- @qq_41009600
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
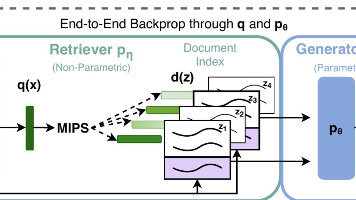
RAG 指的是检索增强生成(Retrieval-Augmented Generation),这是一种结合了信息检索和生成式AI的框架,旨在提升大语言模型(LLM)的输出质量。它通过在LLM生成回答之前,先从外部知识库(如数据库或文档)中检索相关信息,然后将这些信息作为上下文提供给模型,从而确保生成的内容更加准确、及时且相关,同时避免了重新训练模型。本文提出了可以访问参数和非参数记忆的混合生成模型,
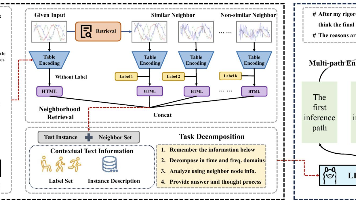
本文通过引入表格学习,解决了现有大语言模型对时间序列分类的诸多挑战。这种“交叉引用”的思想在现有大模型的研究中非常常见,也是比较容易出论文的一种方式。然而要找到那个能解决问题的“交叉引用”点并不是十分容易,前提是你得对某领域所存在的问题研究的十分透彻。如本文中时间序列分类三大缺陷的原理以及为什么表格学习能够解决这三大缺陷?你需要理解的十分透彻。2025年10月21日学习笔记文章同步更新在同名今日头
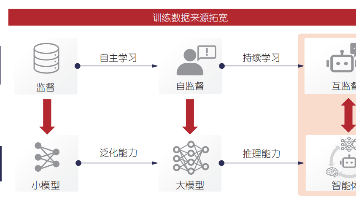
针对模型孤岛与数据流通问题,本研究提出了一种 基 于 模 型 间 协 作 的 机 器 学 习 范 式 , 旨 在 建 立FAgent 的完整链条,实现由多方模型结合私域数据实现生产智能体的全流程。不同于一般的大模型学习,FAgent 中主要通过大小模型间的协作学习,在保护模型和数据隐私的前提下,借助大模型提升小模型能力,或反之通过小模型增强大模型知识,从而产出相应的智能体。这种新的智能体联合学习思
文章巧妙的点在于,作者观察到在表格学习中面临的两大挑战。而后借助于常用的预训练/微调框架一一进行解决,是本文的一大特色。此外,由于关系型表格数据集的缺乏,作者提出了一种有说服力的表格数据集构造方法,也是我们在进行大模型算法的优化中,值得学习的一种思路。2025年10月14日学习笔记文章同步发布在同名今日头条号“一的万次方”
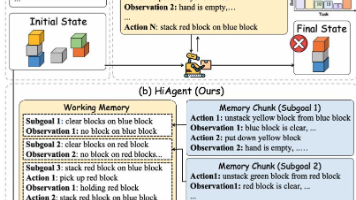
一篇非常有趣的论文,个人理解论文的核心创新点为“拆分子目标“的思想,子目标的拆分使得智能体在执行长程任务时性能得到提升。这一思想其实早在其他论文中提出,作者创新性地将这一思想用到了智能体的工作记忆改进中。有了上面的核心思想,作者还提出了“轨迹检索模块”另一个创新点,以实现查询之前子目标的详细轨迹信息。这两个创新点用到了新领域(智能体短期记忆),使得HIAGENT在五个长程任务实验中,均领先于现有的