QuiZSF:面向零样本时间序列预测的高效数据模型交互框架
在流数据支撑各类应用的场景中,时间序列预测的重要性日益凸显。零样本时间序列预测(ZSF)在数据稀缺场景(如跨域迁移或极端条件下的预测)中具有极高价值,但传统模型难以应对这类场景。尽管时序预训练模型(TSPMs)在ZSF中展现出优异性能,但它们往往缺乏动态整合外部知识的机制。幸运的是,新兴的检索增强生成(RAG)技术为按需注入此类知识提供了可行途径,但RAG与TSPMs的融合仍较为罕见。为充分发挥两
文章地址:https://arxiv.org/abs/2508.06915
摘要:在流数据支撑各类应用的场景中,时间序列预测的重要性日益凸显。零样本时间序列预测(ZSF)在数据稀缺场景(如跨域迁移或极端条件下的预测)中具有极高价值,但传统模型难以应对这类场景。尽管时序预训练模型(TSPMs)在ZSF中展现出优异性能,但它们往往缺乏动态整合外部知识的机制。幸运的是,新兴的检索增强生成(RAG)技术为按需注入此类知识提供了可行途径,但RAG与TSPMs的融合仍较为罕见。为充分发挥两者优势,我们将RAG引入TSPMs,以提升零样本时间序列预测性能。 本文提出零样本时间序列快速预测框架QuiZSF(Quick Zero-Shot Time Series Forecaster),这是一种轻量级模块化框架,将高效检索与表征学习、模型适配相结合,专门用于ZSF任务。具体而言,我们构建了分层树状结构的时序检索底座ChronoRAG Base(CRB),用于大规模时序数据存储与域感知检索;提出多粒度序列交互学习器(MSIL),以提取细粒度和粗粒度的关联特征;设计双分支模型协同融合器(MCC),将检索到的知识与两类TSPMs(基于非大语言模型的TSPM和基于大语言模型的TSPM)进行对齐。 与现有基准模型相比,以基于非大语言模型的TSPM和基于大语言模型的TSPM分别作为基础模型时,QuiZSF在75%和87.5%的预测场景中均排名第一,同时在内存占用和推理速度方面保持了较高效率。
PART 1:研究背景与意义
一、零样本时间序列预测(ZSF)的核心价值
-
应用场景:适配数据稀缺场景,如跨域预测(电力→气象)、极端条件预测(极端天气、突发疫情),解决传统模型“无监督/微调难”的痛点。
-
现实意义:无需目标域训练数据,仅通过已有模式推理新时序趋势,为动态系统决策(如能源调度、健康监测)提供可靠支持。
二、现有技术的局限
|
技术类型 |
核心问题 |
|
时序预训练模型(TSPM) |
1. 无法动态更新知识,微调成本高,破坏零样本“即插即用”特性;2. 未利用时序数据的结构相似性(跨域/域内相似模式) |
|
检索增强生成(RAG) |
虽能按需注入外部知识,但未与TSPM有效融合,缺乏针对时序数据的存储、检索及特征交互设计 |
三、研究意义
首次将RAG与TSPM深度结合,提出QuiZSF框架,解决ZSF中“知识动态更新”与“相似模式利用”两大核心问题,在提升预测精度的同时保持高效性,为数据稀缺场景的时序预测提供新范式。
PART 2:当前研究综述
一、时序预训练模型(TSPM)分类与局限
|
类型 |
代表模型 |
优势 |
局限 |
|
Non-LLM based TSPM |
TTM、TimesFM、Moirai |
专注时序特征,轻量化,零样本泛化较好 |
无法动态整合外部知识,跨域适配性有限 |
|
LLM based TSPM |
Time-LLM、LLMTime、GPT4TS |
利用LLM跨域迁移能力,支持文本交互 |
模态鸿沟(数值→文本),未利用时序结构相似性 |
二、检索增强生成(RAG)相关工作
-
