




- @qq_62351557
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文详细解析了基于RNN的Encoder-Decoder模型核心逻辑与实现。Encoder将输入序列压缩为固定维度的隐藏状态(如"我爱中国"→语义向量),Decoder则基于该状态逐步生成目标序列(如"I love China")。文章通过参数定义、网络层设计、前向传播流程的拆解,配合完整代码实现,展示了编码器如何通过词嵌入和GRU处理序列,解码器如何结合历史信息预测下一个单词。该架构适用于机器翻

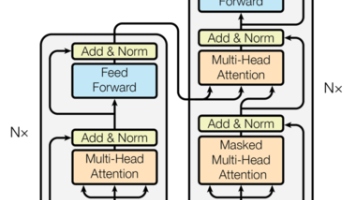
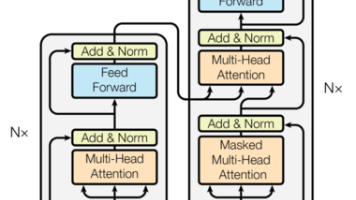
了解Transformer背景。
本文介绍了PyTorch的基本操作,重点讲解了张量的创建、形状调整、索引切片和数学运算。PyTorch凭借动态计算图的灵活性、与Python生态的无缝衔接以及在NLP领域的优势,成为深度学习的重要工具。文章通过代码示例展示了如何创建张量、调整形状、进行数学运算等核心操作,帮助读者快速掌握PyTorch的基础知识。

在真实NLP项目开发里,结合该项目架构,推荐按从底层到上层、从基础到业务的顺序编码,保障架构清晰与功能验证顺畅:先编写`utils.py`实现通用工具函数,构建`data`目录的数据加载逻辑;接着在`models/bert.py`定义BERT模型结构;再于`train_eval.py`写训练和评估逻辑,验证模型效果;之后用`run.py/run1.py`封装训练入口、`predict.py`实现推

2018 年凭借 BERT 一战成名的 Transformer,凭啥干掉 LSTM 成为 NLP 顶流?本文带你扒一扒这个能并行训练、长文本理解超给力的模型架构,从诞生背景到编码器、解码器的 “五脏六腑” 全解析,看它如何撑起机器翻译、文本生成等 NLP 半壁江山。
本文深入解析了基于GRU的RNN模型中输入输出维度变化过程。首先介绍了编码器结构,包含词嵌入层和GRU层输入数据初始形态为(batch_size, seq_len),经过词嵌入层后变为(batch_size, seq_len, hidden_size)。GRU层处理时,输出output保持相同维度,而hidden状态的维度为(1, batch_size, hidden_size)。文章通过表格清晰

`MyDataset`这货,堪称PyTorch的“文本翻译机”——专把人类话儿转成模型能啃的张量。出身自带光环:继承`Dataset`名门,会三招绝活:- `__init__`:先把文本对(比如英→法)打包存好,数清楚有多少份;- `__len__`:报个数,让`DataLoader`知道得跑几趟;- `__getitem__`:核心操作!给单词发“数字身份证”(用词表转索引),贴个“结束贴”(E

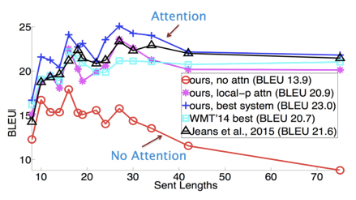
把注意力机制比作“查词典”,绝了!步骤超简单:先给词典贴标签(Key/Value),再明确查啥(Query),接着算相关度,最后按权重抓重点。为啥比传统模型牛?就像人翻译时会盯着关键句,它也能“抓大放小”,翻译更准。说白了,这机制就是让AI学会“有重点地看”——够直接,够形象吧?
