- @qq_41909775
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
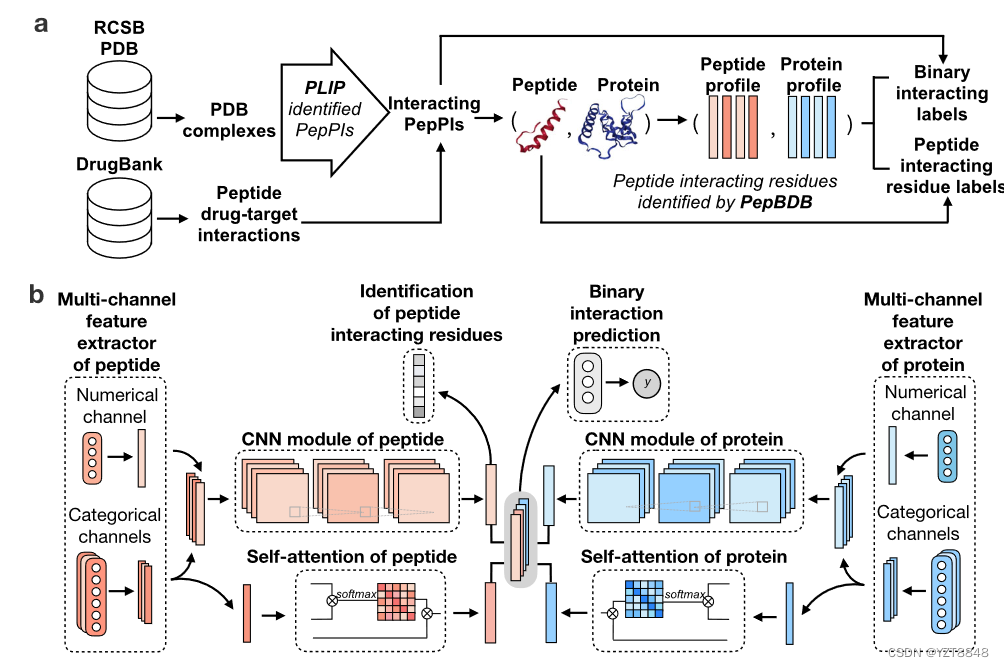
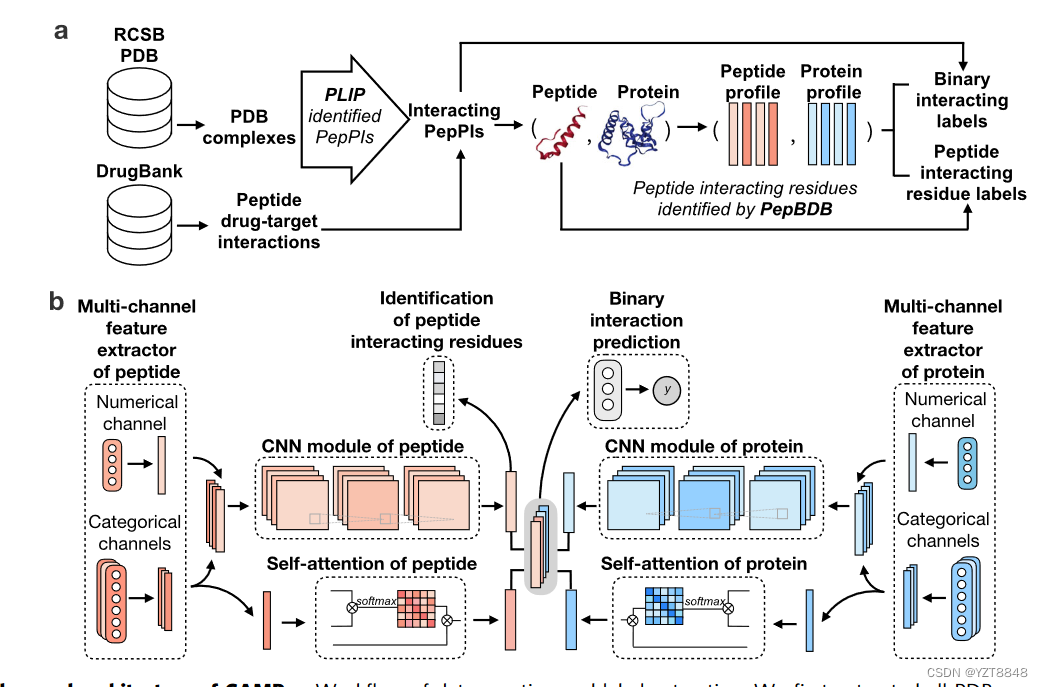
期刊名:Bioinformatics分区:Q1发表:2022年1月8号代码数据集:GitHub - CSUBioGroup/BACPI
我们从两个来源构建了一个基准数据集,即来自RCSBPDB21,22的蛋白质-肽复合物结构,以及来自Drugbank23-27的已知药物对接对(可以在补充注释10和相应的PDBID中找到更多数据策划的详细信息我们用于培训和测试的方法可以在补充数据的补充表12和13中找到。通常,AUPR可以提供一个更好的度量标准,以比AUC32更有信息的方式评估偏斜数据的预测模型。在这里,我们提出了一个深度学习框架,
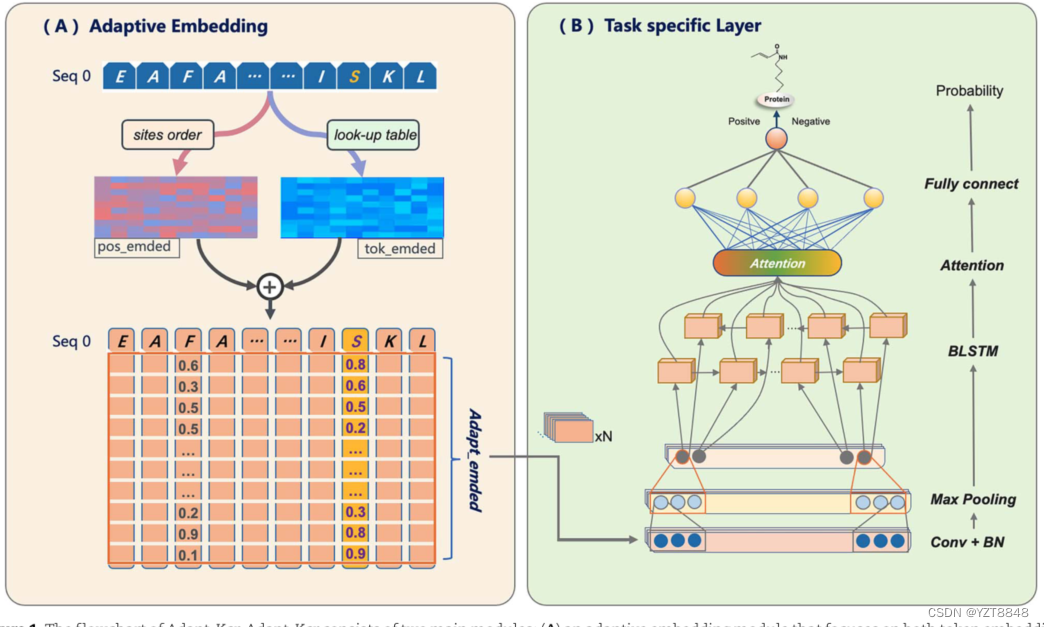
