




- @qq_41739364
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
模型路径:/root/autodl-tmp/LLM-Research/Meta-Llama-3-8B-Instruct。adapter开头的就是 LoRA 保存的结果了,后续用于模型推理融合。强烈建议选 4090(24G),不然微调的显存不够。我们用 LoRA 微调,至少得 16G(7B模型)。俩个地方都要改:file_name、本地数据集路径。这个数据,ta会去hf官方找,我们可以设置镜像站。微
直到老板群里,看到有人分享,给 5 个运营开gpt(700),配合工作流,直接把 5 个人的活,压缩到 2 个人干,另外3个被优化,一个月就省 2 万多的工资,付费就是捡便宜!有一个电商公司的老板,买了 140 元每月的 gpt,但是用了一段时间就停了,觉得没有网络上说的那么神,就是个问答机器人,每月多花 140 不值。当使用率到 70% 以上,那智能体想出新计划的能力就会降低,会倾向重复其历史中
目的:建立专业背书选题方向“做了10年刺身,我为什么要做配送”“前日料店主厨,现在专门送刺身”“这些年,我只做一件事”脚本示例【开头 - 身份亮相】我叫xxx,做刺身 10 年了。【中间 - 经历背书】以前在日料店做主厨,每天处理上百斤深海鱼。什么鱼新鲜、什么鱼能生吃,闭着眼睛都知道。后来发现,很多人想在家吃好刺身,但市面上的品质参差不齐。所以我出来做配送,把日料店的品质,送到你家里。【结尾 -
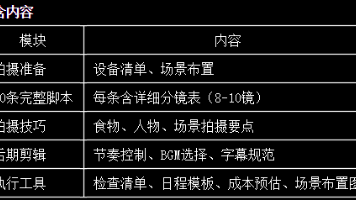
做了10年刺身,我为什么要做配送》时长:40-45秒风格:人设向、真诚讲述20条完整拍摄脚本:覆盖用户激活四阶段详细分镜表:每条脚本8-10个镜头拍摄技巧指南:食物、人物、场景后期剪辑要点:节奏、BGM、字幕实用工具模板:检查清单、日程安排、成本预估按照本文档执行,可在4周内完成新号启动的全部内容拍摄。
短视频是流量入口,私域才是利润池。短视频引流 → 私域承接 → 信任培育 → 持续转化 → 长期复购私域GMV = 客户数量 × 转化率 × 客单价 × 复购频次。
借助医疗知识网络连接各种医疗信息源,把所有医学知识建成一个域(一个中心+N个扩展),使得无损长上下文中稳定管理多维信息,同时解决语义检索捕获不了的长尾关系(不太常见但可能很重要的信息 — 因为长尾知识通常存在于细节和上下文中,而不是简单的实体关系中)。构建一个医疗多智能体问答系统:接收医生的复杂医疗问题,通过多个智能体协作,从知识图谱中检索、验证、整合信息,最终输出准确、可追溯的医疗建议。同时,用
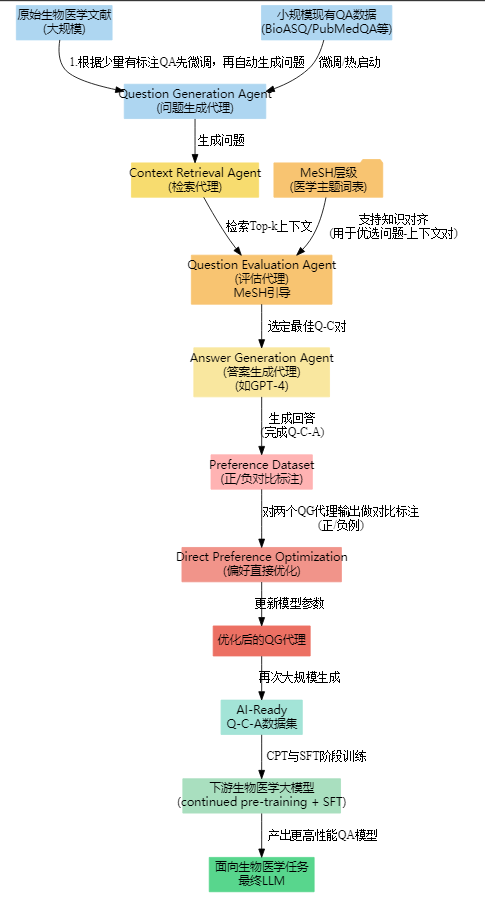
答10论文实验证明,用 m-KAILIN 生成的数据给生物医学大模型做连续预训练 (CPT) 或监督微调 (SFT),模型在各种医学 QA 任务上精度显著提升。甚至在一些场景下,小参数模型也能和更大规模的商用模型接近或超越。总结m-KAILIN 的核心思路把海量医学文献先“提取+转换”成问答格式再用先进 LLM 去“填”答案,最终持续迭代生成一个规模庞大、质量高的生物医学问答训练集。通过多智能体协
两大类深度学习模型,分别用于不同的自然语言处理(NLP)任务:词嵌入模型是一类用于将单词、短语或者文档转换为向量形式的模型。这些向量捕捉了单词之间的语义关系,如相似性或上下文关联。例如,text2vec、M3E等模型能够将文本中的每个单词映射到一个高维空间中的点,这个点的位置与单词的语义密切相关。通过这种方式,模型能够理解和处理自然语言,为诸如文本分类、情感分析等任务提供基础。举个例子:在词嵌入模
EHR-CoAgent是一个创新的医疗预测系统,它通过两个协作的大语言模型智能体,将结构化的电子健康记录转化为自然语言叙述,并进行少样本疾病预测。最重要的发现是:通过模拟医生的诊断-反思过程,可以显著提高医疗预测的准确度,特别是在数据有限的情况下。这为医疗AI的发展提供了新的思路。这种分析方法特别适合理解像EHR-CoAgent这样的复杂系统,因为它既展示了系统的静态结构,也揭示了系统的动态特性。

集中式训练(Centralized Training)介于完全去中心化智能体系统和传统的中心化智能体系统之间,解决俩者的部分问题,旨在提升效率、确保数据一致性、实现模型同步、统一训练策略、简化性能监控和资源优化、促进知识共享、提高可扩展性,并简化开发过程。方案一 只是 推荐系统与大模型 的简单结合,而 RPP 是一个更先进、更动态的系统,它将强化学习、提示工程和大语言模型深度整合,提供了更灵活、更
