- @qq_38646027
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了中文大模型的高效部署方案,重点推荐两套"中文最稳组合":通用配置(Qwen3-7B+BGE-M3)和轻量配置(ChatGLM3-6B+m3e-large)。详细讲解了从环境配置、模型获取到vLLM加速和嵌入模型使用的全流程,并提供了RAG实战案例。文章特别强调使用vLLM推理引擎可显著提升性能(5-10倍速度提升,显存降低30%+),同时给出常见问题解决方案。这套方案

AI编程工具对比指南:主流产品核心定位与适用场景解析 本文全面对比了当前主流AI编程工具,从产品形态、核心能力、价格和适用场景等维度进行拆解。

2026年开源大模型呈现"中国领跑、MoE主导、场景专精"三大趋势。全球TOP10榜单中,中国模型占据8席,阿里Qwen3.5以397B参数MoE架构和多模态能力位居榜首。技术架构上,9/10模型采用MoE变体,实现大参数与高效率平衡;应用场景则从通用转向专精,如GLM-5擅长复杂工程、DeepSeek-V4专攻推理、KimiK2.5专注长文本处理。训练数据质量提升,微调技术门
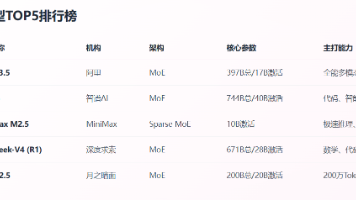
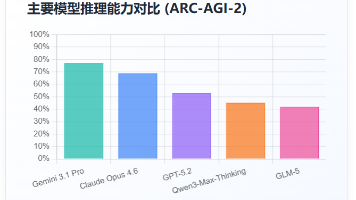
2026年全球闭源大模型呈现"三足鼎立+国产突围"格局。OpenAI的GPT-5.2系列、Anthropic的Claude Opus 4.6和Google的Gemini 3.1 Pro构成第一梯队,在推理能力、编程性能和多模态处理方面各具优势。中国厂商通过开源策略实现技术突破,Qwen3-Max-Thinking等国产模型在中文场景和性价比方面表现突出。评估显示,Gemini 3.1 Pro在复杂
AI编程工具对比指南:主流产品核心定位与适用场景解析 本文全面对比了当前主流AI编程工具,从产品形态、核心能力、价格和适用场景等维度进行拆解。
数据输入层:Input Layer1、数据预处理进行预处理的主要原因是:输入数据单位不一样,可能会导致神经网络收敛速度慢,训练时间长数据范围大的输入在模式分类中的作用可能偏大,而数据范围小的作用就有可能偏小由于神经网络中存在的激活函数是有值域限制的,因此需要将网络训练的目标数据映射到激活函数的值域S形激活函数在(0,1)区间以外区域很平缓,区分度太小。例如S形函数f(...
本文是一篇全面的Flask企业级大模型API开发教程,涵盖从环境搭建到生产部署的全流程。主要内容包括:Flask基础开发、蓝图模块化、Pydantic参数校验、APIKey/JWT鉴权等企业规范;重点讲解大模型核心技能如异步路由、SSE流式响应(打字机效果)和文件上传;最后介绍生产环境部署方案(Gunicorn+Nginx+Docker)。教程提供完整代码示例,适用于大模型对话接口、AI服务API

2026年全球闭源大模型呈现"三足鼎立+国产突围"格局。OpenAI的GPT-5.2系列、Anthropic的Claude Opus 4.6和Google的Gemini 3.1 Pro构成第一梯队,在推理能力、编程性能和多模态处理方面各具优势。中国厂商通过开源策略实现技术突破,Qwen3-Max-Thinking等国产模型在中文场景和性价比方面表现突出。评估显示,Gemini 3.1 Pro在复杂
AI编程工具对比指南:主流产品核心定位与适用场景解析 本文全面对比了当前主流AI编程工具,从产品形态、核心能力、价格和适用场景等维度进行拆解。
本文介绍了零基础入门大模型应用开发的核心方法,重点讲解如何通过API调用快速搭建落地应用。主要内容包括:1)API调用基础,掌握HTTP请求、密钥管理和参数配置;2)RESTful API设计规范与使用技巧;3)模型响应处理与异常应对策略;4)错误日志管理与开发环境搭建。文章强调无需深入模型训练,只需掌握API调用、响应处理、容错机制和环境配置等关键模块,即可开发智能问答、文本生成等简单应用。最后