Tirle:Adapt-Kcr: a novel deep learning framework for accurate prediction of lysine crotonylation sites based on learning embedding features and attention architecture期刊:Briefings in Bioinformatics分区\影
DNAN4-甲基胞嘧啶(4MC)是重要的表观遗传修饰,在调节DNA复制和表达中起着至关重要的作用。但是,通过实验方法检测4MC站点是一项挑战,这些方法耗时且昂贵。因此,可以识别4MC位点的计算工具对于理解这种重要类型的DNA修饰的机制非常有用。在过去的3年中,已经提出了一些基于机器学习的4MC预测指标,尽管它们的性能不令人满意。深度学习是开发更准确的4MC站点预测的一种有希望的技术。在这项工作中,
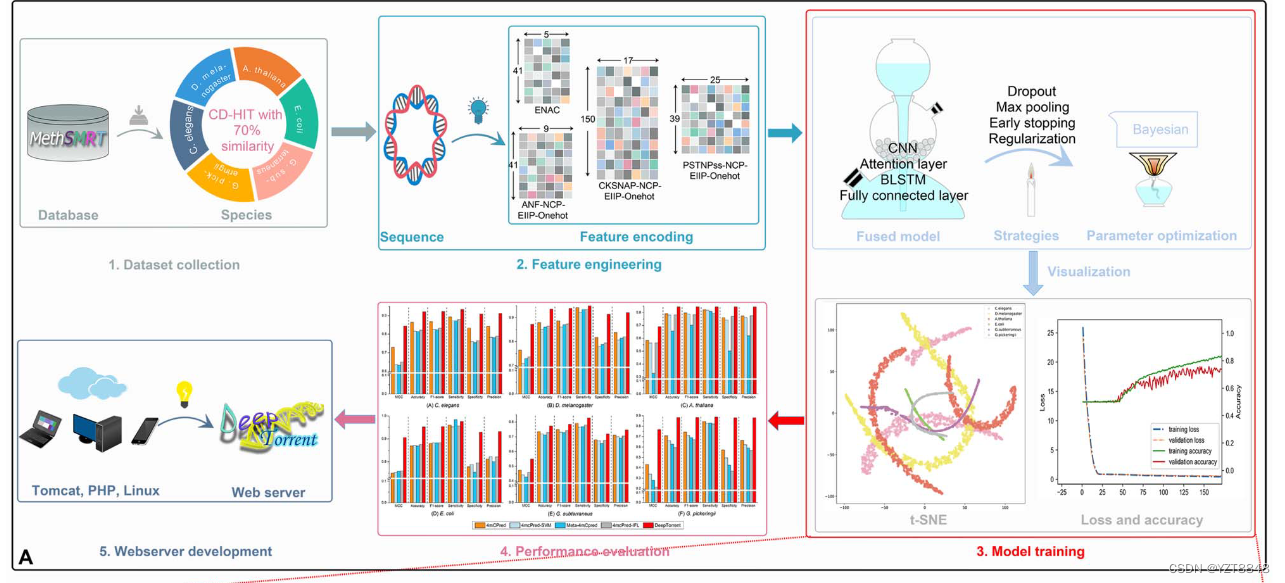
期刊名:Bioinformatics分区:Q1发表:2022年1月8号代码数据集:GitHub - CSUBioGroup/BACPI
