




- @qq_16763983
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
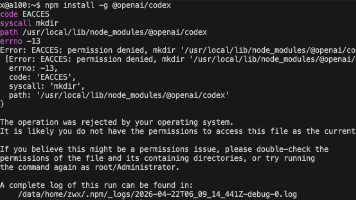
摘要:在服务器上全局安装OpenAI Codex时因权限问题报错,可通过修改npm全局安装路径解决。具体步骤为:创建用户目录下的.npm-global文件夹,设置npm前缀路径,更新环境变量后重新安装。这样无需root权限即可完成Codex的安装和使用。该方法适用于无管理员权限的服务器环境。
本文介绍了使用VSCode/Cursor进行Git版本控制的基本流程:1)安装Source Control插件;2)添加/更换远程仓库;3)将修改文件提交至暂存区;4)编写提交信息并提交;5)推送更新到远程仓库;6)检查Github更新。特别提醒当前默认分支为main而非master,可通过编辑器底部查看分支信息,多分支管理可能涉及merge/rebase等操作。文中配有详细操作截图辅助说明每个步
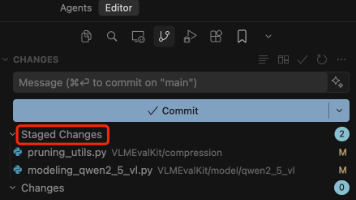
本文介绍了使用VSCode/Cursor进行Git版本控制的基本流程:1)安装Source Control插件;2)添加/更换远程仓库;3)将修改文件提交至暂存区;4)编写提交信息并提交;5)推送更新到远程仓库;6)检查Github更新。特别提醒当前默认分支为main而非master,可通过编辑器底部查看分支信息,多分支管理可能涉及merge/rebase等操作。文中配有详细操作截图辅助说明每个步
简单来说就是,ssh配置没动,前两天还可以用vscode连接服务器,今天突然就连不上了,但是用本地终端ssh可以顺利连接。
CDF是什么?简单对概率分布函数进行一个描述,在概率论中要研究一个随机变量ξ取值小于某一数值x的概率,这概率是x的函数,称这种函数为随机变量ξ的分布函数。F(x)=P(X<x),F(+∞)=1,F(−∞)=0F(x)=P(X<x),F(+\infin)=1,F(-\infin)=0F(x)=P(X<x),F(+∞)=1,F(−∞)=0CDF对机器学习有什么用?可以非常直观地对预测
之前一直在想一个问题:我可以用Softmax回归做多分类问题(判断图中是猫还是狗还是大象),但如果是多标签呢?(同时要判断图中衣服的款式、颜色和大小)这个问题一直留在我心中,我也去找了多标签分类/回归的推导,但是仍然不知道如何通过代码实现这个多标签预测问题。这次在做多标签预测时,发现了sklearn库竟然是可以直接支持多标签预测及指标衡量的!不管我们有多少个不同独立的labels,都可以通过skl
一、计算机视觉Computer VersionCV的三种问题场景图像分类目标检测风格迁移为什么不用DNN而用CNN?如果处理的图像非常大,用DNN网络时矩阵维度非常大!并且参数众多,巨大的内存需求让人不太能接受,所以这个时候继续使用深层神经网络不可取。二、边缘检测垂直边缘检测水平边缘检测接下来用边缘检测这样一个例子,来讲解卷积运算原理。灰度图像:灰度表示明暗程度(1白 0灰 -1黑)过滤器/卷积核
写自定义包的源文件注意路径!注意路径!注意路径!重要的事情说三遍!这个文件夹及其源代码一定要放在GOPATH/GOROOT路径下,在调包时才能import到该文件!在正确的路径下新建pack1文件夹,在文件夹中新建pack1.go,代码如下:package pack1type StructX struct {A intB float64C string}...
