- @m0_74398756
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
OpenClaw 的爆火,从来不是偶然。在它之前,AI 智能体概念已经火了两年,无数大厂、创业公司都推出过相关产品,但始终没能走出极客圈。过去三年,大模型的推理能力已经达到了前所未有的高度,但始终卡在 “说” 和 “做” 之间的鸿沟里。你让 GPT 写一个 Python 脚本,它能给你完美的代码,但你还是要自己复制到编辑器里、安装依赖、调试运行、处理报错。

2026年AI编程助手选型指南:GPT-5.4 vs Claude4.6 通过对OpenAI GPT-5.4和Anthropic Claude4.6的实测对比,本文得出关键结论: GPT-5.4在单环节代码能力(补全/Bug修复/终端命令)上更优,继承了Codex全部能力; Claude4.6在长上下文处理(1MToken)和全量代码库分析上优势明显; 最佳实践是组合使用:Claude4.6用于架

本文详细介绍了如何基于阿里云百炼平台(Qwen模型)和LangChain框架构建智能对话应用。主要内容包括:1)API Key申请与配置流程;2)环境安装与基础模型调用;3)LangChain核心功能模块详解(Chat Model、Prompt Template、Few-Shot提示、Output Parser和LCEL Chain);4)多轮对话实现与参数调优技巧。所有代码示例均通过实际运行验证

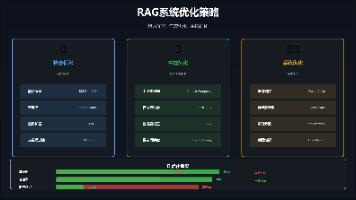
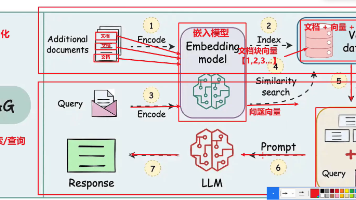
本文介绍了LangChain RAG系统的完整实战案例与优化策略。主要内容包括: 项目结构设计:展示了RAG系统的模块化架构,包含文档加载、文本分割、向量存储等核心组件。 完整实现案例:提供了基于阿里云百炼(Qwen)和ChromaDB的完整代码实现,涵盖配置管理、文档处理、向量存储和查询链构建。 核心功能实现: 支持PDF文档加载与处理 实现文本分块与向量化存储 构建完整的RAG查询流程 提供源
Claude Desktop 是 Anthropic 官方推出的桌面客户端,默认需要登录才能使用,且只支持 Claude 系列模型。免登录:开启开发者模式 + 配置三方推理网关接入 DeepSeek:使用 CC Switch 工具进行模型转接中文汉化:使用开源补丁将界面切换为中文Step 1 下载并安装 Claude Desktop↓Step 2 不要登录!Help → Troubleshooti
本文介绍了LangChain RAG系统的三大核心模块:向量存储、语义检索和Chain构建。在向量数据库部分,对比了ChromaDB、FAISS等主流方案,并展示了ChromaDB的存储、加载和操作代码。语义检索部分详细讲解了相似度搜索、MMR检索等技术实现。最后,通过代码示例演示了如何构建完整的RAG Chain流程,包括Prompt模板设计、检索结果格式化和LLM集成。全文提供了完整的Pyth
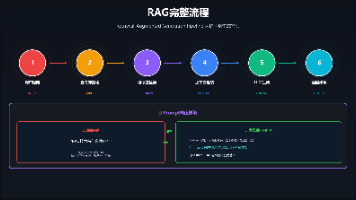
本文介绍了LangChain RAG系统的数据预处理环节,主要包括文档加载、文本分割和嵌入向量化三大模块。RAG技术通过检索增强生成解决大语言模型的局限性,如知识时效性、幻觉问题和领域知识缺乏等。文章详细讲解了环境配置、多种文档加载器(PDF/Word/TXT)的使用方法,以及不同文本分割策略(递归字符分割、段落分割、Token分割)的实现和对比。通过代码示例展示了如何将原始文档处理为适合检索的文
Claude Desktop 是 Anthropic 官方推出的桌面客户端,默认需要登录才能使用,且只支持 Claude 系列模型。免登录:开启开发者模式 + 配置三方推理网关接入 DeepSeek:使用 CC Switch 工具进行模型转接中文汉化:使用开源补丁将界面切换为中文Step 1 下载并安装 Claude Desktop↓Step 2 不要登录!Help → Troubleshooti
Claude Desktop 是 Anthropic 官方推出的桌面客户端,默认需要登录才能使用,且只支持 Claude 系列模型。免登录:开启开发者模式 + 配置三方推理网关接入 DeepSeek:使用 CC Switch 工具进行模型转接中文汉化:使用开源补丁将界面切换为中文Step 1 下载并安装 Claude Desktop↓Step 2 不要登录!Help → Troubleshooti
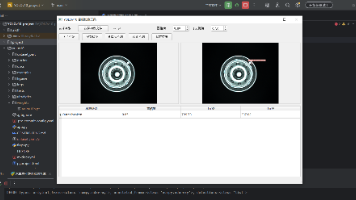
本文介绍了YOLOv10轮毂缺陷检测系统的模型推理与PyQt5可视化应用开发。主要内容包括: 模型推理测试:通过命令行脚本验证训练好的模型权重,详细解析了推理API的使用方法和检测结果的数据结构。 PyQt5应用架构设计:采用分层架构将UI布局、业务逻辑和检测线程分离,重点说明多线程设计的必要性以避免界面卡顿。 UI布局实现:展示了可视化检测界面的结构设计,包括模型选择、参数设置、结果显示等功能区