核心思路:通过检索外部知识增强模型输出,已成功应用于NLP(如开放域问答)。
-
时序领域现状:部分研究尝试引入检索机制,但存在缺陷:1. 存储检索效率低,不支持大规模时序数据;2. 未建模目标与检索序列的交互特征;3. 无法适配两类TSPM的模态需求。
三、研究缺口
现有工作未实现“RAG的动态知识注入”与“TSPM的时序建模能力”的有效协同,缺乏针对ZSF的端到端数据-模型交互框架。
PART 3:研究现存挑战
一、高效域敏感的存储与检索
海量时序数据(百万级序列)需快速检索,且需兼顾域内精准匹配与跨域泛化,传统线性存储检索效率低,缺乏域感知能力。
二、多粒度特征提取
-
检索序列来自不同域、尺度、噪声水平,简单拼接/平均会导致异质性干扰,需提取“细粒度依赖”与“粗粒度趋势”的多层面交互特征。
三、模态对齐的表征融合
-
TSPM分为数值型(Non-LLM)和文本型(LLM),需设计统一适配器:1. 数值型需无缝融合检索特征;2. 文本型需将数值特征转化为结构化文本提示,同时支持端到端优化。
PART 4:文章的主旨与主要内容
一、核心主旨
提出QuiZSF(Quick Zero-Shot Time Series Forecaster)——轻量模块化框架,通过“检索增强+特征交互+模态融合”,将RAG与TSPM结合,提升零样本时间序列预测的精度与效率。
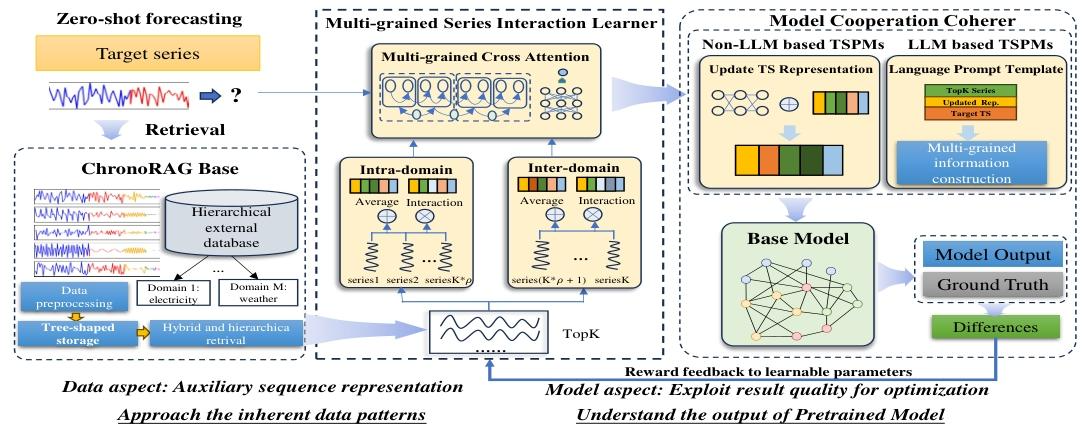
二、主要内容(三大核心组件)
-
ChronoRAG Base(CRB):构建分层树结构时序数据库,支持高效域敏感检索,存储27个数据集(7大域),提供Small/Medium/Large三个版本。
-
Multi-grained Series Interaction Learner(MSIL):提取检索序列与目标序列的细粒度交互特征和粗粒度平均趋势,通过跨注意力融合为统一表征。
-
Model Cooperation Coherer(MCC):双分支适配器,分别适配Non-LLM(残差融合)与LLM(结构化提示转化),结合MMD正则化对齐预测分布。
三、核心逻辑
检索相似时序→多粒度特征交互→模态对齐融合→零样本预测,全程保持“即插即用”特性,无需目标域微调。
PART 5:文章的创新点
创新点1:分层时序检索底座(CRB)与HHTR策略
-
CRB:采用“域划分→k-means聚类”的分层树结构,统一数据协议(滑动窗口、线性插值、ARROW存储),支持动态更新与高效索引。
-
HHTR策略:混合“域内局部匹配”与“全局原型匹配”,通过余弦相似度+欧氏距离复合度量,平衡检索精度与泛化性。
创新点2:多粒度序列交互学习(MSIL)
-
同时建模“交互模式”(元素积+非线性投影,捕捉细粒度依赖)与“平均模式”(均值池化+转化,编码全局趋势)。
-
通过跨注意力将两种模式与目标序列融合,解决异质性序列的特征整合问题。
创新点3:双分支模态协同融合(MCC)
-
数值分支:残差连接融合MSIL特征与目标序列,适配Non-LLM的数值输入需求。
-
文本分支:将MSIL特征转化为结构化提示(含域内/跨域模式总结),适配LLM的文本输入需求。
-
引入MMD正则化,对齐预测与真实序列分布,减少幻觉。
PART 6:技术路线和实验程序
一、技术路线(端到端流程)
-
检索阶段:输入目标序列→CRB通过HHTR策略检索Top-K相似序列(域内占比ρ=60%)。
-
特征交互阶段:目标序列+检索序列→MSIL归一化→提取交互/平均模式→跨注意力融合生成R_fused。
-
模态融合阶段:
-
Non-LLM:R_fused与目标序列残差融合→输入TSPM预测。
-
LLM:R_fused转化为结构化提示→输入TSPM预测。
