
写文章




- @qq_50848391
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
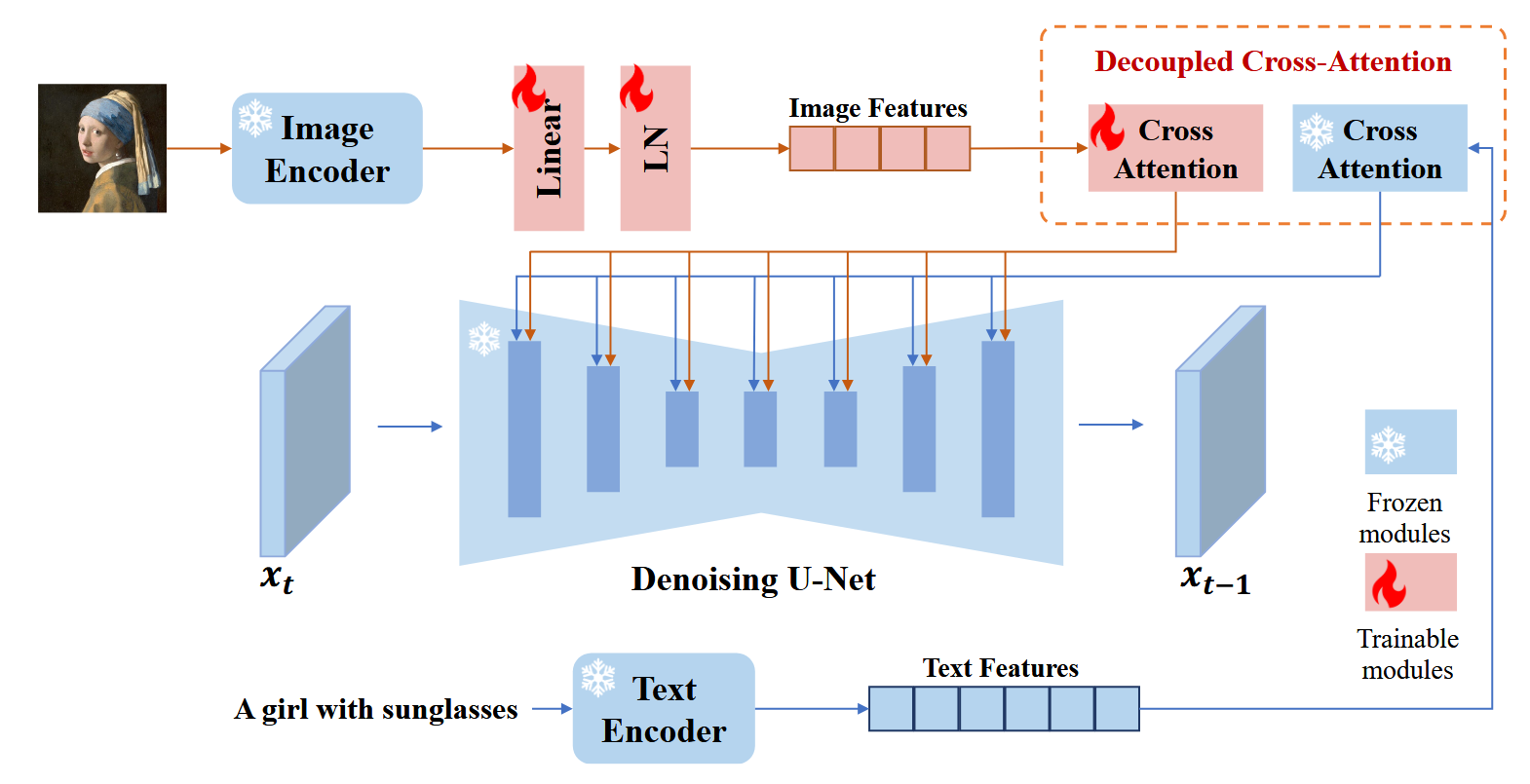
可控图像生成 论文解读 IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
其实本篇文章的核心思想和简单,就是冻结Stable Diffusion的参数,只对原Stable Diffusion结构中的CrossAttnDownBlock2D做了更改,由原来的一个TransformerBlock变成了两个(不是串联,可以理解为并联再相加),新加入的TransformerBlock与原本的TransformerBlock不同之处在于输入不同,一个是Text Embedding