我们从两个来源构建了一个基准数据集,即来自RCSBPDB21,22的蛋白质-肽复合物结构,以及来自Drugbank23-27的已知药物对接对(可以在补充注释10和相应的PDBID中找到更多数据策划的详细信息我们用于培训和测试的方法可以在补充数据的补充表12和13中找到。通常,AUPR可以提供一个更好的度量标准,以比AUC32更有信息的方式评估偏斜数据的预测模型。在这里,我们提出了一个深度学习框架,
Title:ctP2ISP: Protein–Protein Interaction Sites Prediction Using Convolution and Transformer with Data Augmentation期刊:IEEE-ACM Transactions on Computational Biology and Bioinformatics代码和数据集:GitHub -
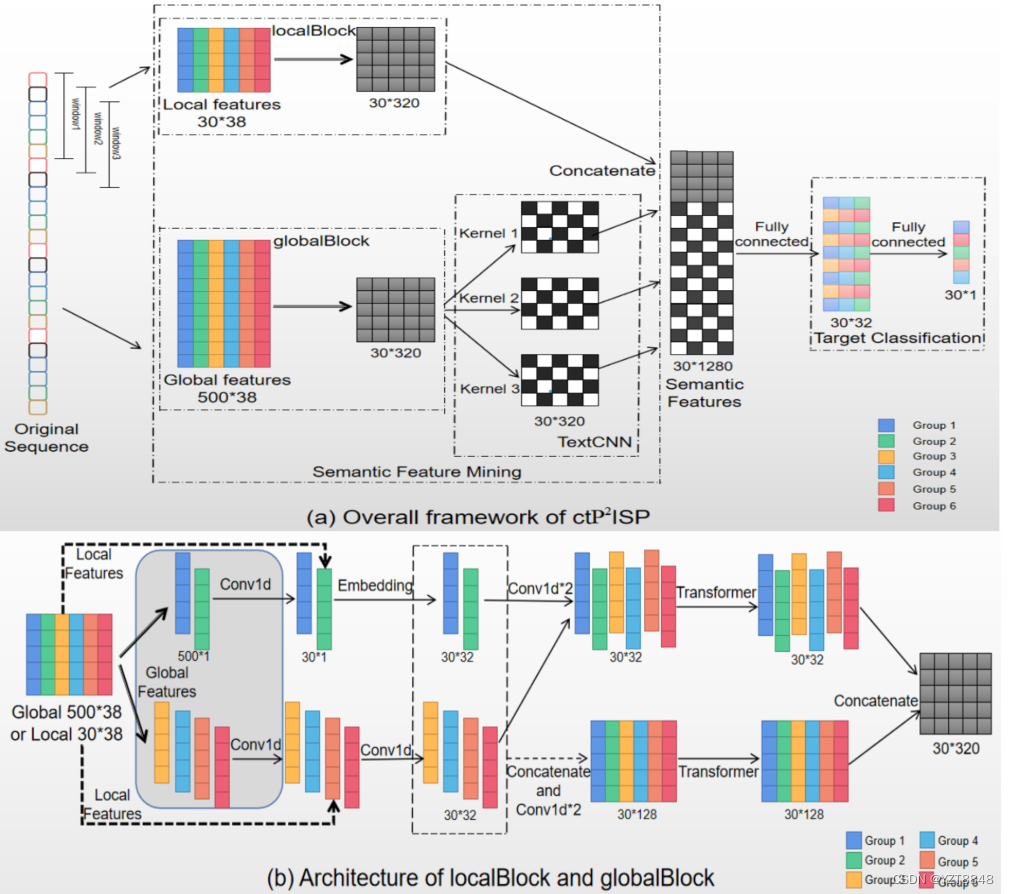
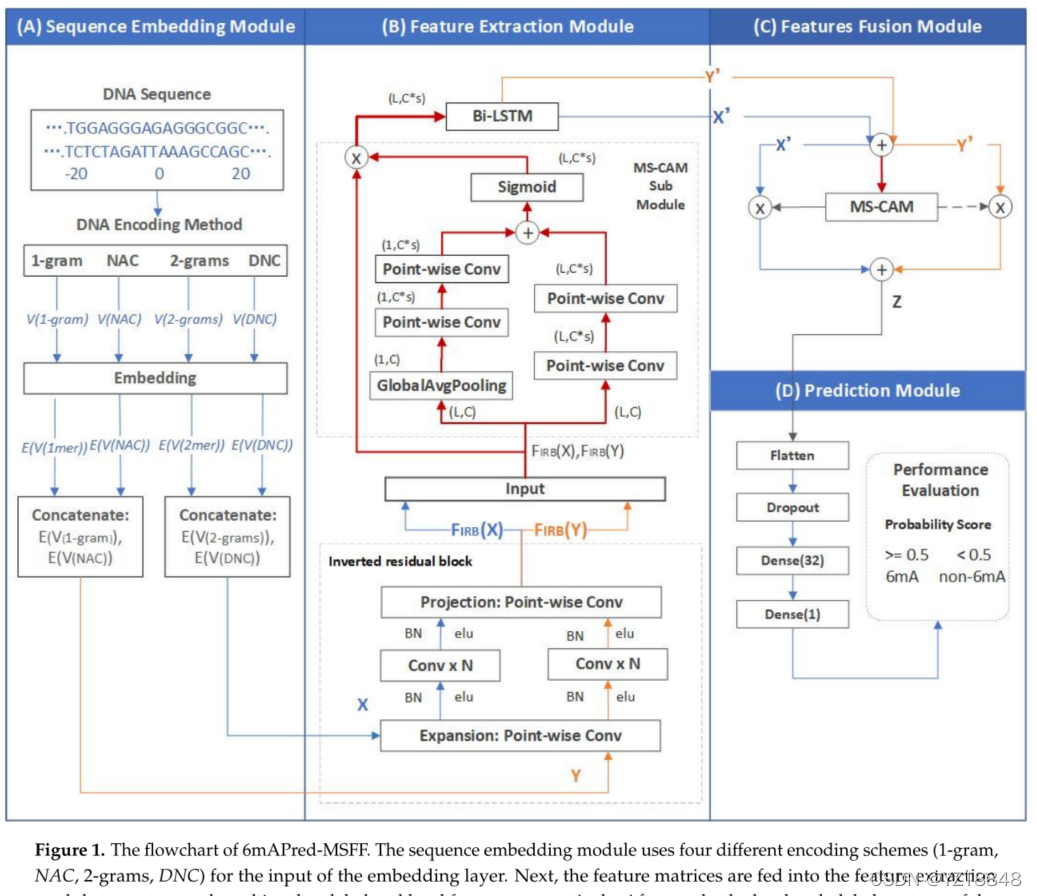
