




- @m0_73202283
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
也有MLP和linear classifier分类分割区域。解决混淆的输入:对于一个prompt,模型会输出3个mask,实际上也可以输出更多的分割结果,3个可以看作一个物体的整体、部分、子部分,基本能满足大多数情况。使用IOU的方式,排序mask。在反向传播时,参与计算的只有loss最小的mask相关的参数。point和box可以作为一类使用position encodings, text可以使
其中d代表两个样本特征的欧氏距离,y为两个样本是否匹配的标签,y=1代表两个样本相似或者匹配,y=0则代表不匹配。margin为设定的阈值,这种损失函数主要是用在降维中,即本来相似的样本,在经过降维(特征提取)后,在特征空间中,两个样本仍旧相似;而原本不相似的样本,在经过降维后,在特征空间中,两个样本仍旧不相似。CondenseNet的剪枝并不是直接将这个特征删除,而是通过掩码的形式将被剪枝的特征
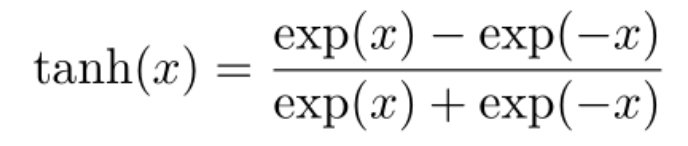
左边是分子布局,右边是分母布局,一般都用分母布局。

非书中全部内容,只是写了些自认为有收获的部分。

值得注意的是,我们发布了一个全面的工具增强数据集MSAgent-Bench,其中包括598k个带有各种API类别的对话,多轮API调用,面向API的QA和API不可知性的中英文指令。为了方便构建一个能够使用工具的Agent,同时保持最佳的用户参与度,我们发布了一个综合的工具数据集,MSAgent-Bench7,利用ChatGPT合成数据和现有的指令遵循数据集。在人类的指令下,Agent将选择的LL

过拟合是指在训练数据上效果好,测试数据上效果差,对训练数据太拟合太贴切;欠拟合则相反,往往是模型太简单或者训练轮次不够。说到激活函数,最主要的作用是引入非线性,特别是在深度学习中,如果没有激活函数,多层神经网络始终可以用两层来代替。额,不知道为什么要在这里这样引入sigmoid函数,有点怪怪的,但确实用无限多的分段函数就能拟合很多曲线。一开始假设的模型是y=b+w1,但在可视化预测值和真实值后,发

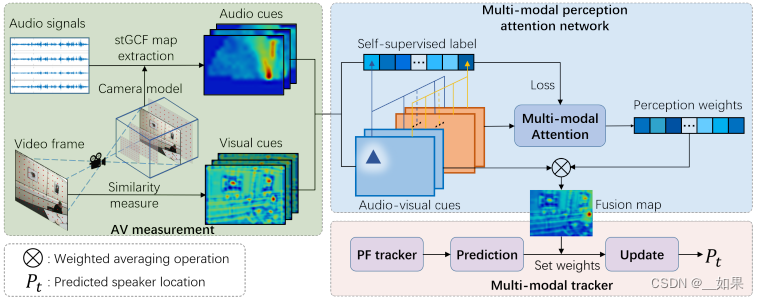
提出基于空间-时间全局相干场(stGCF)的新型声学地图,利用摄像机模型做特征映射提出一种跨模态自监督学习方法。
现需要用线性模型做分类问题,简单的阶跃函数在阈值处不可导,可导处导数均为0,性质不好所以把0,1问题转化成P(y=0|x),P(y=1|x)的问题,这样就把离散的分类任务变成了求概率分布的回归任务,概率分布要求在(0,1)之间,且需要光滑连续的曲线才会有较好的梯度,所以定义逻辑斯谛函数。

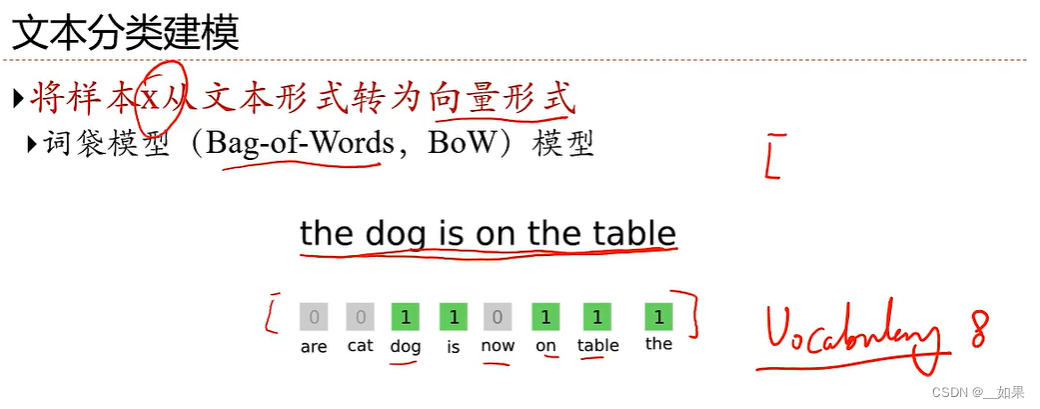
根据以上定义可知:交叉熵是用来衡量两个分布之间的差异的。a:投票法,f1将w1作为正类,w2、w3作为负类。最小化KL散度其实就是最小化两个分布的交叉熵。区别在于用的损失函数不同,导致模型不同。概率越大,信息量越小,熵越小,编码越短。所以最小化交叉熵就是求对数似然的最大值。而pr(y|x)是one-hot向量。取log是因为要满足自信息的可加性。当p的分布未知时,设q为概率分布。缺点:把文本中的语
轻松玩转书生·浦语大模型趣味 Demo
