




- @qq_45831510
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了门控循环单元(GRU)模型的数学原理、代码实现和应用实例。首先,文章详细解释了GRU模型中的重置门和更新门的作用,以及如何使用这些门来控制隐藏状态的更新。接着,通过pytorch和sklearn的房价数据集,展示了如何使用GRU模型进行训练和预测。在实验中,我们发现GRU模型能够有效地捕捉数据集中的模式,并取得了良好的预测效果。

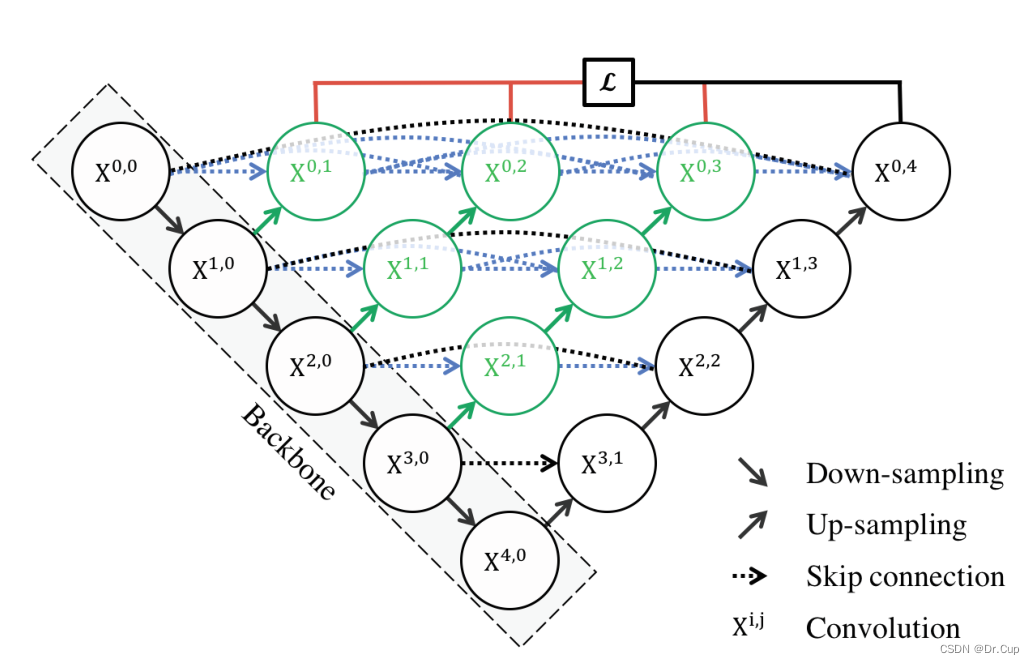
U-net++ 架构源自于 U-net,后者由欧洲核子研究组织(CERN)的研究人员于2015年提出。U-net 最初被用于生物医学图像分割,其结构类似于自编码器,具有对称的编码器和解码器部分,并通过跳跃连接将编码器和解码器层级相连接。U-net++ 在 U-net 的基础上进行了改进,主要集中在增强了特征融合的能力,通过引入多层级的特征融合模块,使得网络能够更好地捕获不同尺度下的特征信息,从而提
这篇博客详细介绍了LSTM(Long Short-Term Memory)模型的数学原理。首先,文章解释了LSTM中的关键组成部分,包括遗忘门、输入门、更新单元、细胞状态更新、输出门和隐藏状态更新。遗忘门负责决定前一时间步的细胞状态中哪些信息需要被遗忘,输入门确定要将哪些新信息加入到细胞状态中,而更新单元计算出候选的细胞状态用于更新当前时间步的细胞状态。通过这些步骤,LSTM模型能够有效地处理序列
本文介绍了双向长短期记忆网络(BiLSTM)的数学原理。首先解释了LSTM作为递归神经网络的变体,通过引入门控机制解决了传统RNN中的梯度问题。随后详细描述了LSTM的关键组成部分,包括遗忘门、输入门、更新单元状态、细胞状态更新、输出门和隐状态更新的计算过程。接着对BiLSTM进行介绍,指出其在时间序列上同时运行两个LSTM,一个前向处理,一个后向处理,最终将两者的隐藏状态连接形成最终的双向隐藏状

