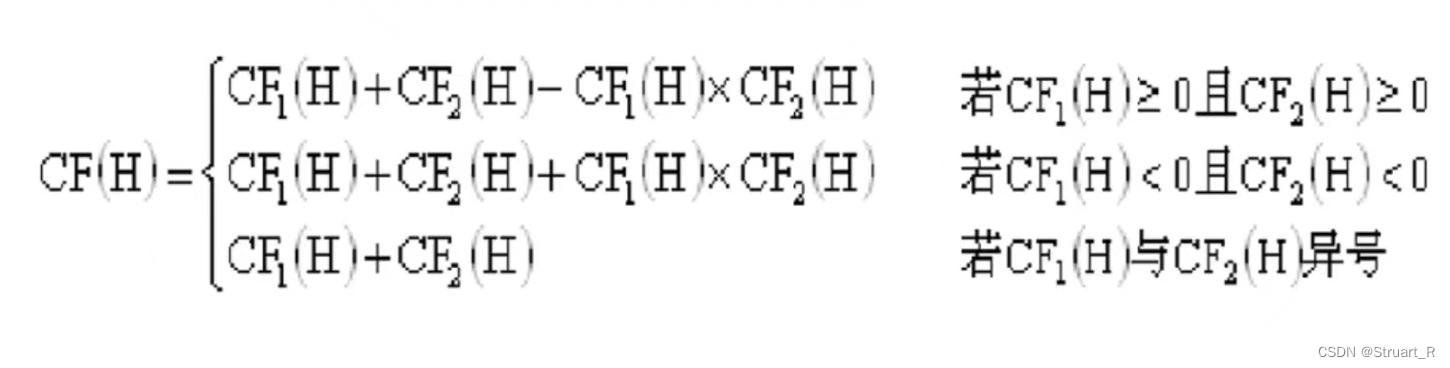写文章




- @m0_60177079
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
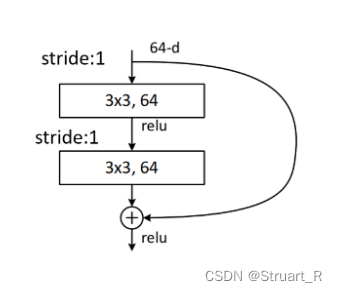
深度学习(3)--ResNet&ResNext
ResNet和ResNext网络的原理概述和实现
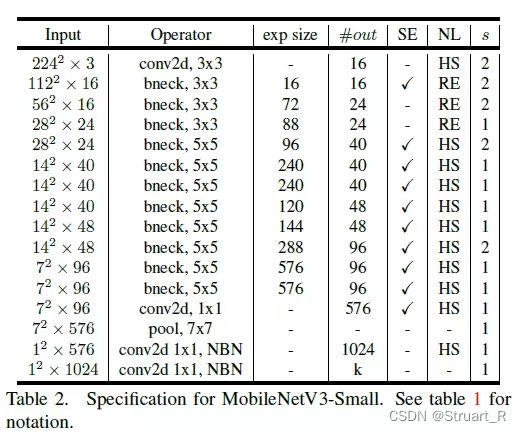
深度学习--关于MobilenetV3-small模型(2)
MobileNet系列的简介及MobileNetV3-small的实现
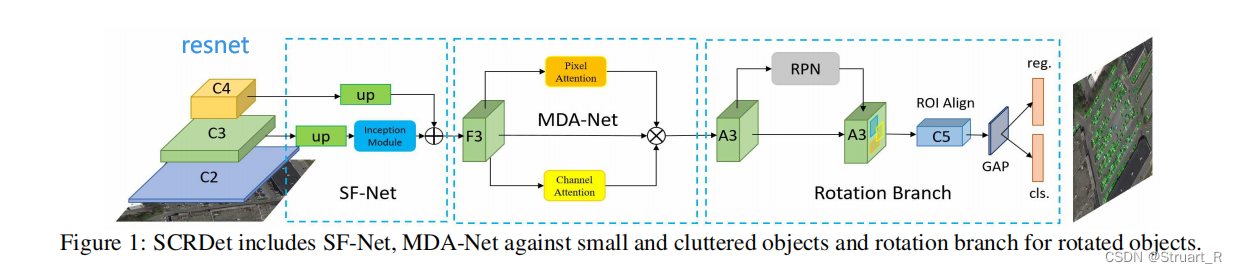
遥感目标检测(2)--SCRDet
SCR-Det论文的概述、提出的三个挑战、网络架构中SF-Net、MDA-Net、Rotation Branch的流程与参数设定,损失函数,对比实验与消融实验。
连接华为Atlas开发板踩雷
连接华为Atlas开发板踩雷,还原默认配置,连接开发板网口
PAGE-4D、4RC、Track4World论文解读
本文综述了三篇关于动态场景4D重建与3D跟踪的最新研究。PAGE-4D改进了VGGT架构,通过动态掩码预测模块区分处理静态与动态区域,并采用内存高效机制降低计算开销。4RC提出统一的前馈模型,通过几何头和运动头联合预测深度图和位移场,实现密集点轨迹重建。Track4World设计2D引导3D的跟踪策略,利用光流信息辅助3D场景流估计,并通过长短流监督优化训练过程。这些方法针对动态场景重建中的关键挑

