




- @qq_26948675
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
1、读入数据 CCSS_Sample.sav2、对数据中的s3年龄进行分析:分析、描述统计、频率如图所示 双击s3 年龄,s3会出现在变量中,然后点击统计量 勾选相应的要统计的量,点击确定或者继续点击确定,就会出现统计结果,如图所示也可以在分析、描述基本的统计、统计中查看统计量,结果如下图
# coding: UTF-8from struct import *import osimport sysdef day2csv_data(dirname,fname,targetDir):ofile=open(dirname+os.sep+fname,'rb')buf=ofile.read()ofile.close()
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport statsmodels.tsa.stattools as tsdata=pd.read_csv('C:/Users/HXWD/Desktop/数据/rb.csv',encoding='gbk')data.columns=['date','o
要使用到剪贴板的方法,搜索到有两个包可以用,pyperclip,和pywin32clipboard,pyperclip在3.5版本中不能够import,可以手动下载安装,未查到原因;pywin32clipboad不能用pip install 安装,也不能够查找到这个包,原来,这个是pywin32的一部分,直接安装pywin32就可以了。import win32clipboardwin32cl
data<-read.table('C:/Users/HXWD/Desktop/数据/rb.csv',header=TRUE,sep=',')data=data[,5]head(data)data=log(data)head(data)adf.test(data,k = 1)#读取数据,取对数,并进行单位根检验Augmented Dickey-Fuller Testd
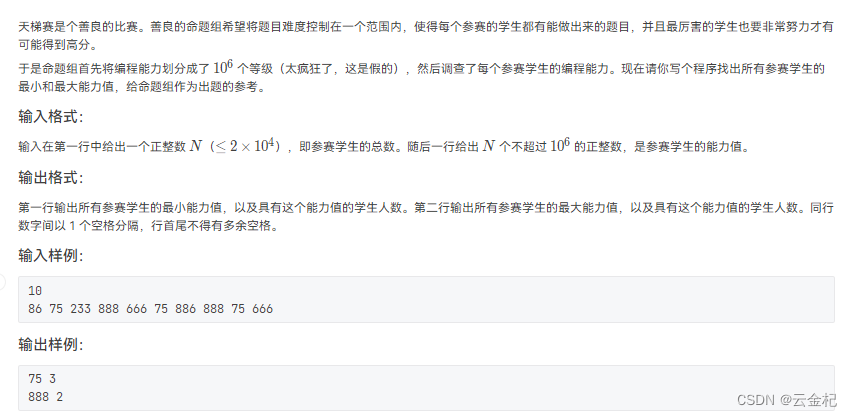
【代码】c语言编程练习题:7-196 天梯赛的善良。
import pandas as pdimport numpy as npimport datetimeimport time#获取数据df=pd.read_csv('C:/Users/HXWD/Desktop/000001.csv',encoding='gbk')df.columns=['date','code','name','close','high','low','open',
小案例:参考了一些文章。做了一个20日移动平均线;这算是第一篇自己用python实现的功能吧。步骤:1、在网易财经下载000300的历史数据。2、配置好python和pandas包代码:#加载pandas包和os包import pandas as pdimport os#获取工作目录os.getcwd()#把数据放入工作目录当
# -*- coding: utf-8 -*-"""Created on Fri Feb 17 15:08:37 2017@author: yunjinqiE-mail:yunjinqi@qq.comDifferentiate yourself in the world from anyone else."""file="C:/Program Files (x86)
有偿提供策略编写、策略评估兼职服务:qq:1733505732时间:18:00-22:00组合测算报告-------------------------------名称全部交易资金分配量200000.00组合合约/周期螺纹指数/1小时,沪铝指数/1小时热卷指数/1小时,铁矿指数/1小时