




- @qq_43128256
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
YOLO在标准基准测试中,World 的速度和效率超过了现有的开放词汇检测器,包括 MDETR 和 GLIP 系列,展示了YOLOv8 在单个 NVIDIA V100 GPU 上的卓越性能。YOLO属于经典的传统AI模型,即经过有监督的训练后,模型学习到特征与标签间的关联关系,可对图像、视频中出现的物体进行特征检测,负荷已知特征的物体图像会被打上标签和置信度。:利用 CNN 的计算速度,YOLO-

OpenCompass,也称为“司南”,是由上海人工智能实验室发布的一个开源的大模型评测体系,已经成为目前权威的大型模型评估平台。作为一站式的大模型评估平台,它不仅量化了模型在知识、语言、理解、推理等方面的能力,还推动了模型的迭代和优化。其主要特点包括:对模型和数据集支持丰富:支持20+HuggingFace和API模型,70+数据集的模型评估方案,约40万个问题,从五个维度全面评估模型的能力分布
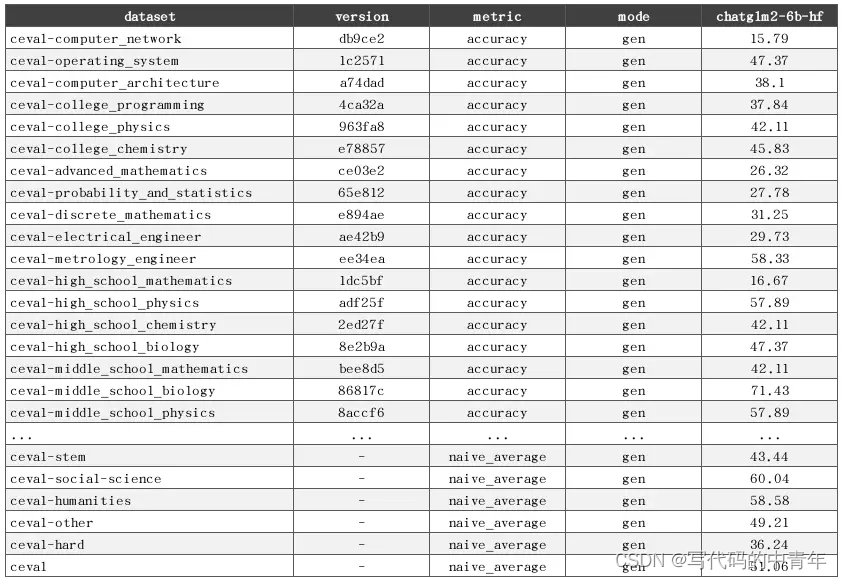
例如开发公司手册的知识专属大模型,如果不对大模型问答范围进行约束,一来该专属领域大模型应用的专属特征丢失了,二来对于无用问题,容易对模型资源造成浪费,如果存在一定信息存储和多轮对话功能,那么浪费将会更严重。
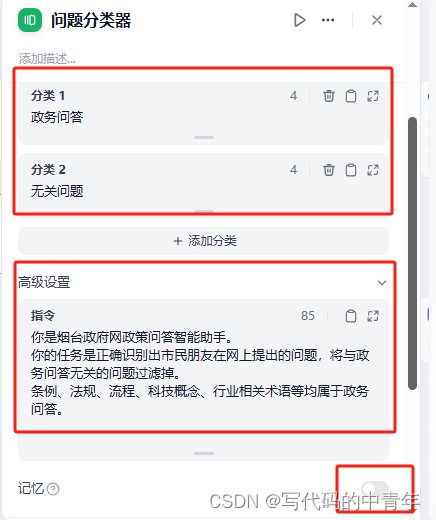
Olama是一个旨在简化大型语言模型本地部署和运行过程的工具。它提供了一个轻量级、易于扩展的框架,让开发者能够在本地机器上轻松构建和管理LLMS。通过Olama,开发者可以访问和运行一系列预构建的模型,并与其他开源项目、应用程序进行耦合实现大模型应用开发。Ollama支持多场家、多尺寸、多模态的各类大模型。
大模型数据侧的一点总结内容,包括数据类型的两个维度划分以及大模型数据集生成方法和注意事项。

完结,撒花!
一个完整的包含 CoT 的 Prompt 往往由指令(Instruction),逻辑依据(Rationale),示例(Exemplars)三部分组成。一般而言指令用于描述问题并且告知大模型的输出格式,逻辑依据即指 CoT 的中间推理过程,可以包含问题的解决方案、中间推理步骤以及与问题相关的任何外部知识,而示例则指以少样本的方式为大模型提供输入输出对的基本格式,每一个示例都包含:问题,推理过程与答案
大模型开发框架,最基本、通用框架之一。langchain六大组成:1.模型,对模型的加载和使用。2.提示词,不同的任务使用不同prompt,管理和优化这些prompt。3.链,初步理解为具体任务中不同子任务之间的调用。4.数据增强的生成,数据增强生成涉及特定类型的链,首先与外部数据源交互以获取数据用于生成步骤。对长篇文字的总结和对特定数据源的提问/回答——即RAG,可以理解数据增强为一种特殊的链。
简单来说,大模型RAG,即Retrieval-Augmented Generation,是一种结合了检索和生成能力的预训练语言模型。它由两部分组成:一个检索系统和一个生成模型。由上,可以简单总结RAG实现过程。应用侧:需求——知识库检索——结果召回——LLM 提示词、Agent等有关开发——LLM结合需求+知识库检索结果进行回答——结束实现侧:文档上传——文本分段和清洗——嵌入模型选型、文本嵌入—

支持模型映射,重定向用户的请求模型,如无必要请不要设置,设置之后会导致请求体被重新构造而非直接透传,会导致部分还未正式支持的字段无法传递成功。支持主题切换,设置环境变量 THEME 即可,默认为 default,欢迎 PR 更多主题,具体参考此处。账号注册,点击令牌、充值、日志、设置等功能按钮或登录按钮均可见登陆界面,按页面指导即可注册账户。支持令牌管理,设置令牌的过期时间、额度、允许的 IP 范
