




- @liuyueyi25
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了基于Spring AI框架搭建实时语音翻译机器人的完整实现方案。通过异步处理和SSE技术,实现了音频转录与文本翻译的并行处理流程。文章详细讲解了环境准备、API配置、核心依赖以及整体架构设计,重点突出了异步处理和SSE推送机制的优势。该方案支持用户上传音频文件或实时录音,后台通过SiliconFlow API完成语音识别和翻译,并实时推送处理结果到前端,提供流畅的用户体验。

SpringAI快速集成Claude Skills开发智能应用 摘要:本文介绍了如何利用SpringAI 2.0快速集成Claude Skills开发智能应用。通过构建一个Java代码审查工具(code reviewer)为例,展示了项目创建、环境配置、Skills定义等关键步骤。项目基于SpringBoot 4.0.1和JDK21,使用智谱GLM-4.5-Flash大模型作为核心引擎。重点讲解了

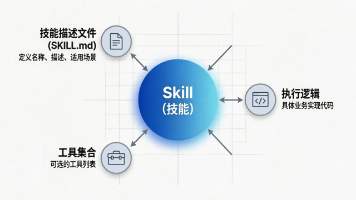
摘要:Spring AI Alibaba的Skill注册机制提供了一种模块化管理Agent能力的解决方案。该机制通过定义Skill(包含SKILL.md描述文件和执行逻辑)实现能力封装,解决了传统方式中Token浪费、决策困难等问题。核心组件包括SkillRegistry(支持Classpath和FileSystem两种加载方式)和SkillsAgentHook(提供技能元数据注入和渐进式披露功能
本文介绍了如何使用Spring AI Alibaba框架实现快递下单多轮对话助手。主要内容包括: 项目背景:快递下单需要分步骤收集收件人、发件人、物品等信息,是多轮对话的典型场景。 技术挑战:涉及状态管理、流程控制、上下文记忆和工具调用等难点。 解决方案:采用Spring AI Alibaba的React Agent和Model Hook机制,通过状态常量管理对话进度,分步骤收集信息并最终完成订单

SpringAI快速集成Claude Skills开发智能应用 摘要:本文介绍了如何利用SpringAI 2.0快速集成Claude Skills开发智能应用。通过构建一个Java代码审查工具(code reviewer)为例,展示了项目创建、环境配置、Skills定义等关键步骤。项目基于SpringBoot 4.0.1和JDK21,使用智谱GLM-4.5-Flash大模型作为核心引擎。重点讲解了
摘要:Spring AI Alibaba的Skill注册机制提供了一种模块化管理Agent能力的解决方案。该机制通过定义Skill(包含SKILL.md描述文件和执行逻辑)实现能力封装,解决了传统方式中Token浪费、决策困难等问题。核心组件包括SkillRegistry(支持Classpath和FileSystem两种加载方式)和SkillsAgentHook(提供技能元数据注入和渐进式披露功能
摘要:Spring AI Alibaba的Skill注册机制提供了一种模块化管理Agent能力的解决方案。该机制通过定义Skill(包含SKILL.md描述文件和执行逻辑)实现能力封装,解决了传统方式中Token浪费、决策困难等问题。核心组件包括SkillRegistry(支持Classpath和FileSystem两种加载方式)和SkillsAgentHook(提供技能元数据注入和渐进式披露功能
本文介绍了一个基于Spring AI Alibaba的智能SQL查询助手系统,实现了从自然语言到SQL的安全转换。系统核心特点包括:1) 自然语言转SQL功能;2) 人工审批机制,所有SQL执行需用户确认;3) 自动拦截危险SQL操作;4) 完整CRUD支持。技术栈采用Spring AI Alibaba框架、通义千问大模型、H2数据库和Spring Boot。文章详细解析了Human-in-the

ReAct(Reasoning + Acting)是一种先进的智能体编程范式,它将推理(Reasoning)和行动(Acting)有机结合,让 AI 系统能够像人类一样思考并执行任务。图 1: ReAct 核心循环流程图 - Thinking → Acting → Observing 顺时针闭环,展示智能体的基础运行模型首先,我们需要定义一些工具供 AI 调用(也用于后续的测试示例)。这里提供了几

本文介绍了基于Spring AI框架搭建实时语音翻译机器人的完整实现方案。通过异步处理和SSE技术,实现了音频转录与文本翻译的并行处理流程。文章详细讲解了环境准备、API配置、核心依赖以及整体架构设计,重点突出了异步处理和SSE推送机制的优势。该方案支持用户上传音频文件或实时录音,后台通过SiliconFlow API完成语音识别和翻译,并实时推送处理结果到前端,提供流畅的用户体验。