




- @qq_33267306
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
python根据url下载图片的方法
selenium的find_element_by_*目前大部分是使用find_element(**)如:find_element_by_xpath('**')可以改写为find_element(By.XPATH,'**'),这样就不会报错,其他也同理,如find_element_by_class_name('**')可find_element(By.CLASS_NAME,'**')find_ele

Python爬取的数据存为json文件,并读取import requestsimport timefrom lxml import etreeimport jsondef json_data_save(url):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like

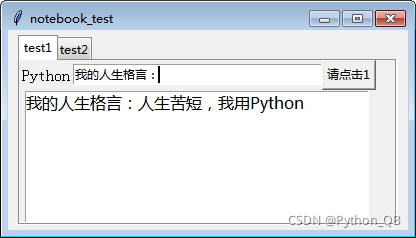
使用ttk.Notebook可实现实现多页面切换直接上代码:import tkinter as tkfrom tkinter import ttkfrom tkinter import ENDclass App:def __init__(self,master):self.notebook = ttk.Notebook(master)self.frame1 = tk.Frame(master)se
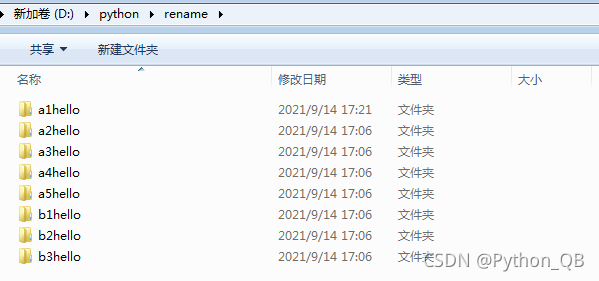
一、修改文件夹的名字找出文件夹之前的名字,用新名字代替,使用os.rename(),如下:import osimport pandas as pdpath = 'D:/python/rename'files= [ i for i in os.listdir(path)] #os.listdir返回指定目录下的所有文件和目录名for file,i in zip(files,range(len(fil
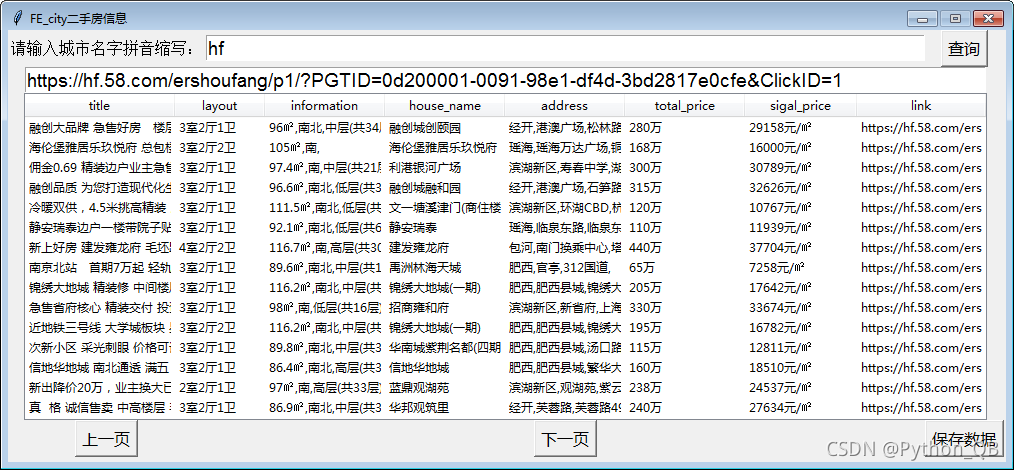
1、查询二手房信息dataframe数据显示在tkinter的TreeView中,实现上下翻页功能,并进行保存。2、下面的代码可直接使用PyInstaller打包成桌面exe程序。import tkinter as tkfrom tkinter import ttkimport pandas as pdfrom tkinter import messageboximport timeimport
1、有个csv文件,我直接用pandas库读取,报错Error tokenizing data. C error: Expected 1 fields in line 3, saw 2,这个应该格式有问题,要打开后,重新保存后才能打开,但由于文件很多,想着能不能用其他方法读取这个csv文件;2、就是通过csv库进行读取,再遍历,后进行合并:import pandas as pdimport csv
