- @qq_51352130
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文认为原始的Detr系列论文中:可学习的object queries仅仅是给model预测box提供了锚点(中心点)信息,却没有提供box的宽和高信息。于是本文考虑引入可学习的动态锚框来使model能够适配不同尺寸的物体,深刻地揭示了 Decoder query 的具体意义,并加速网络的收敛。

为解决DETR attention的计算量大导致收敛速度慢、小目标检测效果差的问题:提出了,其注意力模块只关注一个query周围的少量关键采样点集,采样点的位置并非固定,而是可学习的(如左图所示,DETR的query要和其他所有的key计算相似度计算量为token的平方, 而Deformable DETR只关注周围少量的key,大大减少了计算量,提高了收敛速度),并采用了多尺度策略提高了小物体的检

文章目录 前景预测器和交叉注意力图(DAM) Sparse DETR 通过以下方式改进了DETR: 稀疏注意力:Sparse DETR 优化了交叉注意力机制,使其仅关注图像中可能包含目标的区域,而不是整个图像。这减少了计算量和提高了效率。前景预测器的监督:Sparse DETR 特别关注前景目标的预测。它通过解码器的交叉注意力图(DAM,Decoder’s Cross-Attention Map

DETR全称是Detection Transformer,是首个基于Transformer的端到端目标检测网络,最大的特点就是不需要预定义的先验anchor,也不需要NMS的后处理策略(少了这两部分可以少很多的超参数和计算),用集合的思想回归出100个query之后再用匈牙利算法二分图匹配的方式得到最终的正样本和负样本,第一个实现了端到端的目标检测。

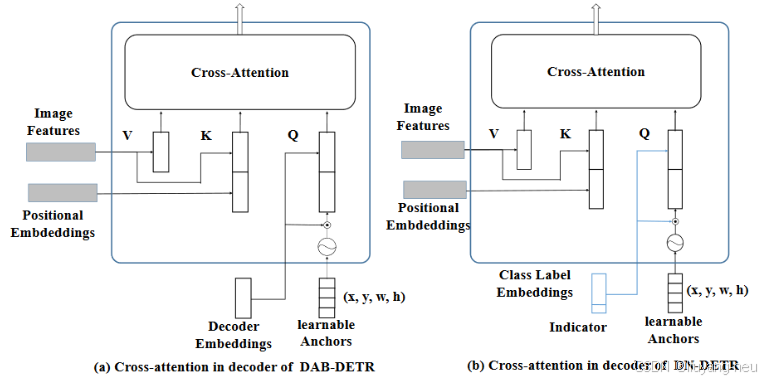
接着我们取3个batch中最大的target的数量,在这里为9,由于group=5,所有5X9=45,构造噪声query的结构为【3,45,256】,这里注意256的最后一维为indicator标识,值为1,代表噪声。在DAB-Detr的基础上,进一步分析了Detr收敛速度慢的原因:二分图匹配的不稳定性(也就是说它的目标在频繁地切换,特别是在训练的早期),导致早期训练阶段的优化目标不一致(一个qu
为解决DETR attention的计算量大导致收敛速度慢、小目标检测效果差的问题:提出了,其注意力模块只关注一个query周围的少量关键采样点集,采样点的位置并非固定,而是可学习的(如左图所示,DETR的query要和其他所有的key计算相似度计算量为token的平方, 而Deformable DETR只关注周围少量的key,大大减少了计算量,提高了收敛速度),并采用了多尺度策略提高了小物体的检
DETR全称是Detection Transformer,是首个基于Transformer的端到端目标检测网络,最大的特点就是不需要预定义的先验anchor,也不需要NMS的后处理策略(少了这两部分可以少很多的超参数和计算),用集合的思想回归出100个query之后再用匈牙利算法二分图匹配的方式得到最终的正样本和负样本,第一个实现了端到端的目标检测。
本文认为原始的Detr系列论文中:可学习的object queries仅仅是给model预测box提供了锚点(中心点)信息,却没有提供box的宽和高信息。于是本文考虑引入可学习的动态锚框来使model能够适配不同尺寸的物体,深刻地揭示了 Decoder query 的具体意义,并加速网络的收敛。
接着我们取3个batch中最大的target的数量,在这里为9,由于group=5,所有5X9=45,构造噪声query的结构为【3,45,256】,这里注意256的最后一维为indicator标识,值为1,代表噪声。在DAB-Detr的基础上,进一步分析了Detr收敛速度慢的原因:二分图匹配的不稳定性(也就是说它的目标在频繁地切换,特别是在训练的早期),导致早期训练阶段的优化目标不一致(一个qu
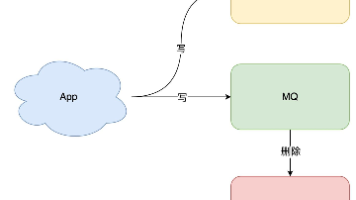
采用「先更新数据库,再删除缓存」方案,为了保证两步都成功执行,需配合「消息队列」或「订阅变更日志+MQ」的方案来做,本质是通过「重试」的方式保证数据最终一致更新数据库这一步不容易出现更新失败的情况,因为数据库事务有持久性(redo日志可以保证掉电等故障恢复)但是删除缓存容易出现问题(虽然有持久化…),容易出现断电操作失败情况,解决方式是“重试”。