- @m0_60827485
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要 在具身智能系统中,大语言模型(LLM/MLLM)和世界模型各司其职:LLM负责语义理解和任务规划,世界模型则专注于物理预测和状态模拟。LLM的优势在于开放世界的知识推理和任务分解,但其物理理解、空间推理和实时控制能力有限,容易产生幻觉和累积错误。世界模型通过内部状态估计和动作后果预测,弥补了LLM在物理实现方面的不足,支持安全验证、长时规划和数据高效学习。两者协同工作,形成从语义理解到物理执
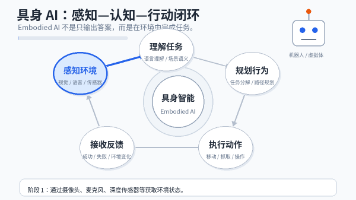
具身智能(Embodied AI / Embodied Intelligence)是指具有某种“身体”或可作用于环境的载体,能够在真实或仿真环境中进行感知、推理、决策、行动和学习的智能系统。这里的“身体”既可以是人形机器人、机械臂、移动机器人、无人机,也可以是虚拟环境中的智能体。智能体的动作会改变环境;环境变化又会产生新的感知输入;系统必须在不确定、动态、实时的条件下持续闭环运行;认知能力受到身体
大模型赋能家庭服务机器人的场景适应 本文探讨了大模型如何提升家庭服务机器人在整理、照护、递送、安防等综合场景中的适应能力。传统清扫机器人功能单一,难以理解复杂指令和动态环境。大模型通过自然语言理解、多模态场景解析、家庭常识推理等能力,使机器人能够:1)解析模糊指令并生成任务计划;2)结合视觉和语义理解物体用途;3)动态组合导航、抓取等基础技能;4)根据环境反馈调整行为;5)形成个性化服务记忆。技术
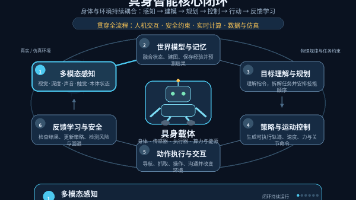
本文探讨了大模型在具身智能系统中的核心作用,重点聚焦其作为认知中枢和规划器的功能定位,以及解决长程规划问题的关键技术。大模型通过自然语言理解、语义解释、任务分解、技能调度、动态重规划和知识管理六大角色,将抽象目标转化为可执行步骤。针对长程规划中的复杂依赖关系,提出了目标分解、层次化规划、可供性约束和闭环反馈等机制,使智能体能在动态环境中完成多阶段任务。文章还提供了系统框架、评估指标和典型案例分析,
大模型如何增强模仿学习与强化学习? 大模型通过语义理解、任务分解和知识迁移,显著提升模仿学习(IL)和强化学习(RL)的效果。在模仿学习中,大模型可生成示范数据、增强意图理解(如自动驾驶中理解“减速”的深层原因),并拆分复杂任务(如家庭机器人整理书桌的分步指令)。对于强化学习,大模型可充当奖励模型(评价行为是否符合人类偏好)或策略规划器(高层任务分解,如准备早餐的步骤指导)。典型案例RT-2模型结
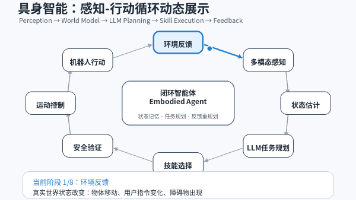
本文探讨了具身智能(Embodied AI)的核心架构与实现路径,重点解析了感知-行动循环(Perception-Action Loop)的工作机制以及大语言模型(LLM)在任务规划中的关键作用。通过分层架构(用户目标层、认知规划层、技能执行层、控制反馈层)展示了具身智能系统的闭环运行流程,强调LLM在高层认知(目标分解、语义理解、常识推理)而非底层控制中的价值。文章详细拆解了感知模块的多模态数据
在 Ubuntu 22.04 + VS Code 环境下运行 Spring Boot 项目的完整指南: 安装JDK 21:推荐使用SDKMAN或直接通过apt安装(需配置环境变量); 安装Maven:通过apt或手动安装最新版,并验证Java版本为21; 配置VS Code:安装Java扩展包和Spring Boot扩展包,设置JDK 21路径; 运行项目:通过VS Code或命令行启动Sprin
spdlog日志库在机器人项目中的实践指南 spdlog是一个高性能C++日志库,具有以下特点: 支持同步/异步日志、多线程、多种输出方式(控制台/文件/滚动文件) 核心组件包括Logger、Sink、Formatter和日志等级管理 推荐工程实践: 模块化使用独立Logger 采用文件滚动日志(如20MB/文件,保留10个) 统一日志格式包含时间、模块、等级和线程信息 异步日志适合高频数据处理场
SAM2Act是一个面向机器人操作的多视角视觉-动作策略模型,整合了视觉基础模型SAM2和多视角Transformer策略,擅长处理空间记忆和多步骤操作任务。该项目在RLBench等基准测试中表现优异,但仿真复现和工业落地难度较高。 最小成本复现建议使用预训练模型在RLBench/MemoryBench上验证流程,硬件推荐RTX 3090/4090。工业落地需拆分为训练端(Python/PyTor