




- @projectfailed
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本章系统阐述了现代智能体的思考机制,聚焦大语言模型(LLM)的核心原理。首先回顾了从N-gram统计模型到神经网络语言模型的演进过程:N-gram通过马尔可夫假设简化概率计算,但面临数据稀疏和泛化能力差的问题;神经网络语言模型则通过词嵌入技术,将词语映射到连续向量空间,有效捕捉语义关系。文章通过具体案例和Python代码演示了Bigram概率计算过程,并分析了词向量的代数运算特性,揭示了LLM理解

本文介绍了从RNN到Transformer的自然语言处理模型演进过程。首先分析了RNN通过隐藏状态实现序列记忆,但存在长期依赖问题;LSTM通过细胞状态和门控机制优化了记忆能力。随后重点解析了Transformer架构,它完全依赖注意力机制实现并行计算,采用编码器-解码器结构:编码器理解输入句子,解码器生成目标输出。文章还提供了基于PyTorch的Transformer核心代码框架,包含位置编码、

本文探讨了与大语言模型交互的提示工程技巧。首先介绍了温度(Temperature)、Top-k和Top-p等采样参数的作用机制,温度控制输出随机性,Top-k/p决定候选词范围。其次分析了零样本、单样本和少样本提示策略的适用场景,示例数量影响模型理解任务的能力。文章还强调了指令调优对模型响应质量的影响,并分享了角色扮演、上下文示例等实用提示技巧。特别介绍了思维链(CoT)方法,通过分步推理显著提升

本文深入解析了Transformer中的多头注意力机制(MultiHeadAttention)。首先通过"it"指代"agent"的例子形象说明了自注意力机制的作用:让模型在处理每个词时都能关注句子中其他相关词。核心概念Q(查询)、K(键)、V(值)被比作开卷考试中的考题、章节标题和具体内容。计算过程包括:1)生成QKV向量;2)计算相关性得分;3)缩放和归

摘要: 分词(Tokenization)是大模型处理文本的基础环节,将字符转换为数字序列。早期方法(按词或字符分词)存在词表爆炸或语义缺失问题,现代模型普遍采用子词分词(如BPE算法),通过合并高频字符对构建词表,平衡语义与效率。分词器影响显著:1)模型上下文窗口按Token计数,中文更占资源;2)API成本与Token数量挂钩;3)分词差异可能导致模型表现异常(如数学运算错误)。开发者可通过调整

本文探讨了从Transformer到GPT的演变过程,重点分析了Decoder-Only架构及其核心机制。GPT通过简化Transformer架构,仅保留解码器部分,采用"预测下一个词"的自回归工作模式。这种架构依靠掩码自注意力机制,确保模型仅基于已生成内容进行预测。其优势在于训练目标统一、结构简单易扩展、天然适合生成任务,成为GPT-4、Llama等主流大模型的标准范式,开启

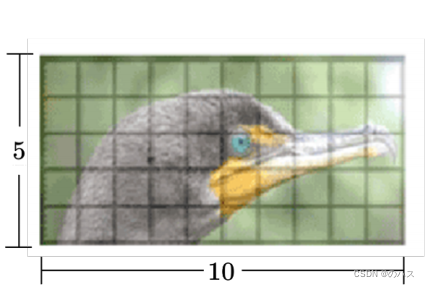
自注意力还可以被用在图像上。到目前为止,在提到自注意力的时候,自注意力适用的范围是输入为一组向量的时候。一张图像可以看作是一个向量序列,如图所示,一张分辨率为 5 × 10 的图像可以表示为一个大小为 5 × 10 × 3 的张量,3 代表 RGB 这 3 个通道(channel),每一个位置的像素可看作是一个三维的向量,整张图像是5 × 10 个向量。所以可以换一个角度来看图像,图像其实也是一个
本文详细解析了Transformer架构中的关键组件:1) 逐位置前馈网络(FFN)通过"先扩大再缩小"的瓶颈结构提取高阶特征;2) 残差连接与层归一化(Add & Norm)解决了梯度消失问题并稳定训练;3) 位置编码通过正弦/余弦函数为词元注入位置信息。文中给出了PyTorch实现代码,包括PositionwiseFeedForward和PositionalEnco

