
写文章




- @qq_45061342
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
[MySQL总结] Explain详解、索引最佳优化
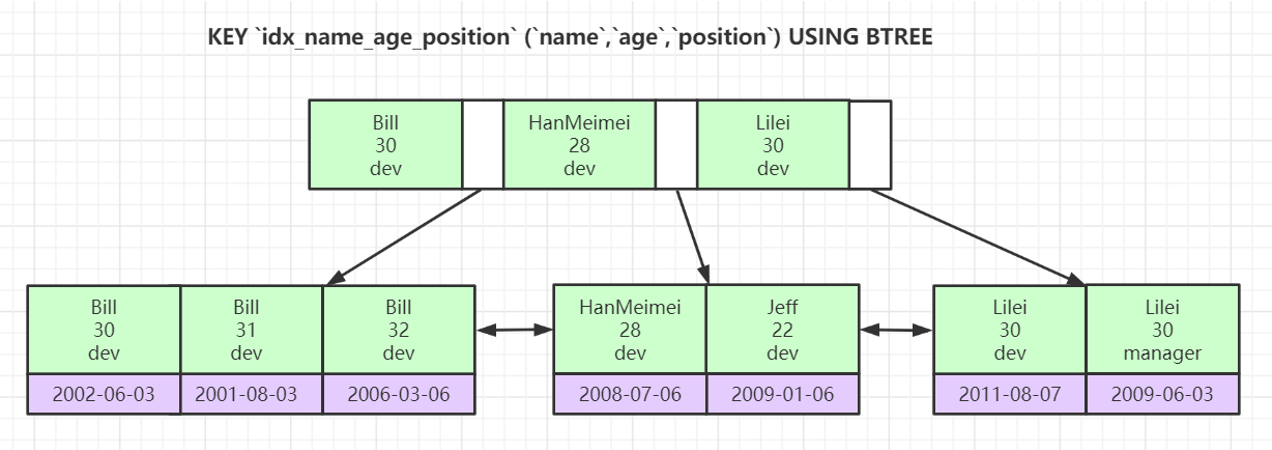
like KK%相当于=常量,%KK和%KK% 相当于范围。
Zookeeper分布式一致性协议ZAB介绍
ZAB 协议全称:Zookeeper Atomic Broadcast(Zookeeper 原子广播协议)。Zookeeper 是一个为分布式应用提供高效且可靠的分布式协调服务。在解决分布式一致性方面,Zookeeper 并没有使用 Paxos ,而是采用了 ZAB 协议,ZAB是Paxos算法的一种简化实现。ZAB 协议是为分布式协调服务 Zookeeper 专门设计的一种支持崩溃恢复和原子广播

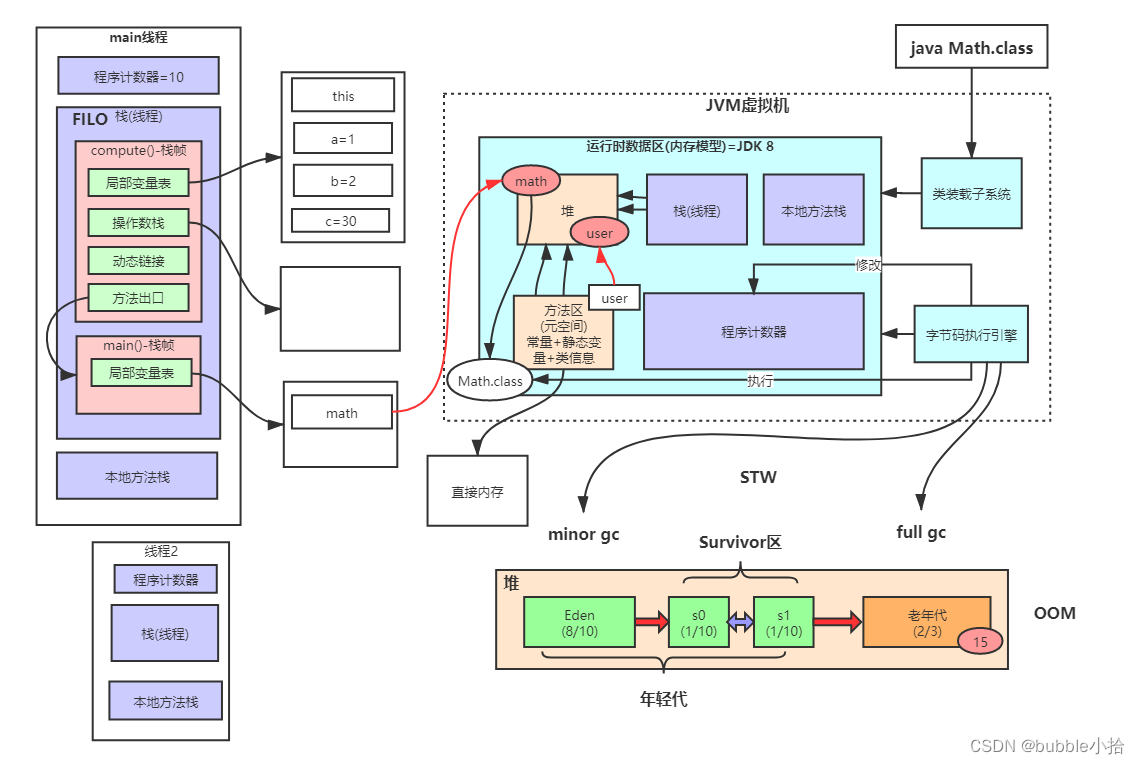
JVM内存模型剖析与参数设置
但在Java 8及以后的版本,永久代被元数据区(Metaspace)取代,元数据区是一块位于本地内存中的区域,与堆内存分开。对象在堆内部挪动的过程其实是复制,原有区域对象还在,一般不直接清理,JVM内部清理过程只是将对象分配指针移动到区域的头位置即可,比如扫描s0区域,扫到gcroot引用的非垃圾对象是将这些对象复制到s1或老年代,最后扫描完了将s0区域的对象分配指针移动到区域的起始位置即可,s0
到底了