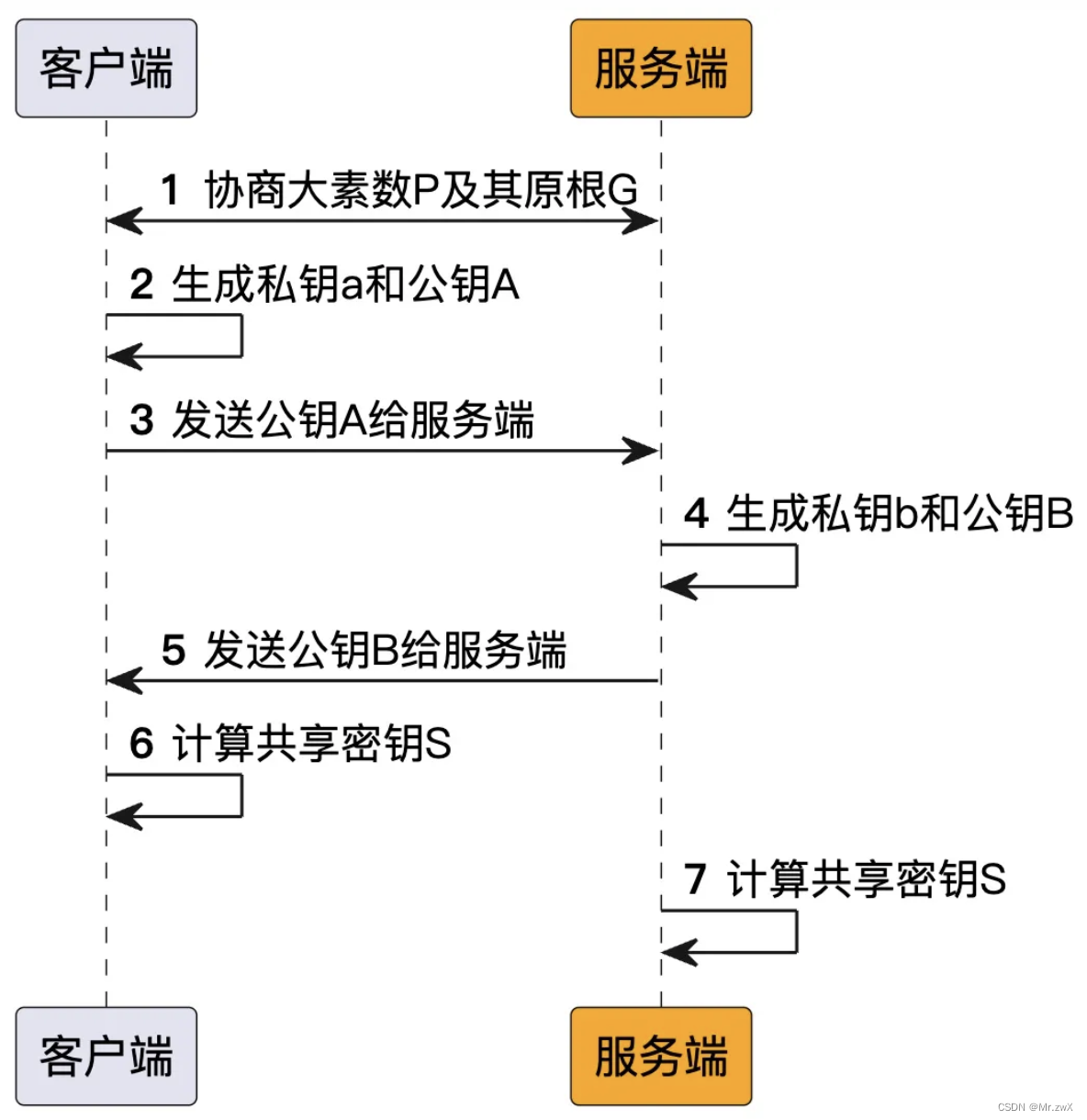
Diffie-Hellman密钥协议算法是一种确保共享密钥安全穿越不安全网络的方法。这个机制的巧妙在于需要安全通信的双方可以用这个方法确定对称密钥,然后可以用这个密钥进行加密和解密。但是注意,这个密钥交换协议双方确定要用的密钥后,要使用其他对称密钥操作加密算法实际加密和解密消息。
刚刚有个同学问我:“深层神经网络如果去掉一部分残差,到底还能不能正常训练呀?”这个问题着实很好,我也没思考过,也没尝试过,然后试着去Google Scholar检索了一下关键词“without shorcut”,于是看到了以下的文章。让我比较惊奇的是,这是个很多人研究的方向,并且近年来不少文章发表在AI三大会。其中包含:1)残差的融合提高效率(重参数化);2)去除一部分残差提高效率;3)用更好的架
