




- @qq_43688587
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
7道经典例题有不足的地方,大家可以指出来!!!规范化的关系模式中,所有属性都必须是( )。设关系模式R属于第一范式,若在R中消除了部分函数依赖,则R至少属于( )。解析:第二范式是完全依赖,消除了部分依赖。若在R中消除了部分函数依赖,则至少属于第二范式。设关系模式R{A,B,C,D,E},其上函数依赖集F={AB→C,B→D},则R最高能达到第几范式?( )。解...
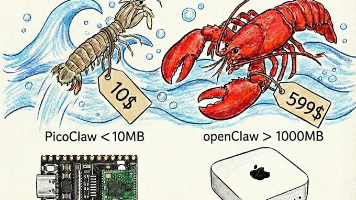
摘要 2025-2026年是"沙箱元年",OpenClaw等项目推动了本地AI Agent的发展,但系统安全问题凸显。文章分析了当前主流沙箱方案: OpenClaw展示了本地AI Agent的优势与风险,强调沙箱的必要性; 沙箱技术爆发:Manus提供VM级隔离,阿里OpenSandbox开源通用平台,LangChain集成沙箱执行; 桌面Agent涌现带来安全问题,Kimi
要分专业了,我选大数据还是人工智能?主流方向介绍1.云计算与大数据1.1 含义1.2 大数据的特性1.3 产业界的大数据架构1.4 核心课程2.软件开发与测试2.1 核心课程和特色课程3.企业信息化4.智慧城市5.人工智能5.1 介绍5.2 核心课程5.3 就业方向即将大三的我要面临分专业方向的问题,高考时就面临一次重要的选择,那次我家里人帮我选择了软件工程,这次我要自己选择喜欢,有就业前景的专业
摘要 2025-2026年是"沙箱元年",OpenClaw等项目推动了本地AI Agent的发展,但系统安全问题凸显。文章分析了当前主流沙箱方案: OpenClaw展示了本地AI Agent的优势与风险,强调沙箱的必要性; 沙箱技术爆发:Manus提供VM级隔离,阿里OpenSandbox开源通用平台,LangChain集成沙箱执行; 桌面Agent涌现带来安全问题,Kimi
2025年6月23日,百度举办AI开放日活动,重磅发布了其智能代码助手文心快码的最新突破——Comate AI IDE。这是业界首个集多模态与多智能体协同于一体的AI原生开发环境工具,首创设计稿一键转代码功能,开箱即用,为国内企业和开发者提供高效、智能、安全可靠的AI IDE。阿东也参加了开放日的活动,还在活动中取得了不错的名次!!!

百度搜索迎来十年来最大改版,升级为"智能框"支持超千字输入和多模态交互,推出"百看"功能实现结构化内容呈现,并增强AI助手能力。改版内容包括:1)搜索框升级为智能创作平台;2)搜索结果从链接转向直接满足需求;3)AI助手加入视频通话等新功能;4)接入1.8万+MCP打造国内最大AI生态;5)引入全球首个中文音视频生成模型MuseSteamer。此次变革标志着

阿东,大模型算法工程师,中科院硕士,大厂面试官。1. 合成数据的定义与优势合成数据是通过生成式AI技术或算法模拟生成的、模仿真实世界数据的数据。早在1993年,统计学家Donald Rubin便在论文中提出这一概念。随着ChatGPT等生成式AI的兴起,合成数据因其高效、低成本及可控性成为研究热点

MCP 集成,一定要看的高质量代表项目

《从CURD工程师到大模型架构师的转型之路》分享了作者三年多的AI领域转行经验。2023年接触智能客服等项目积累实战经验,2024年技术深耕并发表论文,2025年成功转型为大模型架构师。文章总结了四大核心心得:可视化理解算法、夯实经典理论基础、重视动手实践(如复现ReAct Agent)、善用开源资源(如LangChain)。特别介绍了"分层记忆大脑"项目,通过短期/长期记忆机

天下没有难学的大模型,拿sft来说一个后端同学,上手一个月就很熟悉了,rag开发亦是如此,多读论文,5分钟读一篇论文,学会利用AI工具,不懂的先问问大模型懂不懂,其中也是有很多技巧。用agent的思维,去处理一切事情,什么事情都可以🈶mult agent去组合解决的。0基础小白,研0的同学,前后端从业者可以按照我的路线,快速抓转行大模型工程or算法。转行大模型之后:字节巨量(已拒),联想(已接)
