- @kkm09
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
卷积神经网络(Convolution Neural Network)是一种神经网络的架构设计,专门用于影像处理上。本文从神经元版本和卷积核版本对卷积层进行介绍,随后介绍池化层及其作用——把图像变小的同时保留其重要特征。最后举例一个CNN的应用场景:Alpha GO 下围棋。
无论是预测视频观看人数还是图像处理,输入都可以看作是一个向量,输出是一个数值或类别。然而,若输入是一系列向量(序列),同时长度会改变,例如把句子里的单词都描述为向量,那么模型的输入就是一个向量集合,并且每个向量的大小都不一样:将单词表示为向量的方法:One-hot Encoding(独热编码)。向量的长度就是世界上所有词汇的数目,用不同位的1(其余位置为0)表示一个词汇,如下所示:但是它并不能区分

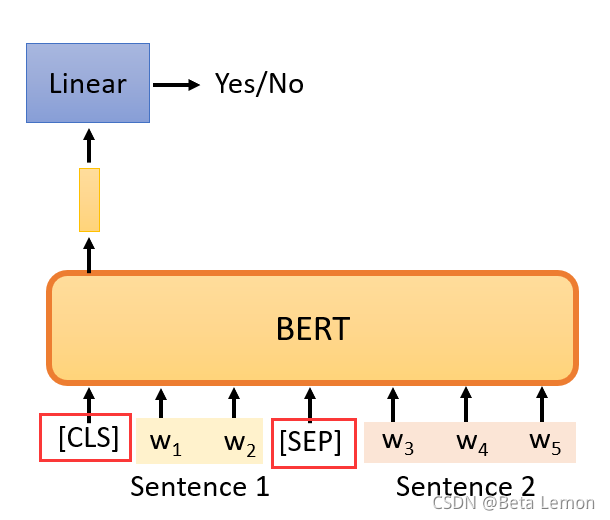
在监督学习中,模型的输入为x,若期望输出是y,则在训练的时候需要给模型的期望输出y以判断其误差——有输入和输出标签才能训练监督学习的模型。自监督学习在没有标注的训练集中,把训练集分为两部分,一个作为输入,另一个作为模型的标签。自监督学习是一种无监督学习的方法。BERT 是 Transformer 的编码器(Encoder),一般用于NLP中(也可用于图像、语音处理中),它的输入是一排文字,输出是等
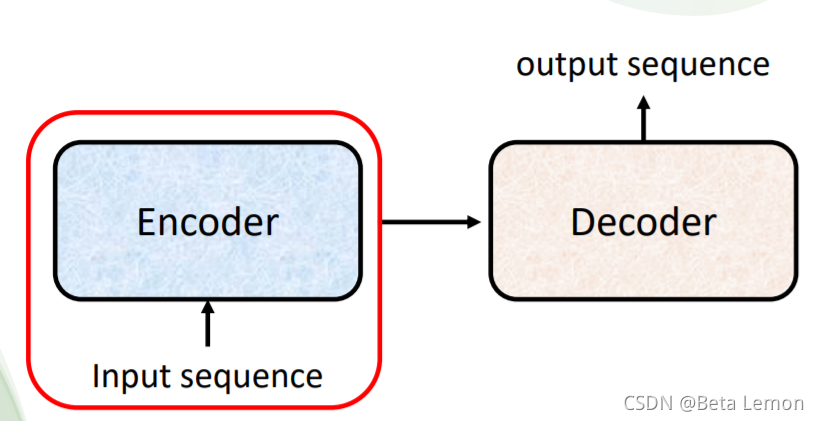
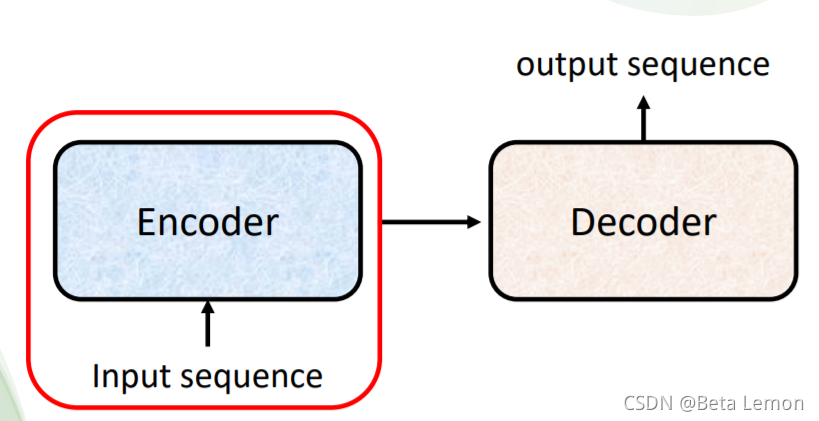
输入一个序列,输出长度由模型决定。例如语音识别,输入的语音信号就是一串向量,输出就是语音信号对应的文字。但是语音信号的长度和输出的文字个数并无直接联系,因此需要机器自行决定:对于世界上没有文字的语言,我们可以对其直接做语音翻译。另外,Seq2seq 还可以用来训练聊天机器人:输入输出都是文字(向量序列),训练集示例如下图:各式各样的NLP问题,往往都可以看作QA问题,例如问答系统(QA),让机器读
无论是预测视频观看人数还是图像处理,输入都可以看作是一个向量,输出是一个数值或类别。然而,若输入是一系列向量(序列),同时长度会改变,例如把句子里的单词都描述为向量,那么模型的输入就是一个向量集合,并且每个向量的大小都不一样:将单词表示为向量的方法:One-hot Encoding(独热编码)。向量的长度就是世界上所有词汇的数目,用不同位的1(其余位置为0)表示一个词汇,如下所示:但是它并不能区分
在监督学习中,模型的输入为x,若期望输出是y,则在训练的时候需要给模型的期望输出y以判断其误差——有输入和输出标签才能训练监督学习的模型。自监督学习在没有标注的训练集中,把训练集分为两部分,一个作为输入,另一个作为模型的标签。自监督学习是一种无监督学习的方法。BERT 是 Transformer 的编码器(Encoder),一般用于NLP中(也可用于图像、语音处理中),它的输入是一排文字,输出是等
输入一个序列,输出长度由模型决定。例如语音识别,输入的语音信号就是一串向量,输出就是语音信号对应的文字。但是语音信号的长度和输出的文字个数并无直接联系,因此需要机器自行决定:对于世界上没有文字的语言,我们可以对其直接做语音翻译。另外,Seq2seq 还可以用来训练聊天机器人:输入输出都是文字(向量序列),训练集示例如下图:各式各样的NLP问题,往往都可以看作QA问题,例如问答系统(QA),让机器读