-
-
优化阶段:MSE损失+MMD正则化→反向更新参数。
二、实验程序
|
类别 |
细节 |
|
数据集 |
1. 检索库(CRB):7大域27个数据集,分Small(34M点)/Medium(48M点)/Large(143M点);<br>2. 测试集:ETTh1/2、ETTm1/2、Weather |
|
基线模型 |
13个SOTA模型,分三类:<br>- Non-LLM TSPM(TTM、Moirai等);<br>- LLM TSPM(Time-LLM、GPT4TS等);<br>- 其他架构(iTransformer、DLinear等) |
|
实验设置 |
1. QuiZSF_T(Non-LLM):多源泛化ZSF(训练多源数据,零样本迁移到测试集);<br>2. QuiZSF_L(LLM):单源迁移ZSF(训练单源数据,跨域迁移) |
|
评估指标 |
均方误差(MSE),最优结果加粗,次优下划线 |
PART 7:实验结果与讨论
一、核心性能结果
|
模型设置 |
关键结论 |
|
QuiZSF_T(Non-LLM) |
在75%的ZSF场景中Top1,平均MSE优于所有零样本基线,甚至超越部分全样本模型(如FEDformer);Weather跨域测试表现最优 |
|
QuiZSF_L(LLM) |
在87.5%的ZSF场景中Top1,8个跨域迁移设置中7个最优,显著优于Time-LLM、GPT4TS等 |
二、消融实验(验证组件有效性)
|
消融变体 |
ETTm1→ETTh2(MSE) |
ETTm1→ETTm2(MSE) |
结论 |
|
QuiZSF_L -w/o-RAG |
0.394 |
0.296 |
移除RAG性能下降3.14%-5.34%,检索是ZSF的核心增益来源 |
|
QuiZSF_L -w/o-MSIL |
0.387 |
0.286 |
简单平均替代MSIL导致性能下降,多粒度交互特征不可或缺 |
|
QuiZSF_L -w/o-Coherer |
0.388 |
0.289 |
缺乏结构化提示转化,LLM无法有效利用数值特征,性能下降约2% |
三、关键分析
-
复杂度:QuiZSF轻量化,模型大小与推理时间接近TTM,检索与交互模块开销极小。
-
超参数:最优配置为CRB-Medium、Top-K=8、ρ=60%,平衡精度与效率。
-
案例研究:RAG可平滑预测曲线,减少LLM的时序幻觉(ETTh2数据集MSE从0.479降至0.351)。
PPT 8:文章结论
一、核心结论
-
框架有效性:QuiZSF通过RAG与TSPM的深度融合,在零样本时序预测中实现SOTA性能,Non-LLM版本75%场景Top1,LLM版本87.5%场景Top1,且保持高效性。
-
组件价值:CRB解决高效检索问题,MSIL提取多粒度交互特征,MCC实现模态对齐,三者协同突破ZSF核心瓶颈。
-
泛化能力:在跨域(Weather)、细粒度(ETTm1)场景均表现优异,验证了框架的鲁棒性。
二、未来工作
-
开发更鲁棒的域专属TSPM,提升极端稀缺数据场景的性能。
-
优化检索库的稀疏连接,降低大规模检索的复杂度。
-
探索跨粒度时序学习方法,解决不同采样粒度的模式迁移问题。
三、核心贡献
为零样本时间序列预测提供了“数据-模型交互”的高效框架,首次验证了RAG与TSPM融合的可行性,为数据稀缺场景的时序预测提供新思路。

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐
 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)