- @leviopku
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
基于TensorFlow可以轻而易举搭建一个神经网络,而且很好地支持GPU加速训练。但基于TensorFlow的预测过程,往往需要在嵌入式设备上才能得以应用。对于我目前做的工作而言,用TF搭建神经网络以及用GPU加速训练过程的主要用处就是:获取训练后的参数(权重和偏置),将这些参数直接放到嵌入式板卡如FPGA中,以其低功耗、高性能、低延时等特点完成嵌入式AI工程。那么,提取出TF训练后的参数变成很
我在用Ubuntu20.04源码编译安装COLMAP时,遇到了一个报错如上。Log显示GPU架构没被认出来。参考来自:https://github.com/colmap/colmap/issues/1944。
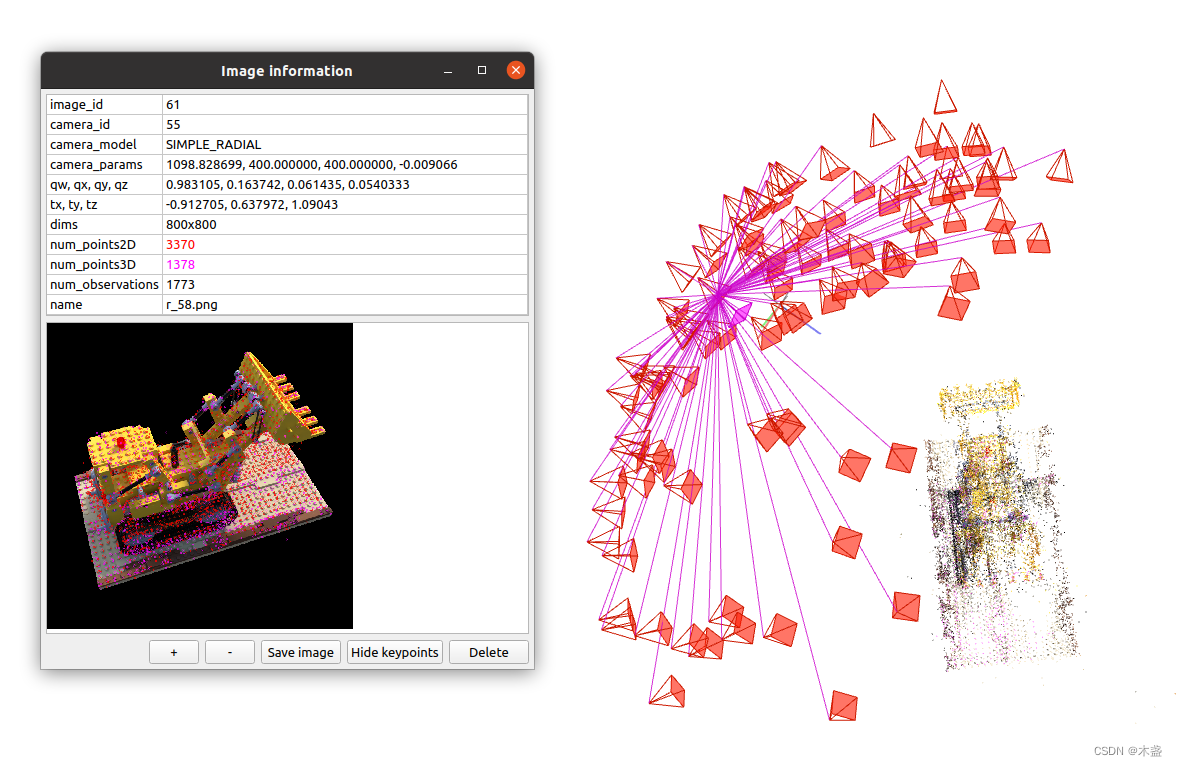
这篇博文主要介绍多视角三维重建的实用工具COLMAP。为了让读者更快确定此文是否为自己想找的内容,我先用简单几句话来描述此文做的事情: 假设我们针对一个物体(人)采集了多个(假设60个)视角的照片,希望用COLMAP实现:(1)通过不同视角之间的特征匹配算出每个视角的相机位资(内外参);(2) 对物体进行初步的稀疏重建,完成多视角数据的可视化(详见图3)。
github有时候git clone太慢了,用国内镜像的话就可以大大加速。我目前发现2个镜像网站:https://hub.fastgit.orghttps://github.com.cnpmjs.org目前测评来看,第一个镜像比较稳定,速度也快。使用方法:将git clone https://github.com/xxx/xxx.git改成git clone https://hub.fastgit
GradCAM是经典的特征图可视化工具,在CV任务中,能用于分析CNN学到了什么东西。先看一张图:这就是GradCAM做出的效果,它直观地表示出咱们模型认为图片是Dog的是依据哪些地方。GradCAM借用梯度来进行注意力表示,发表于ICCV2017,如今依然活跃在学术和工程界。GradCAM原理对于视觉任务,包括图像分类、目标检测等,通常都是backbone+head的形式。如图1所示。所以,Gr
适定问题(well-posed problem)和不适定问题(ill-posed problem)都是数学领域的术语。前者需满足三个条件,若有一个不满足则称为"ill-posed problem":1. a solution exists解必须存在2. the solution is unique解必须唯一3. the solution's be...
