




- @qazwsxrx
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
它的核心思想是让智能体 (Agent) 在执行动作 (Action)、观察环境 (Environment) 反馈的状态 (State) 和奖励 (Reward) 的过程中,学习到一个最优策略 (Optimal Policy),从而实现长期累积奖励最大化。深度强化学习通过结合深度学习 (Deep Learning) 和强化学习,利用神经网络 (Neural Network) 作为函数逼近器 (Fun
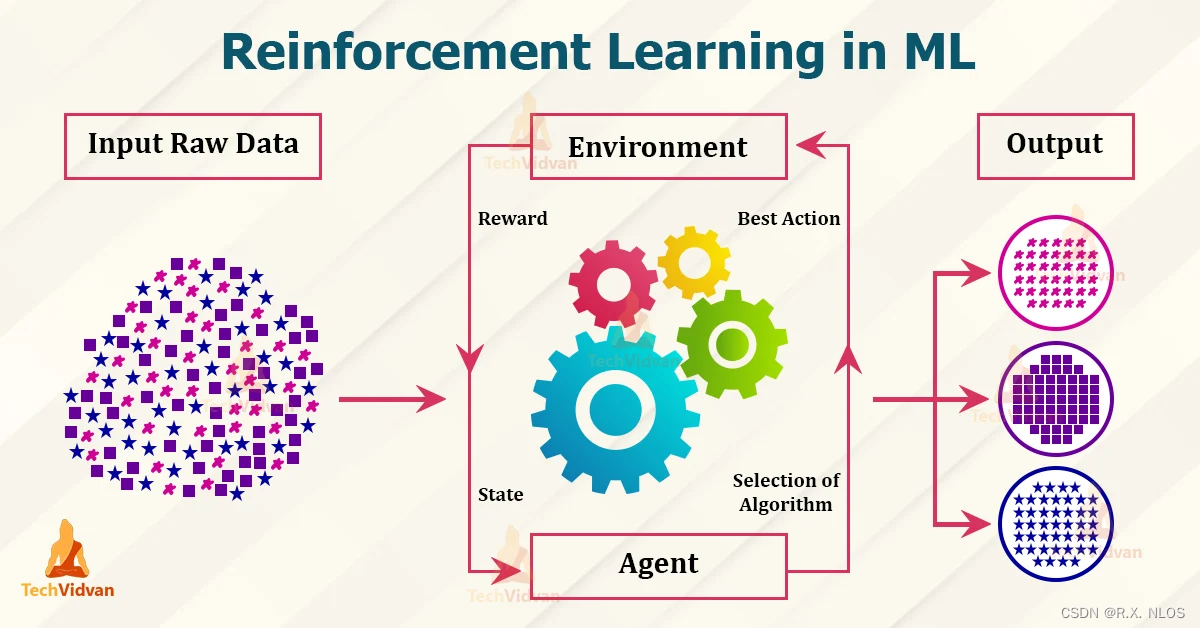
目录问题描述解决方法问题描述遇到的问题:运行某篇文章的代码时需要编译并安装第三方库(detectron2),该库仅支持到CUDA 11.1, 而5台GPU服务器中4台默认的cuda (即/usr/local/cuda/)版本是11.6, 另一台gpu5是10.1.因此,创建了conda环境env1,并在gpu5上成功安装了detectron2 (pytoch 1.5 + cuda 10.1版本)但
发现了chrome一个很好用的能够修改User Agent的插件:User-Agent Switcher and Manager网址:https://chrome.google.com/webstore/detail/user-agent-switcher-and-m/bhchdcejhohfmigjafbampogmaanbfkg用法如下图,最左侧选择想要的UA,点击右下角按钮apply即可;通
最近一两个月电脑一直登不上TIM,报错信息为:00001:无法连接到互联网知乎:QQ无法登陆,显示:“登陆超时,请检查你的网络或者本机防火墙设置。错误码:0x00000001”?给出了很多解决方案,但只有一种能成功解决我遇到的问题:(QQ无法登陆,显示:“登陆超时,请检查你的网络或者本机防火墙设置。错误码:0x00000001”? - 小小小小尖的回答 - 知乎 )win + R, cmd,Ctr
使用CrossEntropy是常见到如上错误:例如:criterion = nn.CrossEntropyLoss()loss = criterion(logit, target.long())其中,logit: torch.Size([4, 31, 256, 256]); target:[4, 256, 256, 1]就会出现1only batches of sp...
问题Python的pdb断点调试不能放在pytorch dataset的__getitem__中,不然会报错但在实际调试的过程中,__getitem__中的内容常常很关键,需要单步调试。解决在创建完dataset后,建立如下断点pdb.set_trace()dataset[0]按s进入就可以发现正好进入到了__getitem__中,之后就可以在通过n或者在getitem中设置其他的断点然后c进行调
原因:在网络本身有随机变量的情况下,随机变量很可能是在定义网络时按照预设的batchSzie确定的维度。这样,如果总的训练集的Size不能被batchSize整除,就会出现网络输入数据的Size和生成的随机变量的size在Batchsize那个维度上不匹配的问题,从而报错。解决:调整BatchSize使其能够整除Size;或调整数据集大小使其能够被BatchSize整除。或检查输入数据的batch
雷达,是英文Radar的音译,源于radio detection and ranging的缩写,意思为"无线电探测和测距"。它的基础作用包括测量目标的距离、角度、方位、速度信息。本文对它测量上述四个信息的方法做简单总结。1. 距离测量脉冲法:到达和返回时间之间的差异;调频法;相位法:相位之间的差异,2Π对应一个波长;2. 目标角度的测量利用雷达天线波束的有效性进...
报错信息Traceback (most recent call last):File "selfdeblur_ycbcr.py", line 91, in <module>net_input_kernel.squeeze_()RuntimeError: set_storage_offset is not allowed on a Tensor created from .data or
图像的采样和量化是数字图像获取、存储中的必要步骤。根据奈奎斯特采样定律:An analog signal can be perfectly reconstructed form its samples as long as the sampling frequency is at least twice the amount of the maximum frequency compone...