Easi3R、VGGT4D、4D-VGGT论文解读
motivation:MonST3R,CUT3R,DAS3R等静态场景重建模型向动态场景扩展的工作,一般都需要额外的几何先验,进行训练。contribution:依赖于DUSt3R模型(MonST3R),提出一种无需训练的4D重建适配方法Easi3R,可以在推理时适配,无需从零预训练或针对动态数据的微调。Easi3R中发现,DUSt3R的交叉注意力图,天然编码了丰富的相机和物体运动信息,可以分界处

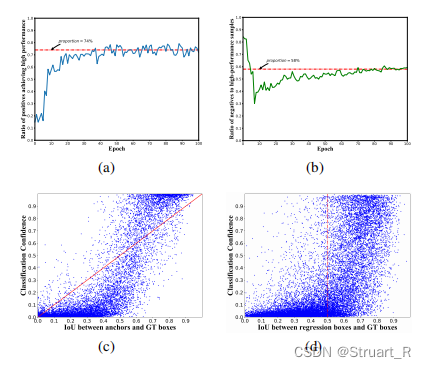
遥感目标检测(3)-DAL(Dynamic Anchor Learning for Object Detection)
DAL模块的背景,动态锚框的损失函数计算,匹配度的产生,实验
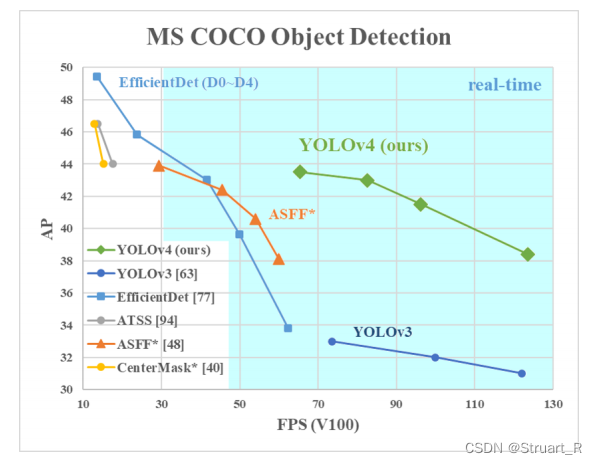
目标检测(3)--YOLOV4、YOLOV5
YOLOV4,YOLOV5网络结构,基本思想,改进
遥感目标检测(1)--R3Det
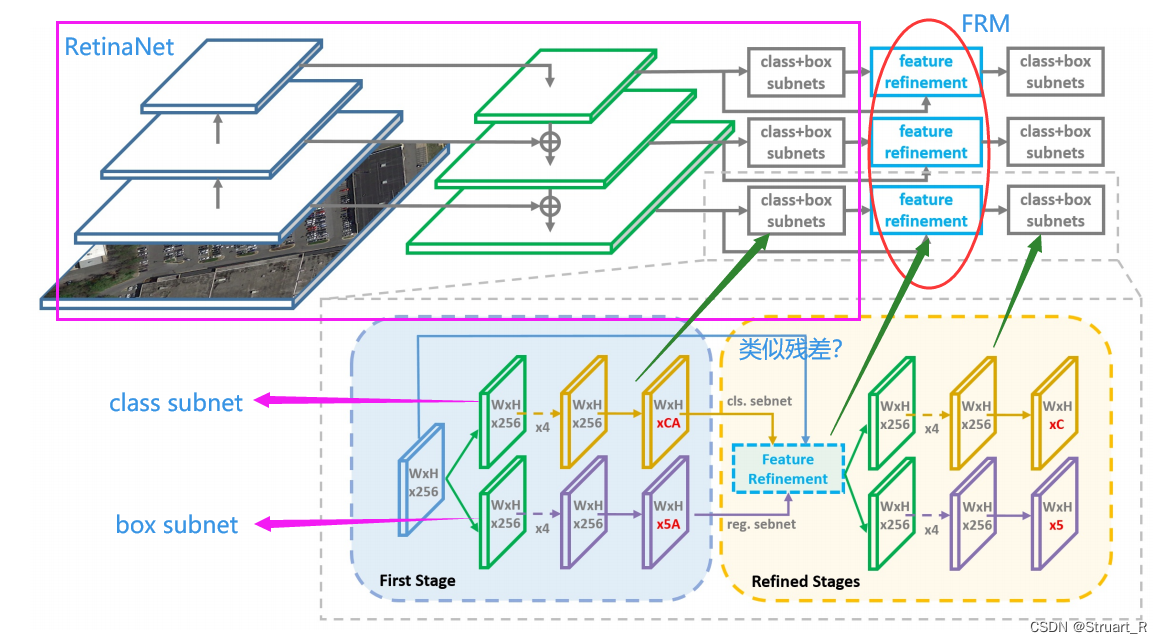
R3Det的概述、解决的问题、网络结构、特点与FRM算法,对比消融实验