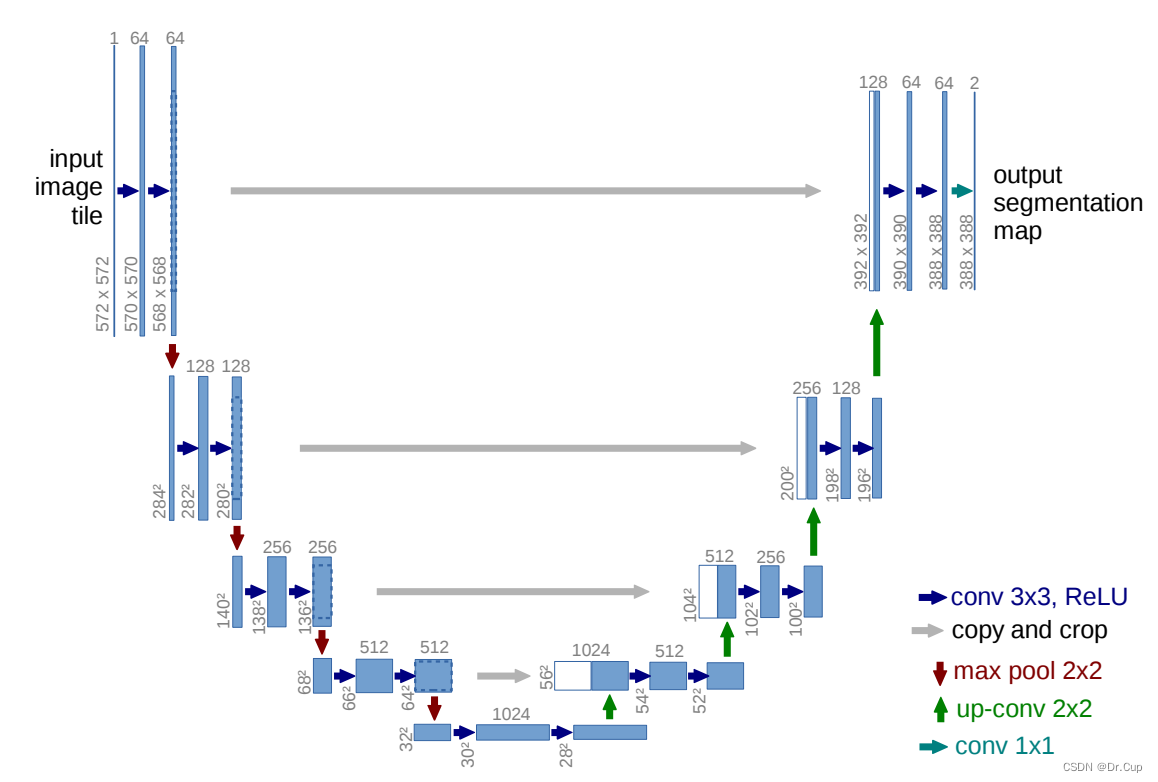
U-Net 是一种针对图像分割任务的深度学习架构,在其设计中融入了跳跃连接、对称的 U 形结构和特征信息合并等关键机制。跳跃连接允许低级特征直接传递至解码器,增加了信息传递路径,有效地缓解了信息丢失问题,有助于网络更准确地还原图像细节。对称的 U 形结构确保编码器和解码器之间的紧密联系,提高了信息传递的效率,有助于网络更好地学习图像特征。而特征信息的合并使解码器能够利用多层级特征,有效地提高了图像
本文详细介绍了多层感知机(Multilayer Perceptron, MLP)的核心数学原理,包括前向传播算法、激活函数、损失函数和反向传播算法。前向传播是多层感知机处理信息的过程,从输入层开始,经过隐藏层,最后到达输出层;激活函数用于增加神经网络的非线性;损失函数用于衡量模型预测值与真实值之间的差异;反向传播算法用于计算损失函数对每个权重的梯度,然后更新权重以最小化损失函数。此外,本文还给出了

SegNet 作为一种高效且精确的图像语义分割网络,通过其独特的结构和流程,成功地解决了许多复杂的图像分割问题,并在实际应用中取得了广泛的成功。随着深度学习技术的进一步发展,SegNet 和其衍生算法有望在未来继续推动图像分割技术的进步,为各种应用场景提供更加智能和精确的解决方案。

本文介绍了门控循环单元(GRU)模型的数学原理、代码实现和应用实例。首先,文章详细解释了GRU模型中的重置门和更新门的作用,以及如何使用这些门来控制隐藏状态的更新。接着,通过pytorch和sklearn的房价数据集,展示了如何使用GRU模型进行训练和预测。在实验中,我们发现GRU模型能够有效地捕捉数据集中的模式,并取得了良好的预测效果。
本文介绍了双向长短期记忆网络(BiLSTM)的数学原理。首先解释了LSTM作为递归神经网络的变体,通过引入门控机制解决了传统RNN中的梯度问题。随后详细描述了LSTM的关键组成部分,包括遗忘门、输入门、更新单元状态、细胞状态更新、输出门和隐状态更新的计算过程。接着对BiLSTM进行介绍,指出其在时间序列上同时运行两个LSTM,一个前向处理,一个后向处理,最终将两者的隐藏状态连接形成最终的双向隐藏状
这篇博客文章详细解释了LeNet模型的数学原理,包括卷积操作、池化操作、全连接层和激活函数等方面。在讲解卷积操作时,提到了卷积核与输入数据的逐元素相乘和相加过程;而池化操作则是对特征图进行下采样以降低数据维度。此外,全连接层通过权重矩阵和偏置向量实现线性变换,并使用tanh函数进行非线性变换。前向传播过程中涉及卷积、池化、全连接和softmax分类,反向传播用于更新模型参数以最小化损失函数。LeN