为正向评论与负向评论的数据集,共有25000条文本数据作为训练集,25000条文本数据作为测试集。首先,对于创建词汇表,记录每一个单词出现的频率,并由此将特征数据集转为特征向量。将测试集的内容导入并做和训练集一样的预处理,
这里采用回归模型,既y=x*weight1+bias1,设置的学习率为0.0006,损失函数采用了MSE(均方误差)2、读取数据后,对x数据进行标准化处理,以便于后续训练的稳定性,并转换为tensor格式。由于数据量较少,所以将整个训练集作为测试集,观察生成的图像。1、首先对数据进行读取和预处理。3、接下来设置训练参数和模型。本文由博客一文多发平台。
所以,对于出版社,我选取了出版社的平均评分和出版社在这个表格中出现的频率作为出版社的评价指标。此外,选择了前40000条数据作为训练集,考虑到运算的时间成本,后续只选择了剩下20000条数据中的五千条作为测试集。由于数据规模庞大,选择在一批数据进行训练得到损失值后,再进行一次参数更新,每批次选择32个数据。选择5000个数据,将他们放入模型中,计算出他们与真实结果的偏差的和,并求出平均偏差。基于给
基于给定数据集,进行数据预处理,搭建以LSTM为基本单元的模型,以Adam优化器对模型进行训练,使用训练后的模型进行预测并计算预测分类的准确率。IMDB数据集是一个对电影评论标注为正向评论与负向评论的数据集,共有25000条文本数据作为训练集,25000条文本数据作为测试集。首先,对于创建词汇表,记录每一个单词出现的频率,并由此将特征数据集转为特征向量。将测试集的内容导入并做和训练集一样的预处理,
基于给定数据集,进行数据预处理,搭建以LSTM为基本单元的模型,以Adam优化器对模型进行训练,使用训练后的模型进行预测并计算预测分类的准确率。IMDB数据集是一个对电影评论标注为正向评论与负向评论的数据集,共有25000条文本数据作为训练集,25000条文本数据作为测试集。首先,对于创建词汇表,记录每一个单词出现的频率,并由此将特征数据集转为特征向量。将测试集的内容导入并做和训练集一样的预处理,