




- @qq_43638033
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
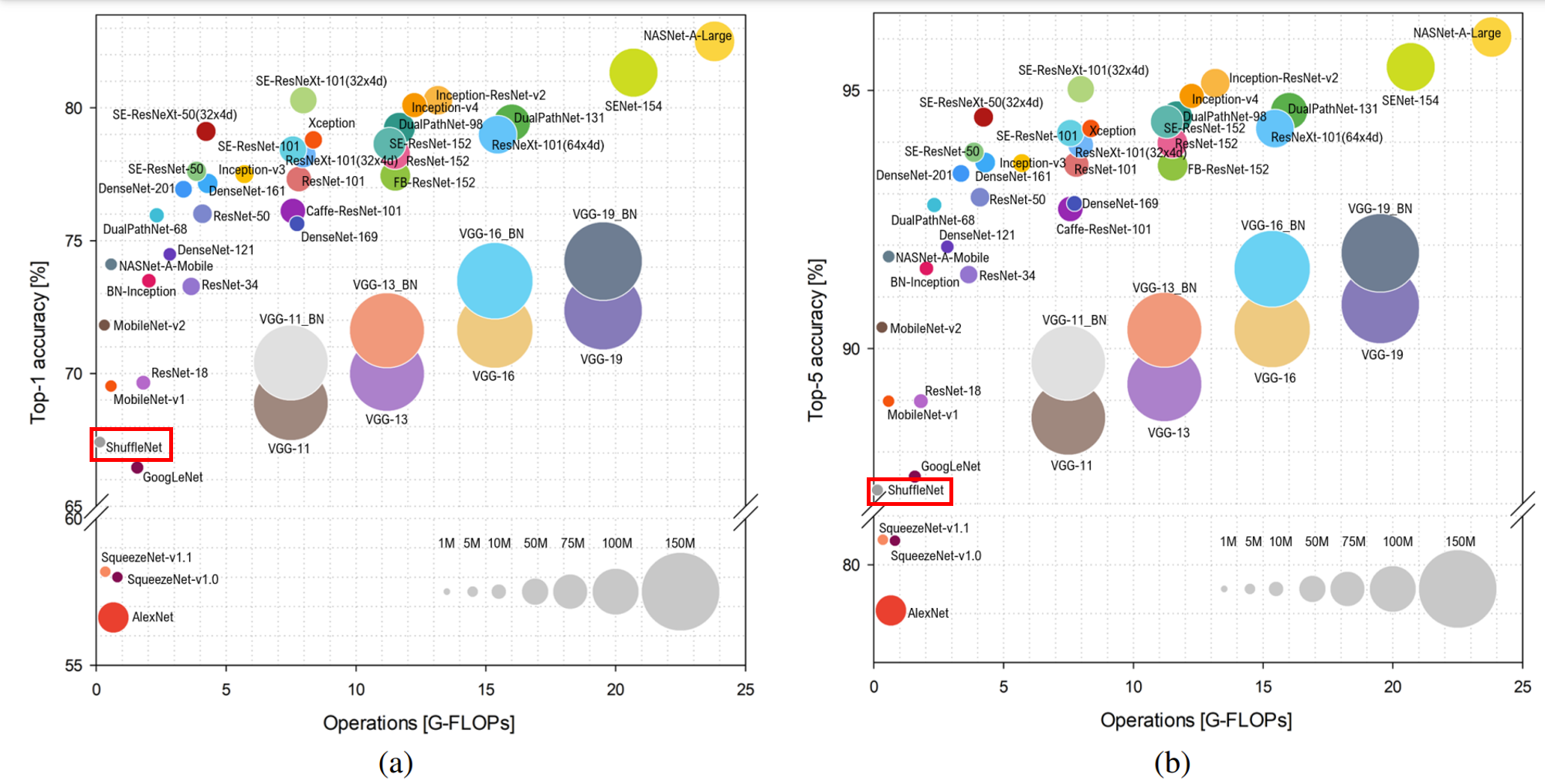
ShuffleNetV1是旷视科技提出的一种计算高效的CNN模型,和MobileNet, SqueezeNet等一样主要应用在移动端,所以模型的设计目标就是利用有限的计算资源来达到最好的模型精度。ShuffleNetV1的设计核心是引入了两种操作:Pointwise Group Convolution和Channel Shuffle,这在保持精度的同时大大降低了模型的计算量。因此,ShuffleN
在下面的教程中,我们将通过示例代码说明DCGAN网络如何设置网络、优化器、如何计算损失函数以及如何初始化模型权重。在本教程中,使用的共有70,171张动漫头像图片,图片大小均为96*96。

MobileNet网络是由Google团队于2017年提出的,专注于移动端、嵌入式或IoT设备的轻量级CNN网络。相比于传统的卷积神经网络,MobileNet网络使用深度可分离卷积(Depthwise Separable Convolution)的思想,在准确率小幅度降低的前提下,大大减小了模型参数与运算量。同时引入宽度系数 α和分辨率系数 β,使模型满足不同应用场景的需求。

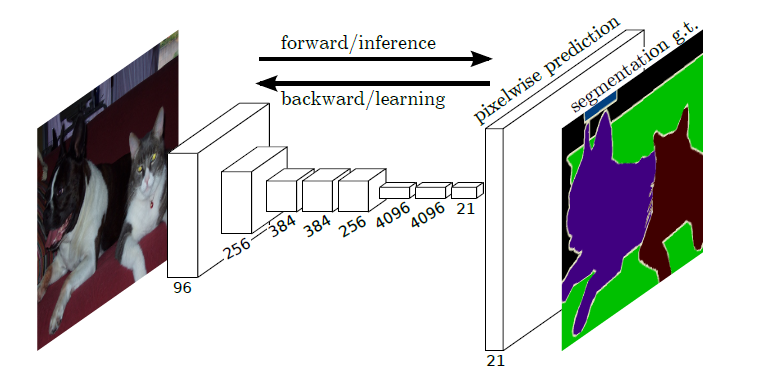
