




- @longshaonihaoa
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
作为cv的基础,数据增扩是很重要的一环。一般来说主要有以下几种:1、通过openCV操作 2、使用torchvision.transform3、使用torchvision.transform.function 4、使用nvidia.dali5、albumentations库。对应的数据也一般可以分为1、单图处理,如分类。2、同尺寸多个数据处理,如分割,去噪。3、不同尺寸多个数据处理,如超分。下面将
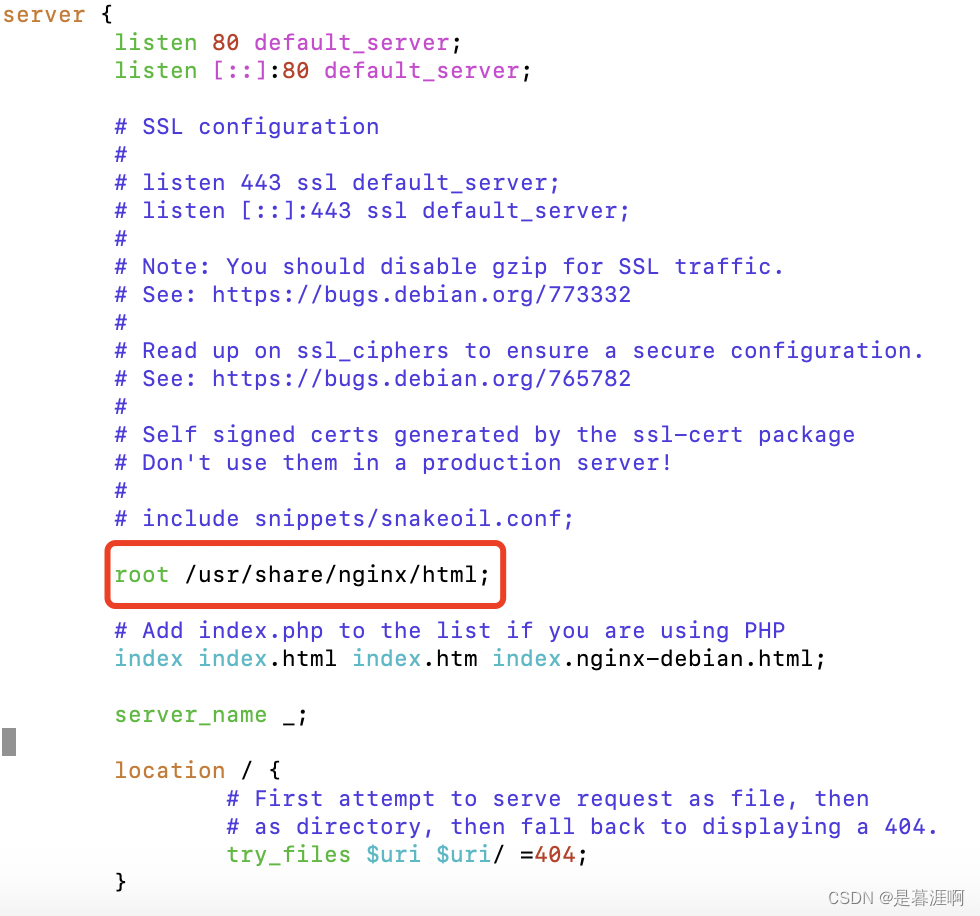
总结部署个人网站到服务器的教程
使用skimage的measure.label。可获得不同连通域from skimage import measurelabel, num = measure.label(les_array, connectivity=2, background=0, return_num=True)# 返回的label是将连通域标注为1,2,3。。。的标签# num 连通域个数参数介绍:详见:https://s
各位爷,我都不懂为啥搜的这么多奇奇怪怪的wget,yum什么的,都什么鬼,包还下不下来。直到我遇见了apt-get install -y htop好了,以上 is all。 感谢: 原链接
作为cv的基础,数据增扩是很重要的一环。一般来说主要有以下几种:1、通过openCV操作 2、使用torchvision.transform3、使用torchvision.transform.function 4、使用nvidia.dali5、albumentations库。对应的数据也一般可以分为1、单图处理,如分类。2、同尺寸多个数据处理,如分割,去噪。3、不同尺寸多个数据处理,如超分。下面将
记录几篇Transformer的超分辨率重建论文。1 Learning Texture Transformer Network for Image Super-Resolution(TTSR, CVPR2020)本文引用已经有200多了。 原文链接1.1 摘要文章做的是RefSR工作,主要观点是将Transformer作为一个attention,这样可以更好地将参考图像(Ref)的纹理信息转移到高
整理一下深度学习用于运动估计和运动补偿的论文列表。大致按照内容与时间区分。鉴于工作量太大,而且MEMC这块点击量很少,就不介绍文章内容了。
作为cv的基础,数据增扩是很重要的一环。一般来说主要有以下几种:1、通过openCV操作 2、使用torchvision.transform3、使用torchvision.transform.function 4、使用nvidia.dali5、albumentations库。对应的数据也一般可以分为1、单图处理,如分类。2、同尺寸多个数据处理,如分割,去噪。3、不同尺寸多个数据处理,如超分。下面将
整理一下深度学习用于运动估计和运动补偿的论文列表。大致按照内容与时间区分。鉴于工作量太大,而且MEMC这块点击量很少,就不介绍文章内容了。
整理一下深度学习用于运动估计和运动补偿的论文列表。大致按照内容与时间区分。鉴于工作量太大,而且MEMC这块点击量很少,就不介绍文章内容了。