




- @qq_36002089
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
生成式人工智能就是让机器产生复杂的、有结构的物件,如:文本、语音、图像等。而这些物件的在计算机中的表现就是数字,如文本就是一堆文字,文字编码成数字;语音就是一堆采样点;图像就是一堆像素点,这些都是数字。

语音合成语音合成技术大体可分为以下三个部分:文语合成(TTS,Text to Speech)语音转换(VC, Voice Conversion)语音生成(VG,Voice Generation)技术分类常见分为两类:波形拼接法、参数法(声码器)。1. 波形拼接法首先,要准备好大量的语音,这些音都是又基本的单位拼接成的(基本单位如音节、音素等),然后从已准备好的声音中,抽取出来合成目标声音。优点:使
基于神经网络模型的波士顿房价预测波士顿房价预测是一个经典的机器学习任务,类似于程序员世界的“Hello World”。以“波士顿房价预测”任务为例,我们学习如何使用Python语言和Numpy库来构建神经网络模型。波士顿地区的房价受诸多因素影响。该数据集统计了13种可能影响房价的因素和该类型房屋的均价,期望构建一个基于13个因素进行房价预测的模型,如下所示。对于预测问题,可以根据预测输出的类型是连
语音识别: 将语音识别成文本。微信上的语音转为文字功能。还有一些语音助手,Siri,Cortana,小度,小爱同学等等。语音是声音的一种。声音是由振动产生的,通过空气传播到达耳朵,空气的某些地方稠密,有些稀疏,不断变化,声波到达耳朵。振动的快慢,就是频率。人耳能听到的频率范围:20Hz-20000Hz。语音是种特殊的声音,为什么呢?因为它是人发出的声音,里面包含了丰富的信息。其他声音不含任何信息的
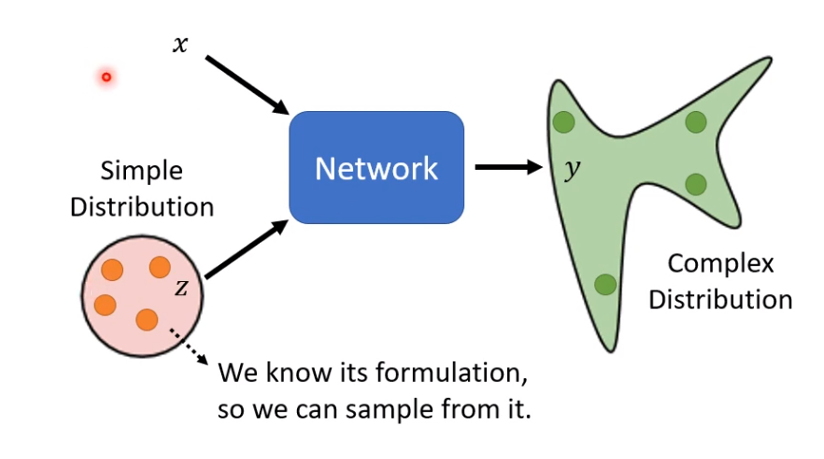
生成式网络有什么特别的地方呢?之前我们学到的神经网络就是一个函数,输入一个向量x(序列,图片,文本…),输出一个y(数值,类别,序列…)现在特别的地方就是,不仅输入x,还得输入一个随机变量z,z是从某一个分布中取样出来的,所以每次取样出来的z都是随机的。但要求这个z的分布够简单,就是你知道它的概率分布的公式是什么,比如高斯分布。为什么输入要额外有个z呢?......
音频数字化就是将模拟的(连续的)声音波形数字化(离散化),以便利用数字计算机进行处理的过程,主要包参数括采样频率(Sample Rate)和采样数位/采样精度(Quantizing,也称量化级)两个方面,这二者决定了数字化音频的质量。采样频率是对声音波形每秒钟进采样的次数。根据这种采样方法,采样频率是能够再现声音频率的一倍。人耳听觉的频率上限在20kHz左右,为了保证声音不失真,采样频率应在40k

生成式人工智能就是让机器产生复杂的、有结构的物件,如:文本、语音、图像等。而这些物件的在计算机中的表现就是数字,如文本就是一堆文字,文字编码成数字;语音就是一堆采样点;图像就是一堆像素点,这些都是数字。
三个大概念深度学习是机器学习领域中神经网络分支的发展。机器学习观察现象,发现规律,假设模型,设计评价指标(损失loss),通过评价指标找到模型最优解的过程叫做优化。深度学习传统机器学习:人工特征提取(靠人的经验)简单模型:机器学习模型,没有对数据进一步提取深度特征的能力深度学习最基本概念–神经网络...


基于神经网络模型的波士顿房价预测波士顿房价预测是一个经典的机器学习任务,类似于程序员世界的“Hello World”。以“波士顿房价预测”任务为例,我们学习如何使用Python语言和Numpy库来构建神经网络模型。波士顿地区的房价受诸多因素影响。该数据集统计了13种可能影响房价的因素和该类型房屋的均价,期望构建一个基于13个因素进行房价预测的模型,如下所示。对于预测问题,可以根据预测输出的类型是连