全卷积网络(Fully Convolutional Networks,FCN)是UC Berkeley的Jonathan Long等人于2015年在Fully Convolutional Networks for Semantic Segmentation[1]一文中提出的用于图像语义分割的一种框架。FCN是首个端到端(end to end)进行像素级(pixel level)预测的全卷积网络。在
如果将Diffusion与其他生成模型(如Normalizing Flows、GAN或VAE)进行比较,它并没有那么复杂,它们都将噪声从一些简单分布转换为数据样本,Diffusion也是从纯噪声开始通过一个神经网络学习逐步去噪,最终得到一个实际图像。我们选择的固定(或预定义)正向扩散过程 q𝑞 :它逐渐将高斯噪声添加到图像中,直到最终得到纯噪声一个学习的反向去噪的扩散过程 pθ𝑝𝜃 :通过训

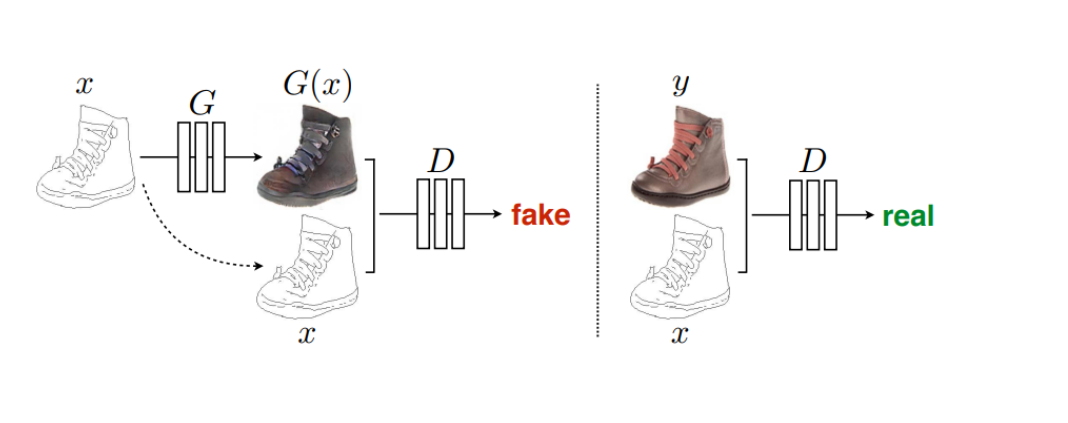
生成式对抗网络(Generative Adversarial Networks,GAN)是一种生成式机器学习模型,是近年来复杂分布上无监督学习最具前景的方法之一。最初,GAN由Ian J. Goodfellow于2014年发明,并在论文生成器的任务是生成看起来像训练图像的“假”图像;判别器需要判断从生成器输出的图像是真实的训练图像还是虚假的图像。GAN通过设计生成模型和判别模型这两个模块,使其互相
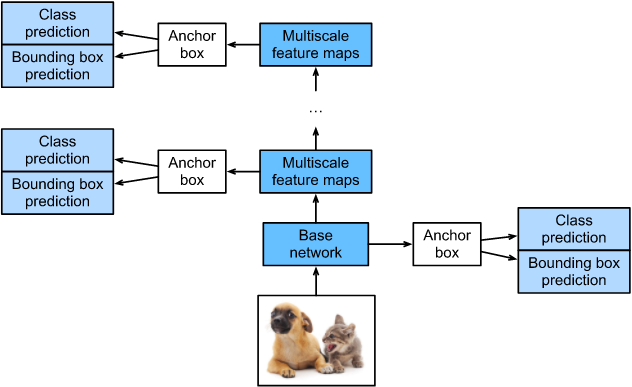
SSD,全称Single Shot MultiBox Detector,是Wei Liu在ECCV 2016上提出的一种目标检测算法。使用Nvidia Titan X在VOC 2007测试集上,SSD对于输入尺寸300x300的网络,达到74.3%mAP(mean Average Precision)以及59FPS;对于512x512的网络,达到了76.9%mAP ,超越当时最强的Faster R
