




- @qq_47741012
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Debezium Server HA 能实时捕获数据库变更并投递至 Kafka、Redis、Pulsar 等下游系统
摘要:本文探讨了利用Spring AI Alibaba框架实现监督者模式,构建智能个人助理。该模式通过中心化的监督者Agent动态协调多个子Agent(如日程管理和邮件发送),克服了传统硬编码流程的局限性。监督者负责意图理解、任务拆解和动态路由,支持多步骤任务(如"安排会议并发送邮件")和条件分支(如冲突处理)。文章详细展示了如何通过Java配置定义子Agent和监督者,并演示
文章摘要: 智能体技能系统采用渐进式披露机制,通过SkillRegistry管理可复用技能。系统提示中先注入技能列表(名称和描述),当模型需要具体技能时调用read_skill加载完整内容。每个技能包含SKILL.md规范文件和可选资源目录,通过FileSystemSkillRegistry或ClasspathSkillRegistry加载。SkillsAgentHook将技能注册到系统提示,并支
文章摘要: 智能体技能系统采用渐进式披露机制,通过SkillRegistry管理可复用技能。系统提示中先注入技能列表(名称和描述),当模型需要具体技能时调用read_skill加载完整内容。每个技能包含SKILL.md规范文件和可选资源目录,通过FileSystemSkillRegistry或ClasspathSkillRegistry加载。SkillsAgentHook将技能注册到系统提示,并支
本文介绍了Spring AI Alibaba中的Multi-Agent协作方案,重点解决分布式场景下的智能体远程通信问题。通过A2A协议和Nacos注册中心,实现了智能体的服务发布、发现与负载均衡。文章详细展示了如何将本地ReactAgent发布为A2A服务,并通过客户端进行远程调用,验证了分布式环境下多个智能体实例的协同工作能力。该方案支持不同框架、不同部署环境的智能体无缝协作,为复杂业务场景提
本文介绍了Spring AI Alibaba MCP Gateway方案,实现存量Restful服务的零代码AI化改造。该网关作为中间代理层,通过Nacos动态发现存量服务,将MCP协议请求转换为对后端HTTP/Dubbo服务的调用,无需修改原有业务代码。文章详细演示了如何配置网关服务、在Nacos中定义MCP工具映射,以及改造客户端直连网关的完整流程,解决了企业存量系统AI化改造的难题,实现了协
本文探讨了如何基于Nacos服务注册中心构建Spring AI Alibaba MCP的分布式智能体应用架构。通过将MCP Server注册到Nacos实现服务发现,并开发DistributedSyncMcpClient支持多节点负载均衡,解决了单点故障问题。文章详细介绍了服务端和客户端的改造方案,包括依赖引入、Nacos配置以及分布式连接管理,并特别解决了分布式场景下的鉴权问题。该方案显著提升了
本文介绍了如何为MCP协议实现安全防护机制。首先通过自定义Header注入器在Client端自动传递Token,并在Server端使用Servlet Filter进行校验。同时配置异步支持以适配SSE长连接场景。此外,文章提出基于Spring Security实现动态工具鉴权,根据不同用户角色(如Admin/Guest)控制AI可访问的工具范围,实现"千人千面"的权限管理。这种
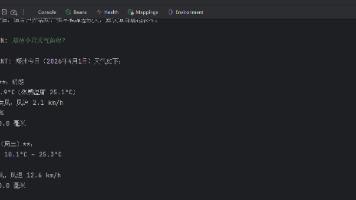
摘要:Model Context Protocol (MCP) 是一个标准化协议,使AI模型能够与外部工具交互。文章介绍如何利用Spring AI Alibaba构建MCP服务器,为AI提供实时天气查询功能。通过MCP Server封装OpenMeteo天气API,并使用@Tool注解将Java方法转化为AI可调用的工具。配置包括端口设置、协议类型和功能声明,最终实现AI应用通过MCP客户端访问天
本文提出了一种增强RAG系统的个性化闭环方案,通过引入长期记忆机制使AI系统能够记住用户偏好。该系统包含三个关键步骤:1)异步分析对话内容提取用户画像;2)结构化存储用户偏好信息;3)动态注入记忆到后续对话。技术实现上采用Spring AI Alibaba生态中的Store接口,支持MySQL等存储介质,通过JSON文档灵活存储用户画像数据。核心代码展示了如何异步更新用户记忆,包括提取对话上下文、