




- @qq_43214331
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
随机森林算法类型随机森林算法:属于集成学习算法,通俗点讲,就是将多颗决策树集合起来,就变成了随机森林。随机森林包含了回归森林和分类森林,因此随机森林既可以解决分类问题,可以解决回归问题集成学习算法集成学习算法是通过训练多个学习器,然后把这些学习器组合起来,以达到更好的预测性能的目的。集成学习算法的分类Bagging:弱学习器的生成没有先后顺序,可以进行并行训练,如果是分类任务,则预测结果为多个弱学

K-means算法的类型与介绍K- means算法的类型无监督学习的聚类算法;聚类算法是无监督的一种算法、K-means是一种聚类算法;K-means算法的介绍K-means算法的定义所谓聚类问题,就是给定一个元素集合D,其中每个元素具有n个可观察属性,使用某种算法将D划分成K个子集,要求每个子集内部的元素之间相似度尽可能的高,而不同子集的元素相似度尽可能的低。其中每个子集叫做一个簇。聚类目的:类

线性回归算法的类型有监督学习的回归算法【标签是连续数据类型】线性回归基础研究父子身高关系研究父辈身高(自变量x)如何决定子辈身高(因变量y)建立方程表征关系:y = kx+b-------------这个方程是 回归方程什么是线性?什么是线性回归方程 什么是非线性回归方程?①y = kx+b ②y=$a_1x_1^2+a_2x_2^2 + c$ ③ $y = a_1x_1+a_2x_2 + c$①

需要标准化KNN、K-means、线性回归【SGD、岭回归、套索回归】、逻辑回归、不需要标准化朴素贝叶斯、线性回归【正规方程】、决策树、随机森林、xgboost什么时候标准化规范的流程:先拆分、后标准化原因:在训练集上寻找对应的标准化参数【标准差标准化寻找 均值、标准差; 离差标准化 寻找 最小值 最大值;小数定标标准化 寻找 绝对值最大的数】;之后在训练集和测试集进行转换...
需要标准化KNN、K-means、线性回归【SGD、岭回归、套索回归】、逻辑回归、不需要标准化朴素贝叶斯、线性回归【正规方程】、决策树、随机森林、xgboost什么时候标准化规范的流程:先拆分、后标准化原因:在训练集上寻找对应的标准化参数【标准差标准化寻找 均值、标准差; 离差标准化 寻找 最小值 最大值;小数定标标准化 寻找 绝对值最大的数】;之后在训练集和测试集进行转换...
朴素贝叶斯算法的类型有监督学习的分类算法朴素贝叶斯算法的原理基于贝叶斯理论和特征相互独立的假设;因为假定特征相互独立让问题变的简单,因为称为朴素朴素贝叶斯算法分为:伯努利朴素贝叶斯,高斯朴素贝叶斯,多项式朴素贝叶斯。篇幅较长,可根据旁边的目录来看朴素贝叶斯算法第一站:概率公式条件概率公式:为(即在事件B发生的情况下,事件A发生的概率):当A,B相互独立时P(AB) = P(A)∗P(B)全概率公式
一、xgboost是否需要对数据进行归一化首先,归一化是对连续特征来说的。所以连续特征的归一化,起到的主要作用是进行数值缩放。数值缩放的目的是解决梯度下降时,等高线是椭圆导致迭代次数增多的问题。而xgboost等树模型是不能进行梯度下降的,因为树模型是阶越的,不可导。树模型是通过寻找特征的最优分裂点来完成优化的。由于归一化不会改变分裂点的位置,因此xgboost不需要进行归一化。二、xgboost
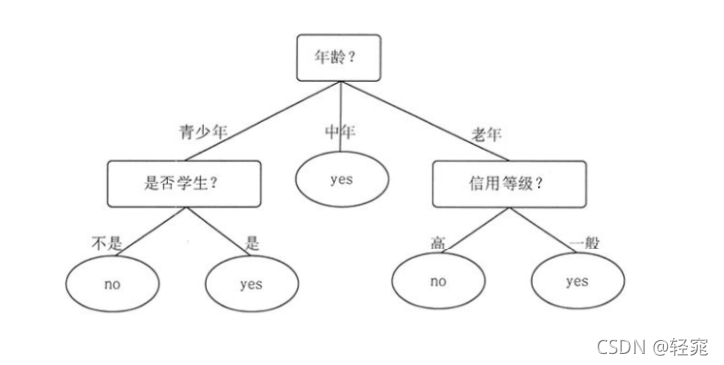
决策树算法类型决策树是一系列算法,而不是一个算法。决策树包含了 ID3分类算法,C4.5分类算法,Cart分类树算法,Cart回归树算法。决策树既可以做分类算法,也可以做回归算法。因此决策树既可以解决分类问题,也可以解决回归问题。一般来讲,在决策树中,根节点和分节点使用方块表示,而叶子节点使用椭圆表示。决策树的关键点在于如何取建立出一个树,如何建立出一个在可以达成目标的前提下深度最浅的树决策树中不
在使用机器学习模型之前,通常我们会对数据进行预处理,来消除noise、提升模型表现。通常根据不同模型的不同性质,需要进行的预处理也不尽相同。那么,对于当下数据分析竞赛中非常火的XGBoost来说,转化为正态分布、去除极端值、Normalization等数据预处理是否有必要呢?本文就来具体地分析一下。一、XGBoost需要去除异常值异常值是现实生活中不太可能取到的值,通常是人为原因导致的数据记录错误
MySQL的安装和配置