可控图像生成 SeeCoder: Prompt-Free Diffusion: Taking “Text” out of Text-to-Image Diffusion Models 论文解读
这种方法已成为最受下游用户欢迎的方法之一,因为它:a) 与提示相比,将结构与内容分离可对结果进行。
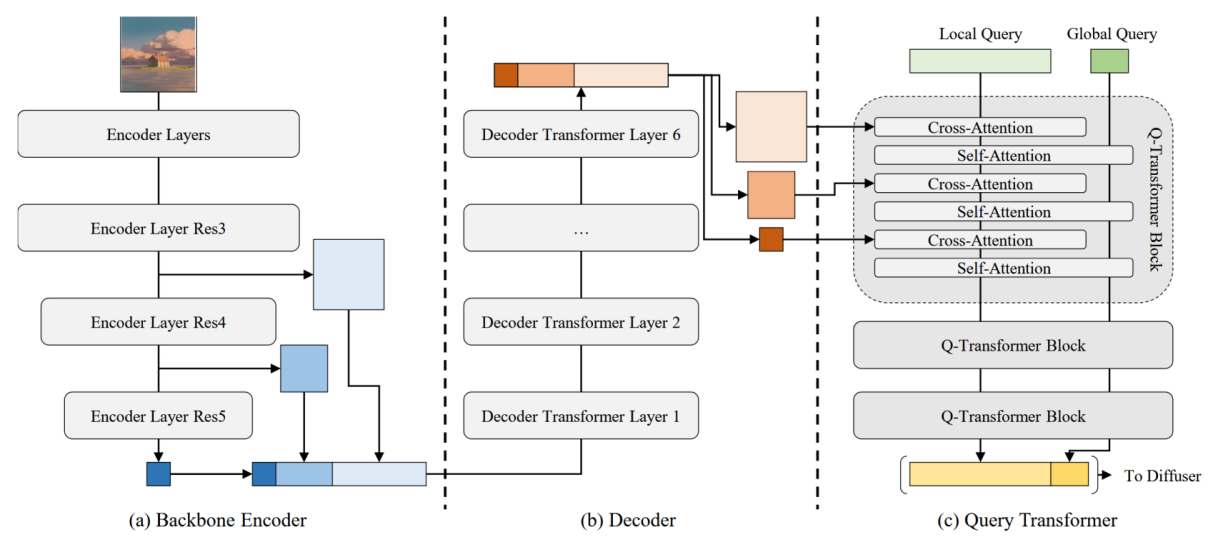
可控图像生成 SeeCoder: Prompt-Free Diffusion: Taking “Text” out of Text-to-Image Diffusion Models 论文解读
这种方法已成为最受下游用户欢迎的方法之一,因为它:a) 与提示相比,将结构与内容分离可对结果进行。
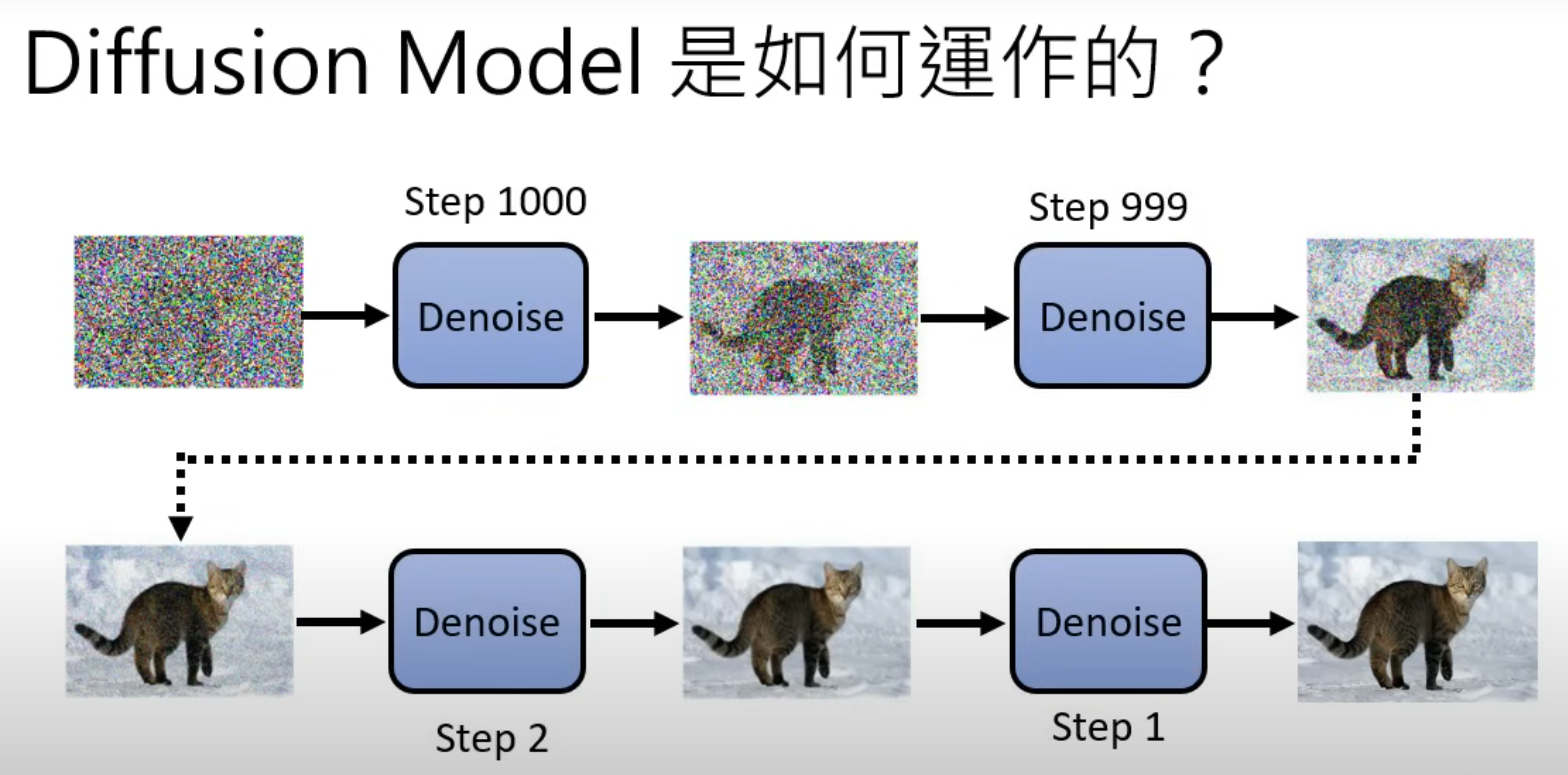
DDPM的基本原理(无公式版)
马尔可夫链定义本身比较简单,它假设某一时刻状态转移的概率只依赖于它的前一个状态。如果用精确的数学定义来描述,则假设我们的序列状态是。
到底了