import mindspore # 导入MindSpore库import mindspore.nn as nn # 导入MindSpore的神经网络模块import mindspore.ops as ops # 导入MindSpore的操作模块# 定义U-Net跳跃连接块super(UNetSkipConnectionBlock, self).__init__() # 调用父类构造函数# 定义归
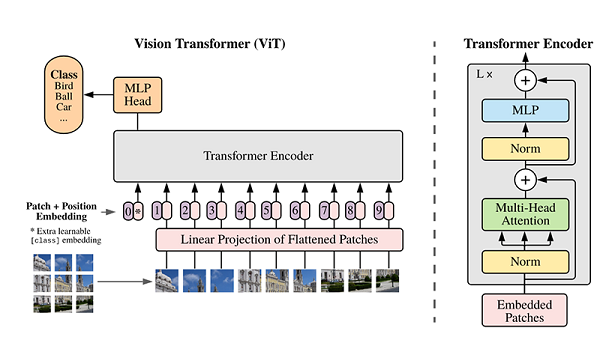
本案例完成了一个ViT模型在ImageNet数据上进行训练,验证和推理的过程,其中,对关键的ViT模型结构和原理作了讲解。通过学习本案例,理解源码可以帮助用户掌握Multi-Head Attention,TransformerEncoder,pos_embedding等关键概念,如果要详细理解ViT的模型原理,建议基于源码更深层次的详细阅读。
这段代码通过从训练数据集中提取前4张图像及其标签,并进行反标准化处理后,使用matplotlib将图像显示出来,同时在每张图像上方显示对应的类别名称。这有助于可视化和验证数据预处理以及数据集加载是否正确。这段代码旨在为神经网络中的权重和BatchNorm层的γ参数提供初始化方法。通过使用MindSpore的Normal初始化器,可以确保权重和γ参数按照指定的正态分布进行初始化,从而有助于稳定和加速
