




- @qq_43510916
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
每一个方恪表示迷宫中的一个房间。罗密欧位于迷宫的(p,q)方格中,他必须找出一条通向朱丽叶所在的(r,s)格的路,在朱丽叶方格之前,他必须走遍所有未封闭的房间各一次,而且要使到达朱丽叶方格的转弯次数为最少。将计算出的罗密欧通向朱丽叶的最少转弯次数和有多少条不同的最少转弯道路。第一行有3个正整数n,m,k,分别表示迷宫的行数,列数和封闭的房间数。接下来的k行中,每行2个正整数,表示被封闭的房间所在的

在博客【Hadoop】MapReduce原理剖析(Map,Shuffle,Reduce三阶段)中已经分析了MapReduce的运行过程,以及部分原理。那么这篇博客则是进行一次实践,使用MapReduce统计文本中的单词数量。实际上我们只需要写Mapper和Reducer部分的代码即可,最后在Main中进行一些设置即可。
由Experience Replay返回当前状态作为Q网络输入,Q网络使用随机初始化后的参数得到当前状态下可以采用的所有动作所对应的Q值,并按照ε-greedy策略选择要执行的动作输出给Experience Replay,其得到动作后与环境进行交互并得到下一状态以及奖励,并将这一系列数据作为训练数据与第一步产生的部分数据进行存储。在已存储数据中随机选择一批训练数据(S1,a4, R1, S2),将
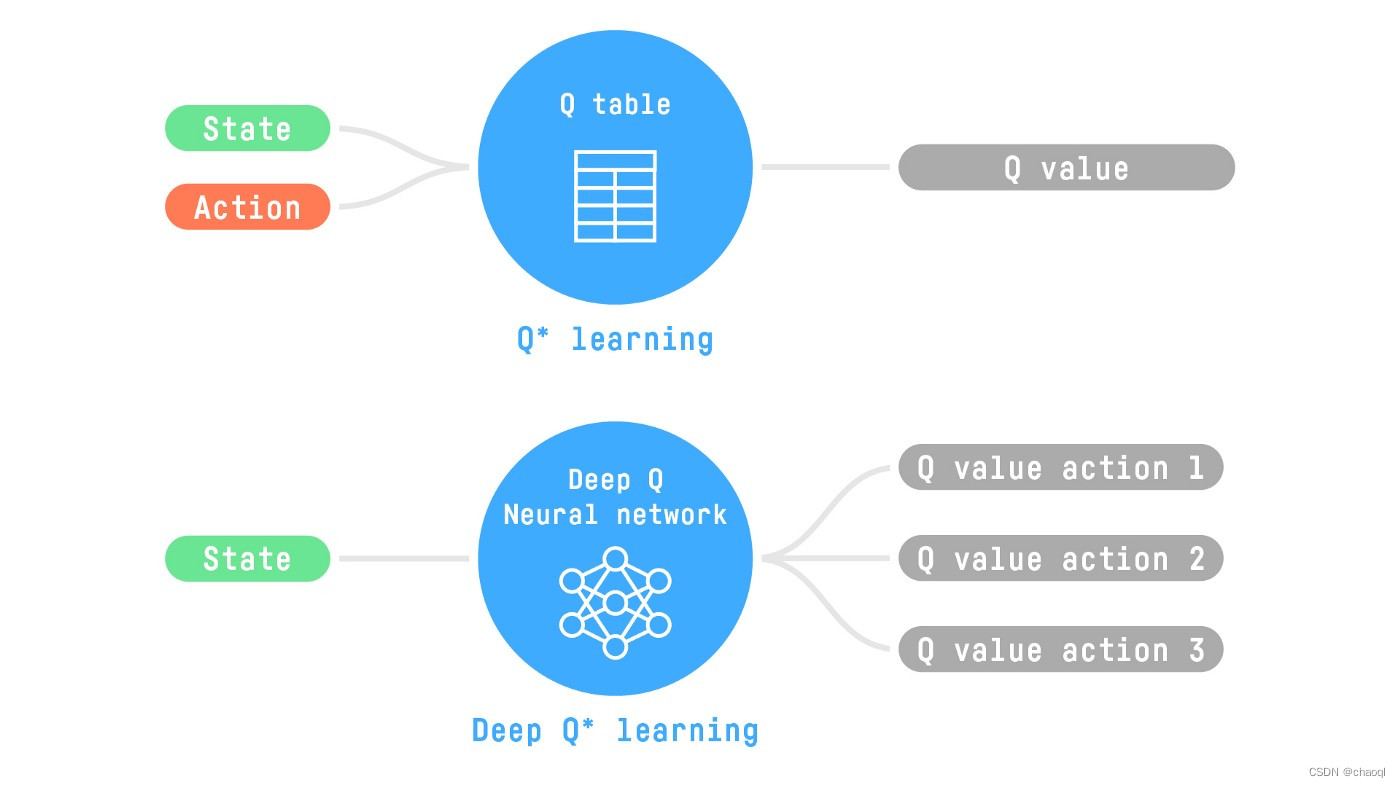
由Experience Replay返回当前状态作为Q网络输入,Q网络使用随机初始化后的参数得到当前状态下可以采用的所有动作所对应的Q值,并按照ε-greedy策略选择要执行的动作输出给Experience Replay,其得到动作后与环境进行交互并得到下一状态以及奖励,并将这一系列数据作为训练数据与第一步产生的部分数据进行存储。在已存储数据中随机选择一批训练数据(S1,a4, R1, S2),将
题目背景小晨的电脑上安装了一个机器翻译软件,他经常用这个软件来翻译英语文章。题目描述这个翻译软件的原理很简单,它只是从头到尾,依次将每个英文单词用对应的中文含义来替换。对于每个英文单词,软件会先在内存中查找这个单词的中文含义,如果内存中有,软件就会用它进行翻译;如果内存中没有,软件就会在外存中的词典内查找,查出单词的中文含义然后翻译,并将这个单词和译义放入内存,以备后续的查找和翻译。假设内...
