




- @qq_41823532
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
华为昇腾950 NPU是一款高性能神经网络处理器,其架构白皮书详细介绍了其创新设计。该芯片采用达芬奇架构,支持混合精度计算和高效数据流调度,具备强大的AI算力。昇腾社区资料显示,其核心架构包含Cube计算单元、向量引擎和任务调度器,支持多种神经网络模型的高效执行。芯片通过优化的存储层次结构和并行计算设计,显著提升AI训练和推理性能,适用于云端和边缘计算场景。相关技术文档提供了架构细节和开发指南,帮
华为昇腾950 NPU是一款高性能神经网络处理器,其架构白皮书详细介绍了其创新设计。该芯片采用达芬奇架构,支持混合精度计算和高效数据流调度,具备强大的AI算力。昇腾社区资料显示,其核心架构包含Cube计算单元、向量引擎和任务调度器,支持多种神经网络模型的高效执行。芯片通过优化的存储层次结构和并行计算设计,显著提升AI训练和推理性能,适用于云端和边缘计算场景。相关技术文档提供了架构细节和开发指南,帮
华为昇腾950 NPU是一款高性能神经网络处理器,其架构白皮书详细介绍了其创新设计。该芯片采用达芬奇架构,支持混合精度计算和高效数据流调度,具备强大的AI算力。昇腾社区资料显示,其核心架构包含Cube计算单元、向量引擎和任务调度器,支持多种神经网络模型的高效执行。芯片通过优化的存储层次结构和并行计算设计,显著提升AI训练和推理性能,适用于云端和边缘计算场景。相关技术文档提供了架构细节和开发指南,帮
参考链接 :https://www.hiascend.com/document/detail/zh/CANNCommunityEdition/850alpha001/opdevg/Ascendcopdevg/atlas_ascendc_10_0092.html。API在计算过程需要一些workspace内存作为缓存,因此算子需要为API预留workspace内存,预留内存大小通过GetLibApi
摘要: BF16和FP16作为主流16位浮点格式,在AI领域各有优势。BF16(1-8-7位结构)具有与FP32相同的指数范围,适合大模型训练,能有效避免梯度问题;FP16(1-5-10位结构)精度更高,适合推理和视觉任务。LLM训练中,BF16混合精度可减少50%内存占用并提升30-40%速度;FP16在推理时能保持更好输出质量。多模态领域,视觉分支适合FP16,文本分支适合BF16。实际应用需
选购建议(按预算 & 需求) 目标推荐显卡价格区间(人民币)理由说明预算有限,只想体验 AI 玩玩RTX 2080 Ti(魔改 22GB)¥2,000 – ¥3,000性价比极高;显存魔改后(22GB)可运行多数 LLM 推理(如 7B 模型量化版),适合入门学习。但架构较老(Turing),无 FP8/BF16/TF32 原生支持。中等预算,追求稳定 & 性能平衡RTX 30
记录下关于显卡的知识。
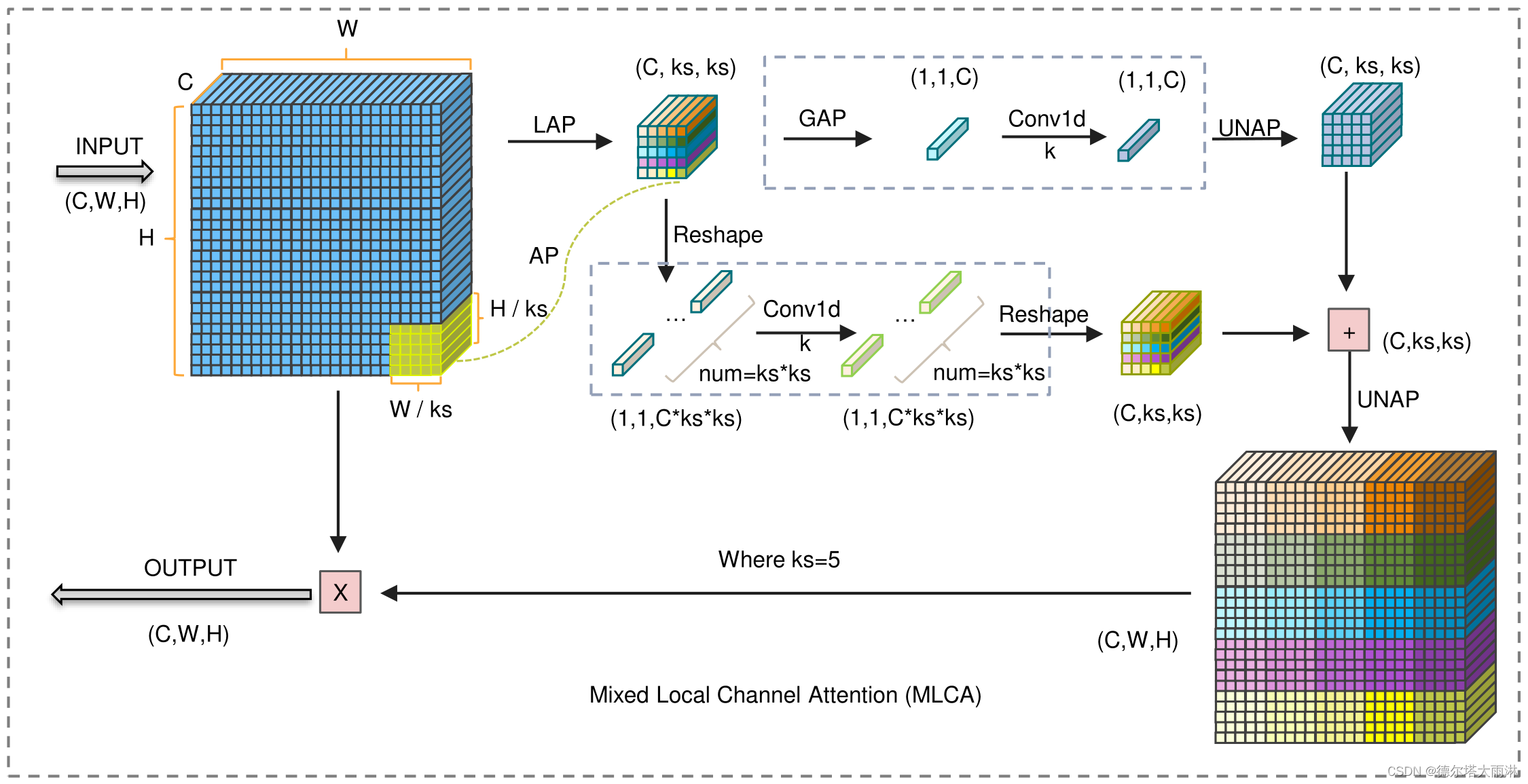
本文章介绍了一种轻量级的 Mixed Local Channel Attention (MLCA) 模块,该模块同时考虑通道信息和空间信息,并结合局部信息和全局信息以提高网络的表达效果。基于该模块,我们提出了 MobileNet-Attention-YOLO(MAY) 算法,用于比较各种注意力模块的性能。在 Pascal VOC 和 SMID 数据集上,MLCA 相对于其他注意力技术更好地平衡了模
一个月就录用了,审稿速度也蛮快的。