




- @m0_37733448
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在生成式人工智能应用中,这种效率是通过分块来实现的。就像把一本书分成若干章节更便于阅读一样,分块法也能把重要的文本分成更小、更易于管理的部分,使其更易于处理和理解。
在无网络连接的环境中,部署Python应用时经常需要预先准备基础的依赖包。尤其是当使用Docker容器,而容器配置不允许联网时,手动安装依赖包成为必要步骤。在某些场景下,Docker容器可能只包含最基础的依赖,且不允许联网。通过这种方法,我们可以确保在无网络环境下也能顺利安装所有必需的Python依赖包,从而保证应用的顺利部署和运行。--find-links={package_path}`:指定本

摘要通过下一个词预测进行语言模型预训练已被证明在扩展计算能力方面是有效的,但其发展受限于可用训练数据的数量。强化学习 (RL) 的扩展为人工智能的持续进步开辟了一条新的道路,其承诺是大型语言模型 (LLM) 可以通过学习使用奖励进行探索来扩展其训练数据。然而,先前发表的工作并未产生具有竞争力的结果。鉴于此,我们报告了我们的最新多模态 LLM——Kimi k1.5 的训练实践,包括其 RL 训练技术

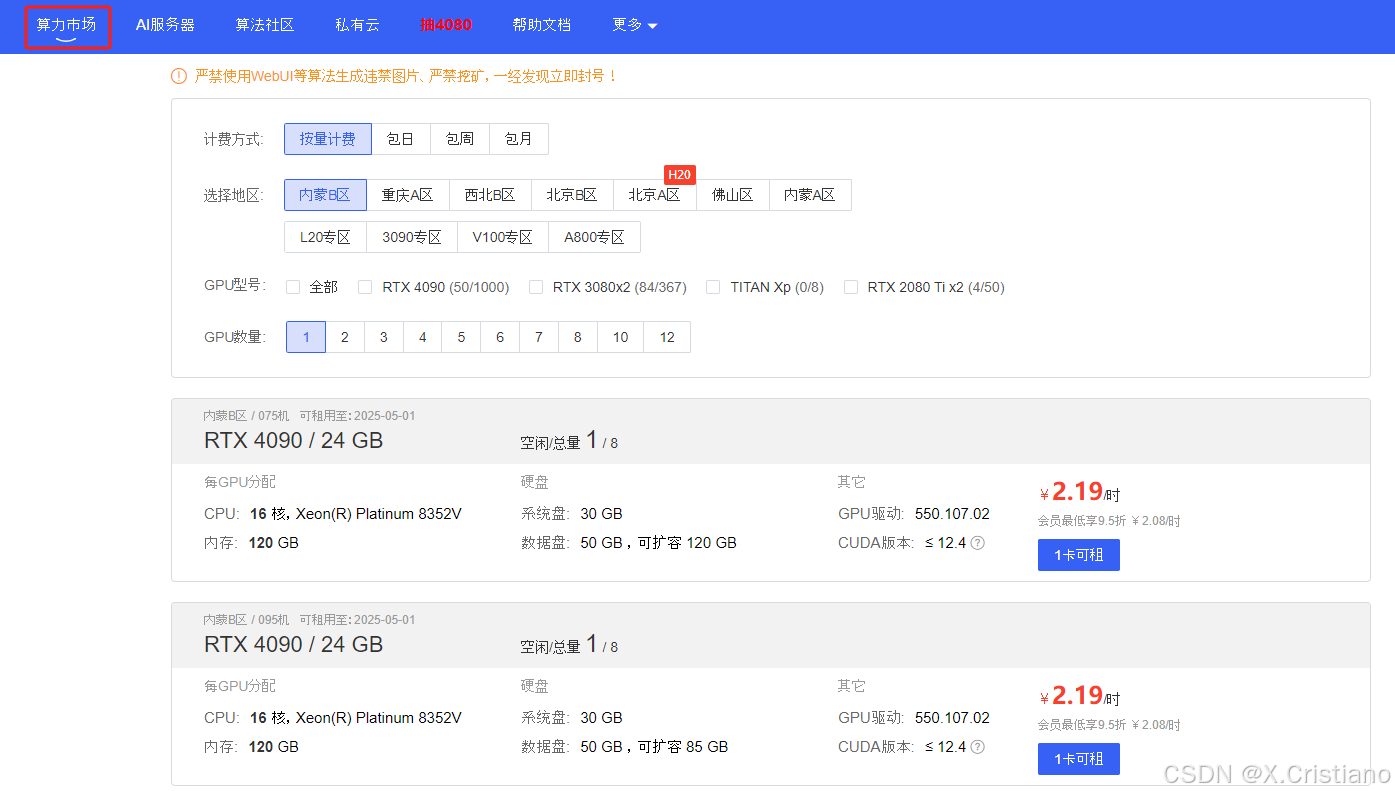
4、有一点比较友好的就是,在上传和下载模型的时候,可以开无卡模式,大大节约费用(说多都是泪,在其他平台都没有这个操作,当模型文件大的时候,实属大怨种)2、3090、4090、L20、L40、V100、A100、H800都有得租用哦,成为会员更加优惠一点。6、其他没有啦,跟家用的服务器差不多操作,可以利用xshell、filezilla等远程连接控制。对比过几家的GPU租用平台,Autodl操作算是
摘要通过下一个词预测进行语言模型预训练已被证明在扩展计算能力方面是有效的,但其发展受限于可用训练数据的数量。强化学习 (RL) 的扩展为人工智能的持续进步开辟了一条新的道路,其承诺是大型语言模型 (LLM) 可以通过学习使用奖励进行探索来扩展其训练数据。然而,先前发表的工作并未产生具有竞争力的结果。鉴于此,我们报告了我们的最新多模态 LLM——Kimi k1.5 的训练实践,包括其 RL 训练技术
知识(1)在 MMLU、MMLU-Pro 和 GPQA 等基准上,DeepSeek-V3 优于所有其他开源模型,在 MMLU 上达到 88.5,在 MMLU-Pro 上达到 75.9,在 GPQA 上达到 59.1。其性能与领先的闭源模型(如 GPT-4o 和 Claude-Sonnet-3.5)相当,缩小了开源与闭源模型在该领域的差距。(2)对于事实基准,DeepSeek-V3 在开源模型中在

知识(1)在 MMLU、MMLU-Pro 和 GPQA 等基准上,DeepSeek-V3 优于所有其他开源模型,在 MMLU 上达到 88.5,在 MMLU-Pro 上达到 75.9,在 GPQA 上达到 59.1。其性能与领先的闭源模型(如 GPT-4o 和 Claude-Sonnet-3.5)相当,缩小了开源与闭源模型在该领域的差距。(2)对于事实基准,DeepSeek-V3 在开源模型中在