1.1题目算法实现题3-2 最少硬币问题★问题描述:设有n种不同面值的硬币,各硬币的面值存于数组T[1:n]中,现要用这些面值的硬币来找钱。可以使用的各种面值的硬币个数存于数组 Coins[l:n]中。对任意钱数0≤m≤20 001,设计一个用最少硬币找钱m的方法。★算法设计:对于给定的1≤n≤10,硬币面值数组T和可以使用的各种面值的硬币个数数组 Coins,以及钱数m,0≤m≤20 0...
目录实验要求实验环境ChatCode1.graph.h2.test.cpp实验要求 基于邻接表存储结构实现有向图的典型操作(构造、析构、增加顶点、删除顶点、增加弧、删除弧,查找一个 顶点、判空、判满、图中顶点个数、邻接表中指定顶点的第一个邻接顶点、深度优先遍历、广度优先遍历),测试和调试程序。实验环境visual s
注意:格式化操作只能执行一次,如果格式化的时候失败了,可以修改配置文件后再执行格式化,如果格式化成功了就不能再重复执行了,否则集群就会出现问题。hadoop集群就会使用到ssh,我们在启动集群的时候只需要在一台机器上启动就行,然后hadoop会通过ssh连到其它机器,把其它机器上面对应的程序也启动起来,为了不用每次输入密码,所以现在需要实现ssh免密码登录。集群只要涉及到多个节点的就需要对这些节点

梯度下降法求解线性回归参数对于一元线性函数:y(x,w)=w0+w1xy ( x , w ) = w _ { 0 } + w _ { 1 } xy(x,w)=w0+w1x定义其平方损失函数为:f=∑i=1n(yi−(w0+w1xi))2f = \sum _ { i = 1 } ^ { n } \left( y _ { i } - \left( w _ { 0 } + w _ { 1 } x _
文章目录距离度量曼哈顿距离欧氏距离最近邻算法K-近邻算法算法实现决策规则KNN算法实现测试数据丁香花分类加载数据集训练测试数据划分训练模型模型预测准确率计算K 值选择距离度量曼哈顿距离曼哈顿距离又称马氏距离,是计算距离最简单的方式之一。公式如下:dman=∑i=1N∣Xi−Yi∣d_{man}=\sum_{i=1}^{N}\left | X_{i}-Y_{i} \right | dman=i=1