




- @qq_43592352
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
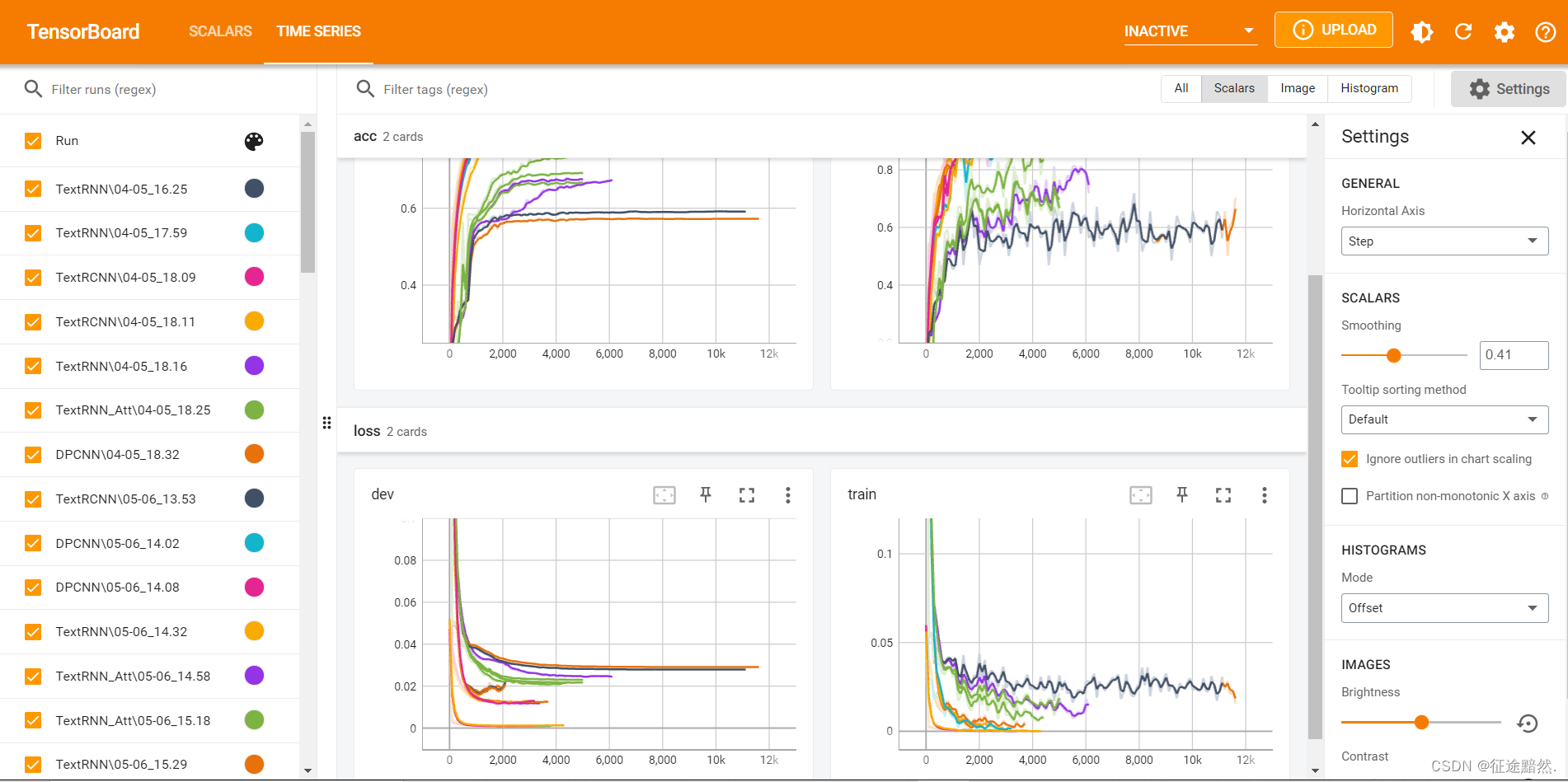
执行上述代码后在本文件更目录下生成一个logs文件,且包含了一个事件文件。[2.1]安装pytorch和tensorboard。[2.3]打开tensorboard面板。输入命令后,会生成一个地址,访问即可。[2.2]在代码中使用write。...
【注】·本文为转载文章,原文作者是王树义老师,原文链接为 https://zhuanlan.zhihu.com/p/71961236训练集、验证集和测试集,林林总总的数据集合类型,到底该怎么选、怎么用?看过这篇教程后,你就能游刃有余地处理它们了。问题审稿的时候,不止一次,我遇到作者错误使用数据集合跑模型准确率,并和他人成果比较的情况。他们的研究创意有的很新颖,应用价值较高,工作可能也做了着实不少。
日常工作中经常用到sparkui来排查一些问题,有些东西需要经常搜索,网上的文章有写的很棒的,也有写的一言难尽的,这里参考了其他大佬的文章,自己整体梳理了一下,方便自己使用,也希望能帮助到大家~

作者讲的太好了,一看就是在业务上摸爬滚打很多年的资深算法。内容介绍一、爆发的三要素二、深度学习。

例如对于某个样本来说,其真实标签为[0,1,0,1],预测标签为[0,1,1,0]。那么该样本对应的精确率就应该为2*(0+1+0+0)/((1+1)+(1+1))=0.5。例如对于某个样本来说,其真实标签为[0,1,0,1],预测标签为[0,1,1,0]。例如对于某个样本来说,其真实标签为[0,1,0,1],预测标签为[0,1,1,0]。例如对于某个样本来说,其真实标签为[0,1,0,1],预测

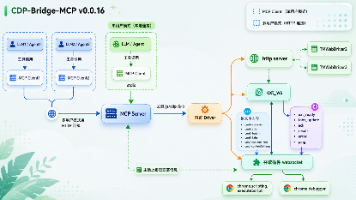
痛点:公司旧版 ERP/CRM 系统没有 API,或者 API 文档缺失,但员工每天需要手动录入大量数据。方案:部署 CDP Bridge 在内网。开发一个内部 Agent,员工只需对 Agent 说:“把这份 Excel 里的客户信息录入到 CRM 系统。效果:Agent 控制员工的浏览器,自动点击、填充表单、提交。无需改造老旧系统,即可实现 RPA 级别的自动化。
日常工作中经常用到sparkui来排查一些问题,有些东西需要经常搜索,网上的文章有写的很棒的,也有写的一言难尽的,这里参考了其他大佬的文章,自己整体梳理了一下,方便自己使用,也希望能帮助到大家~
作者讲的太好了,一看就是在业务上摸爬滚打很多年的资深算法。内容介绍一、爆发的三要素二、深度学习。
执行上述代码后在本文件更目录下生成一个logs文件,且包含了一个事件文件。[2.1]安装pytorch和tensorboard。[2.3]打开tensorboard面板。输入命令后,会生成一个地址,访问即可。[2.2]在代码中使用write。...
连连看html游戏全代码js、jquery操作运行图片目录路径连连看水果方块版.html连连看算法进行下一个游戏的开发!注意事项我会把html文件、css文件提供下载地址,文件夹路径也展示给大家。但是图片就不给大家了,毕竟博主辛辛苦苦做出来的游戏。但是我其实是很愿意给那些为了自己锻炼而需要参考我的代码的同志们。所以,大家有需要的话,加博主QQ:2864144286,全天在线,博主绝不吝啬。...