




- @lijincai134579
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要:在Dify平台添加通义千问模型时遇到API Key无效问题,可能是由于最新版本不兼容所致。解决方案是:进入插件市场,选择通义千问的历史版本,安装较稳定的旧版本即可解决兼容性问题。
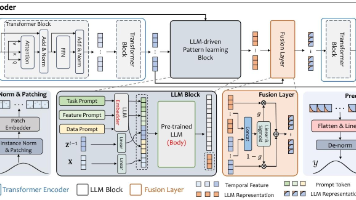
近年来,大型语言模型(LLMs)已在各类任务中展现出强大能力,因此近期研究将其应用于时间序列预测(TSF)任务——即利用给定的历史时间序列预测未来数值。现有的基于大型语言模型的方法,通过提示学习(prompting)或微调(finetuning)策略,将从文本数据中学习到的知识迁移到时间序列预测任务中。然而,大型语言模型擅长对离散 tokens(符号)和语义模式进行推理,但最初并非为建模连续数值型
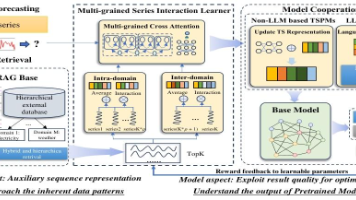
在流数据支撑各类应用的场景中,时间序列预测的重要性日益凸显。零样本时间序列预测(ZSF)在数据稀缺场景(如跨域迁移或极端条件下的预测)中具有极高价值,但传统模型难以应对这类场景。尽管时序预训练模型(TSPMs)在ZSF中展现出优异性能,但它们往往缺乏动态整合外部知识的机制。幸运的是,新兴的检索增强生成(RAG)技术为按需注入此类知识提供了可行途径,但RAG与TSPMs的融合仍较为罕见。为充分发挥两
近年来,大型语言模型(LLMs)已在各类任务中展现出强大能力,因此近期研究将其应用于时间序列预测(TSF)任务——即利用给定的历史时间序列预测未来数值。现有的基于大型语言模型的方法,通过提示学习(prompting)或微调(finetuning)策略,将从文本数据中学习到的知识迁移到时间序列预测任务中。然而,大型语言模型擅长对离散 tokens(符号)和语义模式进行推理,但最初并非为建模连续数值型
多元时间序列预测(MTSF)旨在对变量间的时间动态进行建模,以预测未来趋势。基于Transformer的模型和大语言模型(LLMs)因。
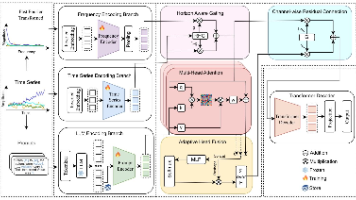
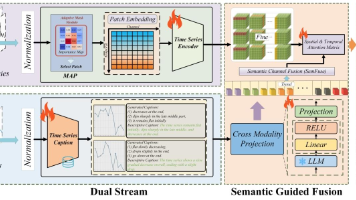
现有方法聚焦“时序-文本对齐”或“单一模式提取”,但未系统解决时序数据的双核心特性模式层面:需同时捕捉短周期波动(如小时级用电峰谷)与长期趋势(如季节性能源消耗);语义层面:需将连续时序区间转化为LLM可理解的语义(如“早8-10点功率持续上升”)。
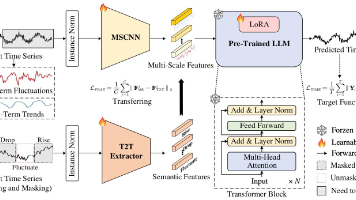
多变量时间序列预测在诸多应用中发挥着关键作用。近年来,已有研究探索将大型语言模型(LLMs)应用于多变量时间序列预测,以利用其推理能力。然而,许多方法将大型语言模型视为端到端预测器,这往往会导致数值精度损失,且迫使大型语言模型处理超出其设计初衷的模式。另一种思路是尝试在潜在空间中对齐文本模态与时间序列模态,但这类方法常面临对齐困难的问题。在本文中,我们提出不将大型语言模型视为独立预测器,而是将其作
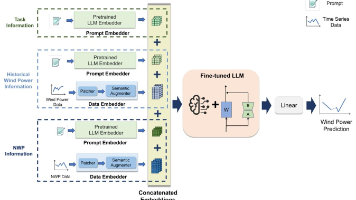
风能并入电网需要准确的超短期风电预测,以确保电网稳定性和优化资源配置。本研究引入了 M2WLLM,这是一种创新模型,它利用大型语言模型 (LLM)的功能以粒度时间间隔预测风电输出。M2WLLM 通过无缝集成文本信息和时间数值数据,克服了传统和深度学习方法的局限性,通过多模态数据显着提高了风电预测的准确性。其架构具有。
在流数据支撑各类应用的场景中,时间序列预测的重要性日益凸显。零样本时间序列预测(ZSF)在数据稀缺场景(如跨域迁移或极端条件下的预测)中具有极高价值,但传统模型难以应对这类场景。尽管时序预训练模型(TSPMs)在ZSF中展现出优异性能,但它们往往缺乏动态整合外部知识的机制。幸运的是,新兴的检索增强生成(RAG)技术为按需注入此类知识提供了可行途径,但RAG与TSPMs的融合仍较为罕见。为充分发挥两
摘要:在Dify平台添加通义千问模型时遇到API Key无效问题,可能是由于最新版本不兼容所致。解决方案是:进入插件市场,选择通义千问的历史版本,安装较稳定的旧版本即可解决兼容性问题。