




- @qq_42503369
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在现在的2025年,晟腾卡的torch使用体验已经好了很多了,当然也不是没有问题,比如使用transformers的库就有自己的各种各样的问题(精度不对齐),想要调优还很困难。我觉得这个方向是对的,因为尊重开源社区的成果以及有自信是很重要的,完全不需要重复造轮子的时候,没有需求的时候,尽量保持标准。毕竟话语权是自己靠贡献争取的。但是这不代表框架没有坑,最坑的就是megatron-adaptor这个

简单回顾MAML。给定一组从底层分布中提取的任务,在MAML中,与传统的监督学习设置相反,目标不是找到一个在预期的所有任务上都表现良好的模型。相反,在MAML中,假设在新任务到达后,有限的计算预算来更新模型,在这个新设置中,寻找一个初始化,它在相对于这个新任务更新后表现良好,可能是通过一个或几个梯度下降步骤。这个公式的优势在于,保持FL的优势还捕获了用户之间的差异,无论是现有用户还是新用户都可以将
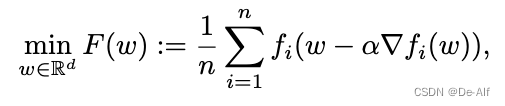
联邦学习数据集下载链接,leaf,cifar
FL中,N客户端训练一个共享模型theta,各有各的数据集D,损失函数l,即最小化所有客户端上的经验损失函数。问题是前提要求iid数据分布,若为non iid则不好。iid: independent identical distribution,独立同分布。理解成所有客户端上的样本服从统一的分布。non iid导致global model无法在所有客户端上进行最小化经验损失。因此采用分组元学习的方
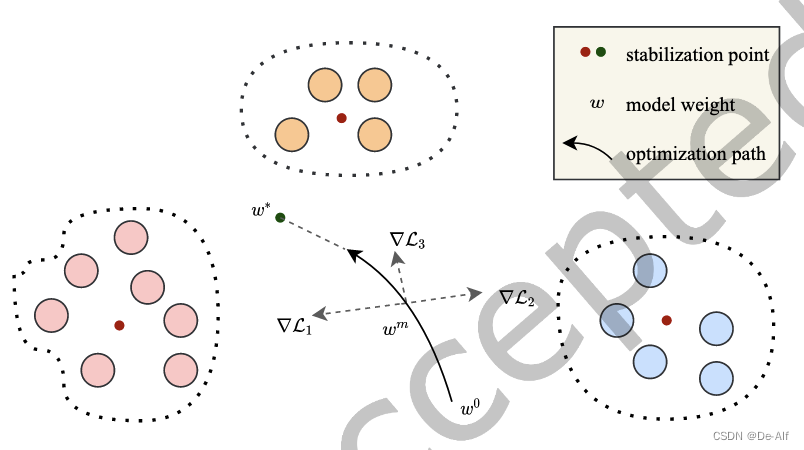
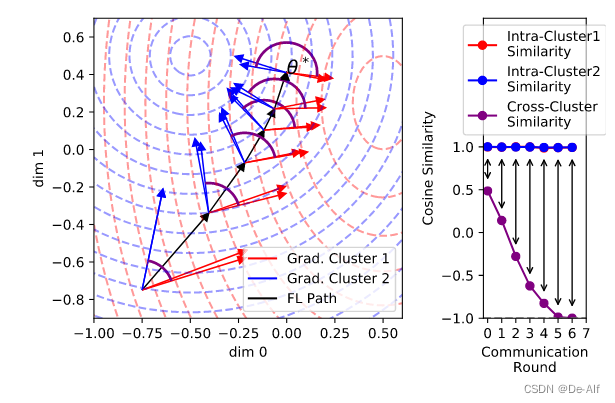
Clustered Federated Learning: Model-Agnostic Distrib不需要事先指定聚类数量?作为一种 后处理 ,让客户端准确度更高文章很好,行文清晰严谨,让人眼前一亮。数学证明严谨,简洁,巧妙。当然这个工作也是有缺陷的。每一类都要维护一个模型(或者说一个分类的树)
Megatron框架中的模型并行实现方法,重点分析了张量并行(TP)、流水线并行(PP)、数据并行(DP)和上下文并行(CP)等多维并行策略。文章阐述了MPU工具如何管理并行训练环境,包括并行组初始化、通信封装和资源协调。通过分析rank分配逻辑和不同并行维度的组织方式,解释了如何实现高效的大模型训练。特别讨论了各并行策略的特点及其组合应用,如TP优先分配以保证通信效率、PP的流水线特性等。最后指

混合精度训练,优化器会在初始化时为所有FP16、BF16参数创造一份FP32的 main param参数,把optimizer里指向的内容替换成main_param,同时让原本的param指向main_param。最后set_up_model_and_optimizer也会额外导入bert模型的权重,转换可能的检查点格式(传统的torch pt和dist checkpoint的互相转换),返回初始
在现在的2025年,晟腾卡的torch使用体验已经好了很多了,当然也不是没有问题,比如使用transformers的库就有自己的各种各样的问题(精度不对齐),想要调优还很困难。我觉得这个方向是对的,因为尊重开源社区的成果以及有自信是很重要的,完全不需要重复造轮子的时候,没有需求的时候,尽量保持标准。毕竟话语权是自己靠贡献争取的。但是这不代表框架没有坑,最坑的就是megatron-adaptor这个
在现在的2025年,晟腾卡的torch使用体验已经好了很多了,当然也不是没有问题,比如使用transformers的库就有自己的各种各样的问题(精度不对齐),想要调优还很困难。我觉得这个方向是对的,因为尊重开源社区的成果以及有自信是很重要的,完全不需要重复造轮子的时候,没有需求的时候,尽量保持标准。毕竟话语权是自己靠贡献争取的。但是这不代表框架没有坑,最坑的就是megatron-adaptor这个
Megatron中检查点会有普通的检查点和release检查点的区别。里面首先保存全部的args,然后是iteration,模型的state dict,optimizer里的state dict,scheduler的state dict等等。Megatron中,检查点的保存发生在train的主循环中每一个train step之后,根据args.save保存的路径以及args.save_interv