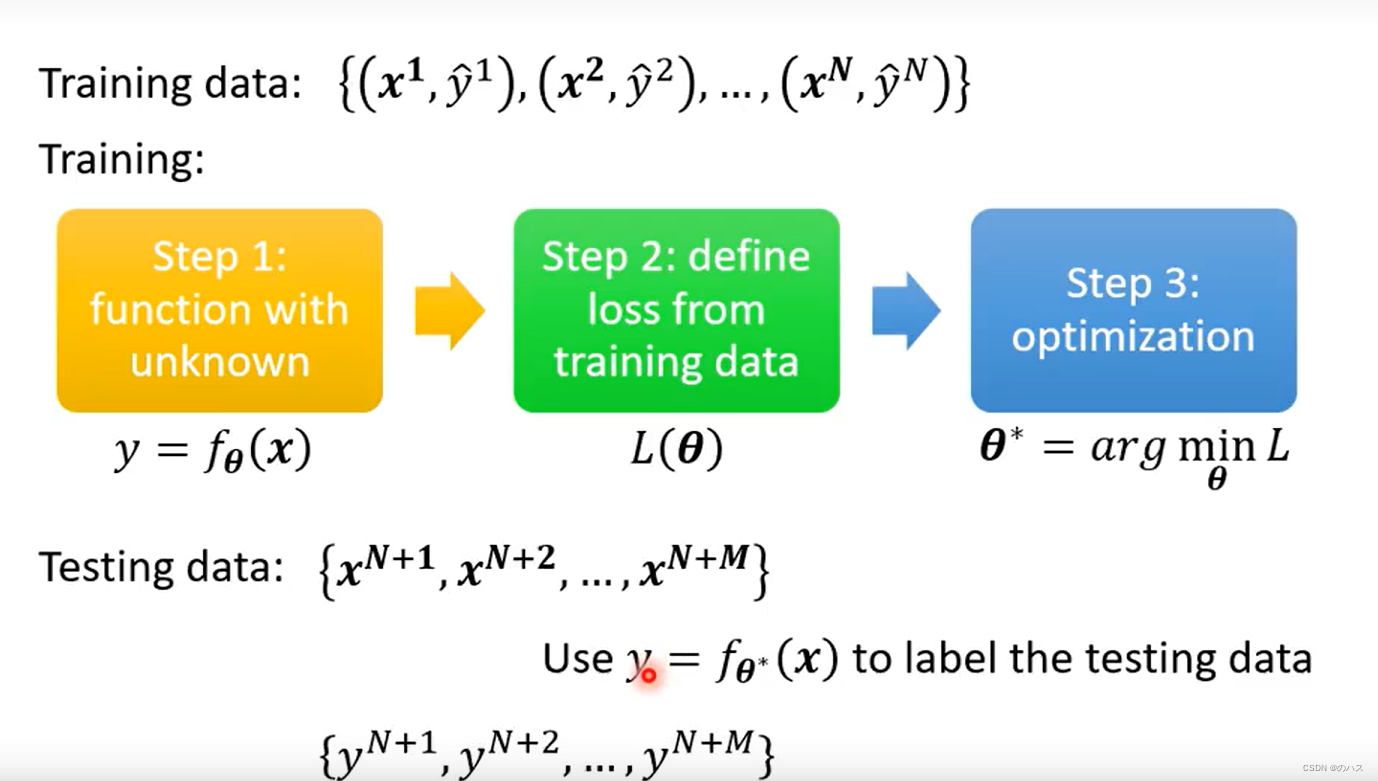
用训练数据训练自己写的函数,找到使Loss最小的参数组,用这个最小的参数组将需要预测的featrue放到函数中得到预测值y。
缺乏语义理解:系统不理解词义。例如,面对的输入,它仍会机械地匹配I am (.*)规则,可能生成“How long have you been not happy?” 这样语义略显生硬的回应,因为它无法理解否定词not的作用。无上下文记忆 (Stateless):系统是无状态的,每次回应仅基于当前单句输入,无法进行连贯的多轮对话。规则的扩展性问题:尝试增加更多规则会导致规则库规模爆炸式增长,规则间
