- @m0_75077001
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要:OpenStory是一个基于大模型的多智能体叙事实验室项目,旨在通过AI技术重现经典文学角色的互动。该项目由浙江大学LLMs实验室开发,通过精细构建数字化场景(如大观园)和智能体性格对齐,实现角色自主决策与实时对话。技术亮点包括Prompt Engineering、长短期记忆管理和AgentKernel框架应用,大幅提升开发效率。该项目已开源,欢迎参与探讨多智能体在文化叙事中的可能性。Git

概念:如何在指定的输出设备上,根据坐标描述,构造基本二维几何图形基本二维几何图形:点、直线、圆、多边形域、字符串及相关属性等。是在指定的输出设备上,根据坐标描述构造二维几何图形。图形的扫描转换:在光栅显示器等数字设备上,确定一个醉驾逼近于图形的像素集的过程。光栅就是德语中屏幕的意思,光栅化就是把图形画在屏幕上的过程,即将几何图形转化为像素化图像的过程。基本过程:直线段和圆是最基本的图形元素,包括以
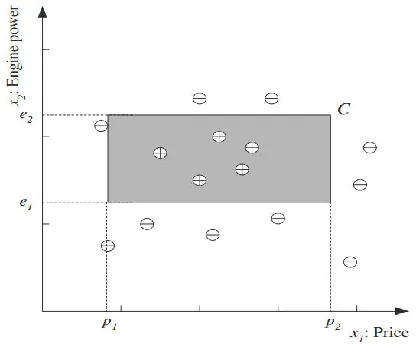
属性为:价格和发动机的马力xx1x2r1正例0负例Xxtrtt1N。
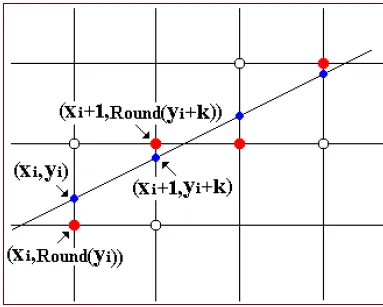
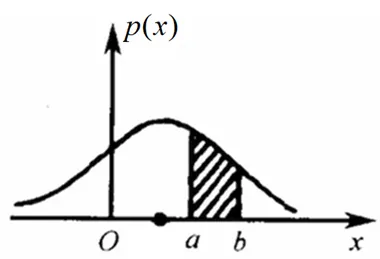
如果一个样本在特征空间中的 k 个最邻近 (即最相似)的样本中的大多数属于某一个类别,则该样本也属于这个类别。→KNN的决策边界仅由靠近类别边界的样本决定,而远离边界的样本(如类别内部的点)对分类结果无影响。定义:相容子集是训练集的一个最小子集,能够保持与原训练集完全相同的分类决策边界。随机变量 x 的取值落在某个区域之内的概率则为概率密度函数在这个区域上的积分。目标:仅保留边界附近的样本(相容子
第一步,将取数指令传入控制单元:PC->MAR->存储体->MDR->IR->CU。第一步,将存数指令发给控制单元:PC->MAR->存储体->MDR->IR->CU。存储字长:存储单元中二进制代码的位数,每个存储单元有一个地址。第二步:执行取数指令:IR->MAR->存储体->MDR。PC:程序计数器,用于存放当前欲执行指令的地址。IR:指令寄存器,用于存放当前欲执行的指令。将内存单元中的加数送

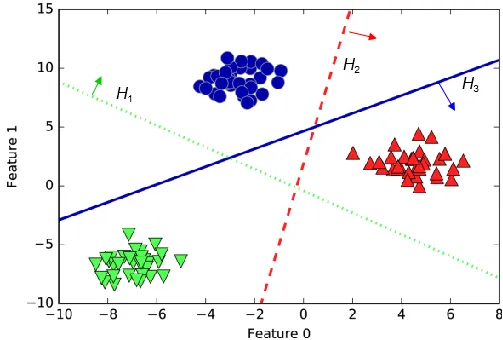
优点可灵活处理各类数据在相对少的调参情况下,预测准确率也可以比较高对异常值鲁棒性强。

属性为:价格和发动机的马力xx1x2r1正例0负例Xxtrtt1N。
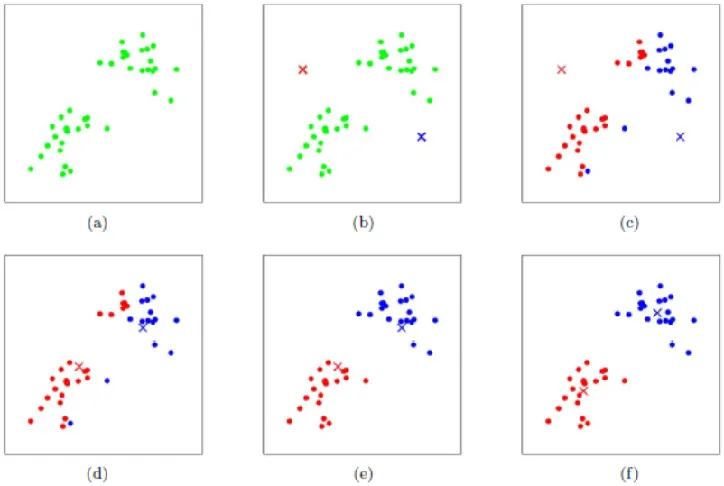
假设数据由k个高斯分布混合生成,每个高斯分布表示一个潜在的子群或簇。我们不知道样本点x属于哪个簇,因此需要PGiP(G_i)PGi表示该点属于某个簇的概率。目标:估计模型参数miSiPGimiSiPGi挑战:存在隐变量Z(样本所属簇的标签),直接最大化似然函数困难。似然函数:不完全似然(未观测到隐变量Z(数据点所属的高斯分布))Lθ∣X∑ilog∑j1kPGj⋅pxi∣GjLθ∣Xi∑。
第一步,将取数指令传入控制单元:PC->MAR->存储体->MDR->IR->CU。第一步,将存数指令发给控制单元:PC->MAR->存储体->MDR->IR->CU。存储字长:存储单元中二进制代码的位数,每个存储单元有一个地址。第二步:执行取数指令:IR->MAR->存储体->MDR。PC:程序计数器,用于存放当前欲执行指令的地址。IR:指令寄存器,用于存放当前欲执行的指令。将内存单元中的加数送
产生式模型需要计算输入、输出的联合概率判别式模型直接构造判别式gix∣θi,显式定义判别式参数,不关心数据生成过程基于判别式的方法只关注类区域之间的边界一般认为,估计样本集的类密度比估计类判别式更困难,因为构造判别式通常采用简单的模型gix∣wiwi0wiTwi0j1∑dwijxjwi0广义上,线性判别式代表了一类机器学习模型狭义上,线性判别式仅代表逻辑回归。