




- @levy_cui
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
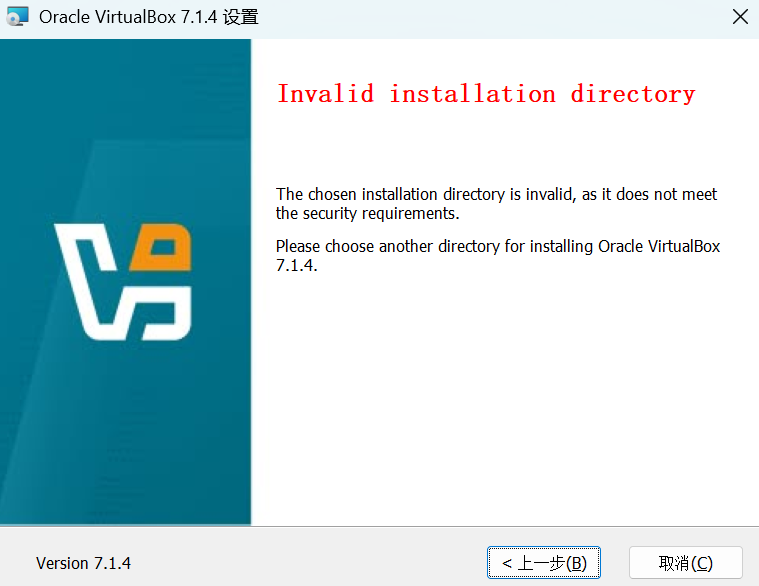
将需要安装VirtualBox的目录下创建个目录。将VirtualBox安装在D盘。VirtualBox7.1.4下载。使用cmd(使用超级管理员)
一、网页标题及logo修改1、网页标题修改vi /root/anaconda3/envs/super/lib/python3.6/site-packages/superset/views/core.pyreturn self.render_template('superset/basic.html',entry='welcome',title='Superset',bootstrap_data=j
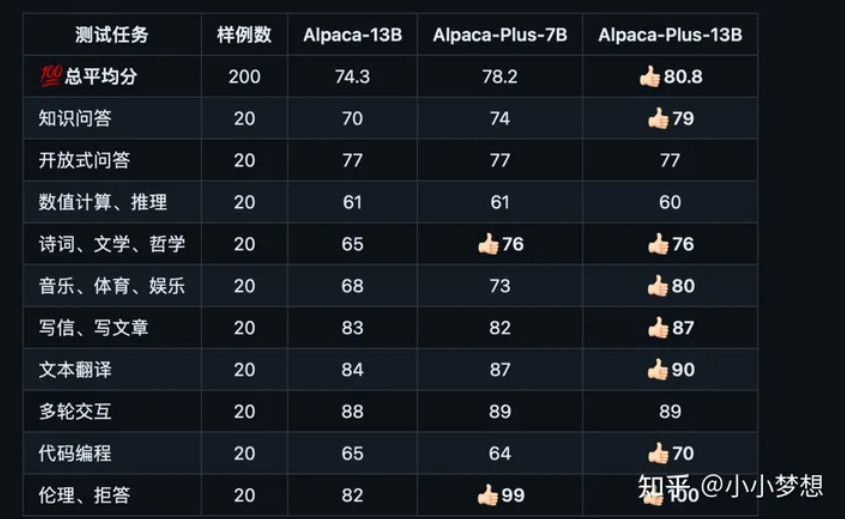
想要全面且准确的测出一个大模型的能力且让所有人认可、达成共识,这件事本身具有非常大的难度,如今大模型的发展不同以往,传统的NLP榜单,不论是测评的能力项还是具体测评case都难以满足,为此必定要构建新的测评集,这个难度正如前面所说很大,还有一条路就是不构建测试集而是公测,让所有人来随机测,各种提问,但是这种方式对于开发者来说迭代周期长,且各个模型之间也难以量化对比。每一个测评集都不一样,进而导致了
随着 ChatGPT 等大型语言模型 (LLM)的兴起,人们慢慢发现,怎么样向 LLM 提问、以什么技巧提问,是获得更加准确的回答的关键,也由此产生了提示工程这个全新的领域。提示工程(prompt engineering)是一门相对较新的领域,用于开发和优化提示以有效地将语言模型 (LM) 用于各种应用程序和研究主题。即时的工程技能有助于更好地理解LLM的功能和局限性。研究人员使用提示工程来提高

开始。这是最容易令人丧失斗志的两个字。迈出第一步通常最艰难。当可以选择的方向太多时,就更让人两腿发软了。从哪里开始?本文旨在通过七个步骤,使用全部免费的线上资料,帮助新人获取最基本的 Python 机器学习知识,直至成为博学的机器学习实践者。这篇概述的主要目的是带领读者接触众多免费的学习资源。这些资源有很多,但哪些是最好的?哪些相互补充?怎样的学习顺序才最好?我假定本文的读
不建议在一台服务上安装多个数据库,可以在一个数据库中应用多个实例。需求在一台服务器上部署两台MYSQL库,默认是3306端口,第二库使用3307端口netstat -tlnap | grep mysqlps -ef| grep mysql部署前:[root@server01 mysql3307]# ps -ef|grep mysqlroot 58995 49022 0 ...
想要全面且准确的测出一个大模型的能力且让所有人认可、达成共识,这件事本身具有非常大的难度,如今大模型的发展不同以往,传统的NLP榜单,不论是测评的能力项还是具体测评case都难以满足,为此必定要构建新的测评集,这个难度正如前面所说很大,还有一条路就是不构建测试集而是公测,让所有人来随机测,各种提问,但是这种方式对于开发者来说迭代周期长,且各个模型之间也难以量化对比。每一个测评集都不一样,进而导致了
想要全面且准确的测出一个大模型的能力且让所有人认可、达成共识,这件事本身具有非常大的难度,如今大模型的发展不同以往,传统的NLP榜单,不论是测评的能力项还是具体测评case都难以满足,为此必定要构建新的测评集,这个难度正如前面所说很大,还有一条路就是不构建测试集而是公测,让所有人来随机测,各种提问,但是这种方式对于开发者来说迭代周期长,且各个模型之间也难以量化对比。每一个测评集都不一样,进而导致了
下文是计算机领域的学术会议等级排名情况,分为A+, A, B, C, L 共5个档次。其中A+属于顶级会议,基本是这个领域全世界大牛们参与和关注最多的会议。国内的研究者能在其中发表论文的话,是很值得骄傲的成就。A类也是非常好的会议了,尤其是一些热门的研究方向,A类的会议投稿多录用率低,部分A类会议影响力逐步逼近A+类会议。B类的会议分两种,一种称为盛会级,参与的人多,发表的论文也多,论文录
一、域控可以正常工作1、删除辅助域控:单击“开始”,单击“运行”,然后键入以下命令: dcpromo /forceremoval然后按提示操作。2、删除主域控:1)打开Active Directory 用户和计算机 ->Domain Controllers,右键点击所要删除的辅助域控,在菜单上选择删除.确定删除 这台域控制器永远为脱机并且不再能用,运行Active Dire