




- @level_Tiller
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了如何修改MySQL数据表的字符集和排序规则,并转换已有数据。首先,使用ALTER TABLE语句将表的默认字符集和排序规则修改为utf8mb4和utf8mb4_unicode_ci。接着,通过查询information_schema.COLUMNS表,动态生成修改表中所有字段字符集和排序规则的SQL语句。生成的SQL语句可以批量执行,确保表中所有相关字段的字符集和排序规则一致。此方法适用
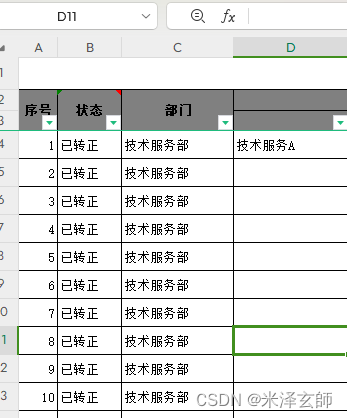
如果表格太长,长过有效单元格,你只想填充到有效的单元格,可以使用到“D4单元格所在列最后的你要批量替换的单元格的位置ctrl+shift+↑选中D4单元格所在列然后使用ctrl+D批量填充公式”的方式,如图。接下来复制公式到整个D列,可使用快捷键ctrl+shift+↓选中D4单元格所在列然后使用ctrl+D批量填充公式。我这应该是网上的贴子上对此总结的最有实用价值的吧,哈哈。比如,现在的需求是将
<div class="clearfix"><a-uploadlist-type="picture-card":file-list="fileList"@preview="handlePreview"@change="handleChange":before-upload="beforeUpload":headers="headers"name="fileData"#传递的.
页面配置数据字典product_type后端@Dict(dicCode = "product_type")private String type;前端<j-dict-select-tag v-decorator="['type', validatorRules.type]" placeholder="请选择商品类型" dictCode="product_type":trigger-chang
步骤:项目准备1.下载一个干净的springboot项目,没有多余的依赖https://github.com/wangzixi-diablo/mySpringBoot2.进入项目文件夹,运行mvn spring-boot:run查看运行结果,端口可在application.properties中修改2021-04-27 11:54:55.346INFO 128114 --- [main] s.b.
用了整整三天.QAQ.靠体力一下下试出来的结果.踩了个坑.一开始,项目的覆盖率显示的是0,单元测试数也没有显示.首先,想到的是test中的项目包结构目录的问题.倒不是一定是全的,需要的包的路径结构要完整.于是调整了test中的包结构,把测试class的命名改为了(原java)Test项目用的是testng.不知道为啥,junit的我没运行出来单元测试数.在工程目录,右击选择run with cov
监控一个文件实时采集新增的数据输出到控制台Agent选型: exec source +memory channel + logger sink文章目录监控一个文件实时采集新增的数据输出到控制台(1)在/home/hadoop/data目录下新建data.log文件(2)到$FLUME_HOME/conf目录下创建配置文件exec-memory-logger.conf(3)启动agent(4)通过往
标题:vmware虚拟机ubuntu20.04resolv.conf文件失效目的:重启虚拟机网络配置resolv.conf不变且有效解决方法:发现/etc下的resolv.conf文件报红,且resolv.conf文件失效查看/etc/resolv.conf这个文件的注释,发现开头就写着这么一行:# Dynamic resolv.conf(5) file for glibc resolver(3)
标题:vmware虚拟机ubuntu20.04网络网卡检测失败,ifconfig的ip错误,且网络连接不了。因为操作sstap,我心爱的无线网卷着图标和网连夜跑了,最终仍未追回,但是万幸连上网了。可以看出,我的第二网卡没有检测出来。root@jitsi:/home/ubuntu/Desktop# ifconfiglo: flags=73<UP,LOOPBACK,RUNNING>mtu
用了整整三天.QAQ.靠体力一下下试出来的结果.踩了个坑.一开始,项目的覆盖率显示的是0,单元测试数也没有显示.首先,想到的是test中的项目包结构目录的问题.倒不是一定是全的,需要的包的路径结构要完整.于是调整了test中的包结构,把测试class的命名改为了(原java)Test项目用的是testng.不知道为啥,junit的我没运行出来单元测试数.在工程目录,右击选择run with cov