写论文的时候需要画神经网络的结构图,用PPT和VISIO之类的工具画效率会比较低。本文将介绍2种基于网页的神经网络画图工具,让结构图更加酷炫。1. NN-SVG这个工具有三种画图风格:FCNN、LeNet、AlexNet。网页链接为:http://alexlenail.me/NN-SVG/只需选择一种喜欢的风格,然后在左侧配置栏里填入自己网络的详细参数,就可以实现自动画图...
抽个空整理下CV相关的会议截稿时间和举办时间。对于想投论文的萌新而言,这个一定很有用处。持续更新,欢迎收藏。收录会议包括:CVPR, ICCV, ECCV, SIGGRAPH, IJCAI, ICML, ICLR, NIPS, MM, AAAI, BMVC, ICIP, ACCV会议截稿时间举办时间CCF等级地点备注主页IJCAI...
openAI的图文多模态模型CLIP证明了图文多模态在多个领域都具有着巨大潜力,随之而来掀起了一股图文对比学习的风潮。就在前几天(2022年12月),连Kaiming都入手这一领域,将MAE的思路与CLIP的思路结合,推出了FLIP,有兴趣可戳(https://arxiv.org/abs/2212.00794)。对于迷茫的CV研究生,如果你找不到研究方向,just follow Kaiming绝对
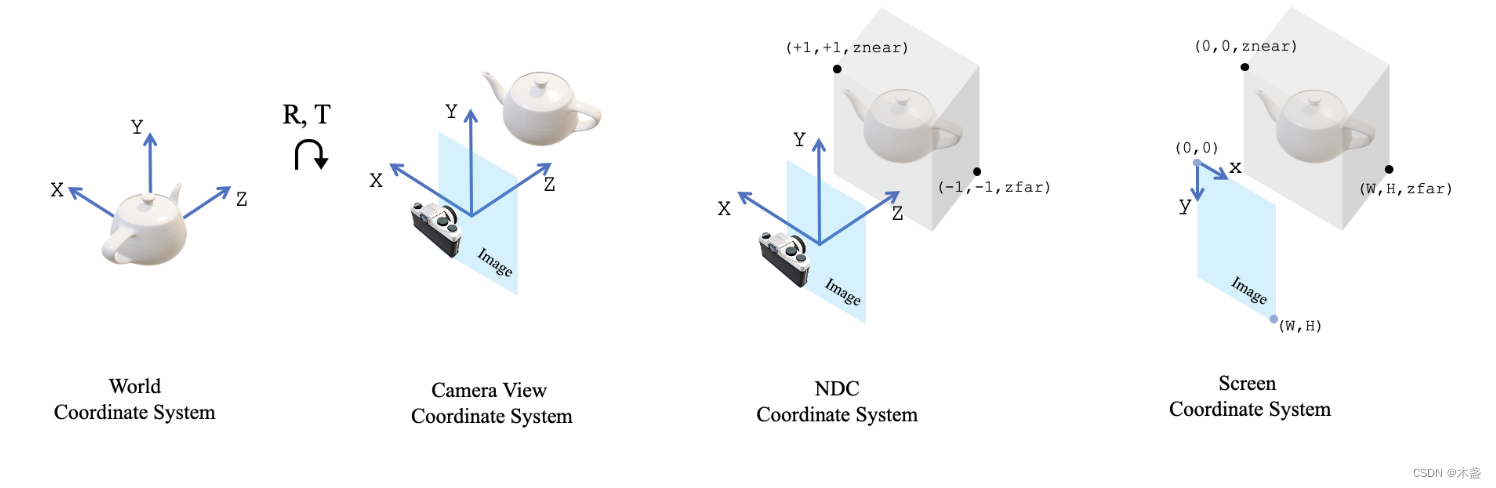
三维视觉中,需要掌握四种坐标系:世界坐标系、相机视角坐标系、NDC坐标系、屏幕坐标系。