Title:6mAPred-MSFF: A Deep Learning Model for Predicting DNA N6-Methyladenine Sites across Species Based on a Multi-Scale Feature Fusion Mechanism期刊:applied sciences代码与数据集:一、摘要开发了一种新的计算预测器,即6mAPred-MS
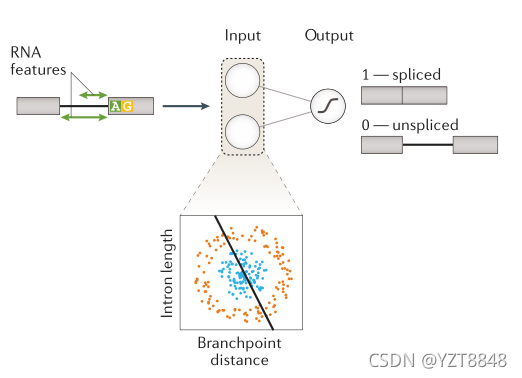
期刊名:Nature Reviews GeneticsDOI:10.1038/s41576-019-0122-6代码链接:一、作为一门数据驱动的科学,基因组学在很大程度上利用机器学习来捕捉数据的依赖性,并推导出新的生物学假设。二、然而,从指数级增长的基因组学数据中提取新见解的能力需要更具有表现力的机器学习模型。通过有效地利用大型数据集,深度学习已经改变了计算机视觉和自然语言处理等领域。现在,它正成
期刊naturecommunications。影像因子17.694。